****************************************************************************************************************************************************************************************************
Izvorni tekstovi programa:
Izvršni kod programa:
1. Duplicirane regije slika
1. Otkrivanje
dupliciranih regija slike
2. Otkrivanje steganografskih poruka
3. Razlikovanje fotorealističnih slika od
fotografija
*****************************************************************************************************************************************************************************************************
1.
Uvod
Nakon Drugog svjetskog rata, računala su polako ali neizbježno postala baze podataka ljudskih aktivnosti. Ovaj se trend ubrzao razvojem osobnih računala, Interneta, kao i konvergencijom računarstva, telekomunikacija te multimedije. Današnji svijet umreženih digitalnih uređaja pruža mogućnosti i izazove za kriminalce i istražitelje, vlade, institucije, poslovanje, komunikaciju kao i za korisnike svjesne važnosti očuvanja privatnosti. Živimo u digitalnom svijetu gdje se većina informacija stvara, presreće, odašilje, čuva i procesira u digitalnom obliku. Digitalne informacije utječu i koriste se u svakom aspektu života. Iako korištenje podataka u digitalnom obliku donosi mnoge tehnološke i ekonomske prednosti, dovelo je do mnogih problema i izazova prilikom izvođenja forenzičke analize digitalnih dokaza. Ti izazovi proizlaze iz sljedećih činjenica:
·
Digitalni podatak apstraktna je
reprezentacija informacije. Predstavlja samo sekvencu bitova i ne posjeduje neka očita svojstva koja bi
ukazala na autentičnost ili porijeklo informacija.
·
Na tržištu postoje razne kolekcije uređaja
koji se koriste za stvaranje i pohranu digitalnih informacija, uključujući
kamere, audio snimače,osobne digitalne pomoćnike, mobilne telefone i računala.
Akvizicija i dohvat podataka iz tih uređaja može biti veoma zahtjevna zadaća, a
ukoliko su podatci skriveni, fragmentirani
ili kriptirani, postaje još teža.
·
Ako uzmemo u obzir relativno niske cijene
medija za pohranu podataka, količina podataka s kojom se istražitelj susreće
veoma je velika. Pregled velikih količina podataka zahtjevan je posao koji
oduzima previše vremena.
·
Digitalni dokazi često putuju raznim
kanalima, te su često raštrkani na nekoliko
uređaja, u nekoliko različitih formata, što njihovu analizu i slaganje u
smislenu cjelinu čini veoma teškim.
·
Digitalni podatci lako se brišu,
modificiraju, prepravljaju, kriptiraju, uz
korištenje pregršt lako dostupnih antiforenzičkih alata.
·
Digitalni podatci mogu biti ranjivi, te često
zahtijevaju brzo prikupljanje i obradu
Kao odgovor na gore navedene izazove razvijene su znanstvene metode za rekonstrukciju i dohvat dokaza iz digitalnih podataka a potom i njihovu analizu. Te se metode mogu svrstati pod zajedničkim imenom digitalna forenzika. Digitalna forenzika može se definirati kao skup znanstvenih metoda za očuvanje, sakupljanje, validaciju, identifikaciju, analizu, interpretaciju, dokumentaciju i prezentaciju digitalnih dokaza proizašlih iz digitalnih izvora, s ciljem potvrđivanja ili pomoći pri rekonstrukciji događaja, često kriminalne prirode.
Digitalna forenzika mlada je disciplina koja se ubrzano mijenja i evoluira, pokušavajući držati korak s napretkom tehnologije i razvojem novih softvera. Posuđujući principe koji su se pokazali valjanima u fizičkom svijetu, suočava se sa izazovima jedinstvenim u domeni digitalnog svijeta.
2. Forenzika
Forenzika je proces
korištenja znanstvenih metoda pri sakupljanju, analizi i prezentaciji dokaza na
sudu. Značenje
riječi forenzika dolazi od latinske
riječi forensis, što znači “iznositi
sudu” ili “na forumu”. U starom bi
Rimu kriminalno optuživanje značilo prezentiranje slučaja pred grupom javnih
osoba na forumu. Optuženik i tužitelj javnim bi govorom pokušali uvjeriti ljude
kako je njihova verzija događaja istinita. Forenzika se primarno bavi s pronalaskom i analizom latentnih dokaza. U latentne
dokaze mogu se svrstati mnoge kategorije
dokaza; od otisaka prstiju ostavljenih na prozoru do DNA dokaza sakupljenih s
mjesta zločina. Forenzika se koristi znanstvenim metodama i saznanjima, koje u
kombinaciji sa standardima zakona koristi pri pronalasku i prezentaciji dokaza
važnih za određenu istragu. Polje forenzike razvijalo se kroz mnoga stoljeća.
Najraniji zapis korištenja forenzičkih metoda datira iz 1248. godine, kada je kineski liječnik Hi Duan Yu
napisao priručnik pod imenom „The washing
away of wrongs“ u kojem je iznio
medicinsko i anatomsko znanje toga vremena u korelaciji s zakonima.
Identifikacija pomoću otisaka prstiju počela se koristiti tek 1892.
godine, a prvi je forenzički laboratorij osnovan u SAD-u 1930. godine.
Iako se forenzika razvila u dobro dokumentirano i disciplinirano polje
proučavanja sa mnogo razina certifikacije, ona se stalno mijenja. Tehničkim dostignućima te širenjem i
napretkom znanstvenih metoda i saznanja,
mijenjaju se i procesi i alati korišteni
u forenzici.
Iako se forenzika razvijala tijekom 800 godina, uvijek će na neki način
zaostajati za naprecima u znanosti. Kao primjer možemo uzeti uvođenje DNA kao
dokaza na sudove – tipiziranje DNA koristilo se je u razne svrhe još
osamdesetih godina dvadesetog stoljeća, no na sudovima se počela priznavati kao
valjani dokaz tek u devedesetim godinama dvadesetog stoljeća.
Uzimajući u obzir kako se moderna forenzika razvijala otprilike šezdeset godina aktivnom primjenom u istragama, te 800 godina kao disciplina, specijalizirano polje računalne forenzike , u usporedbi je veoma mlado, stoga ne čudi kako postoji veoma malo standardizacije i konzistencije prilikom prihvaćanja i korištenja digitalnih dokaza u raznim institucijama. Krajnji je rezultat navedenih činjenica taj kako računalna forenzika još uvijek nije priznata kao formalno znanstvena disciplina.
2.1
Digitalna
forenzika
Digitalnu forenziku čine metode prikupljanja, analize i prezentacije dokaza koji se mogu pronaći na računalima, poslužiteljima, računalnim mrežama, bazama podataka, mobilnim uređajima, te svim ostalim elektroničkim uređajima na kojima je moguće pohraniti podatke. Takvi dokazi mogu biti korisni u kaznenim postupcima i procesima pred sudovima, građanskim parnicama te postupcima unutar korporacija u okviru upravljanja ljudskim resursima, odnosno postupcima kod procesa zapošljavanja i otpuštanja zaposlenika. Važno je da pritom ništa od opreme ili procedura korištenih prilikom istrage računala ne unište ili promijene podatke na istraživanom uređaju.
Računalni sustavi sadržavaju značajne količine podataka koji se mogu iskoristiti kao dokazni materijal. Ukloniti takav dokaz je također daleko teže nego što se uobičajeno misli. Metodama digitalne forenzike moguće je pronaći takav dokazni materijal te obrisane ili izgubljene podatke čak, i u slučaju namjernog brisanja.
Digitalna se forenzika u prijašnjim vremenima bavila isključivo s postojanim podatcima (eng. Persistent data), odnosno podatcima koji su sačuvani na lokalnom tvrdom disku ili nekom drugom mediju, te ostaju na njemu i kada je uređaj ugašen. U današnje doba umreženosti prikupljanje, pregled i analiza nepostojanih, ranjivih podataka (eng. Volatile data) postaje sve važnije. Nepostojanim, ranjivim podatkom nazivamo one podatke koji su pohranjeni u memoriji ili u tranzitu, i koji će biti izgubljeni kada se uređaj ugasi. Nepostojani podatci nalaze se u registrima, cache memoriji, radnoj memoriji, te se zbog njihove prirode prikupljanje tih podataka mora odvijati u stvarnom vremenu.
Brzom ekspanzijom interneta, te uvođenjem zakona koji terete korporacije odgovorne za kompromitiranje sigurnosti ili integriteta računalnih mreža sve se više IT buđeta ulaže u softvere za zaštitu sustava kao što su sustavi za otkrivanje napada (eng. intrusion detection systems, kratica IDS), zaštitne stijene, proxy poslužitelji, itd...Oni daju uvid u sigurnosno stanje sustava u stvarnom vremenu, ili naknadnom analizom. Gotovo uvijek, kada se dogodi proboj u sigurnosnom sustavu ili korisnik dobije obavijesti o pokušaju proboja, potrebno je verifikacija kako bi se utvrdilo jeli obavijest bila krivo protumačena situacija, ili se zbilja dogodio nekakav sigurnosni incident, bio on proboj ili pokušaj proboja. Takva se verifikacija gotovo uvijek provodi na upaljenom računalu, analizom nepostojanih podataka. Administratori sustava, kao i osoblje zaduženo za sigurnost mora razumjeti načine na koje rutinski administrativni zadatci prikupljanja tih podataka mogu utjecati na forenzički proces i potencijalnu prihvatljivost informacija na sudu, kao i naknadnu mogućnost povratka podataka koji mogu biti ključni pri identifikaciji i analizi sigurnosnog incidenta.
Suprotno dojmovima koje dobivamo iz popularnih televizijskih serija, ne postoji ni približno dovoljno forenzičkih istražitelja slobodnih da se odazovu na svako mjesto zločina te prikupe, obrade i analiziraju dokaze. Kao rezultat toga nedostatka mnogi se djelatnici policije, te državnih agencija osposobe za prikupljanje dokaza kao što su otisci prstiju, vlakna, s mjesta zločina na forenzički prihvatljiv način. Kvalificirani istražitelj tada analizira dokaze te na temelju njih izvlači zaključke, s time da osoba koja je prikupila dokaze njih mora i autentificirati, a istražitelj svjedočiti o njihovoj važnosti. Ova je podjela poslova potrebna i u disciplini računalne forenzike. Administratori sustava često se prvi nađu na „mjestu zločina“, stoga je ključno da oni posjeduju tehničko znanje i sposobnosti da sačuvaju kritične informacije povezane s mogućim sigurnosnim incidentom na forenzički prihvatljiv način, te da su svjesni zakonskih regulativa prema kojima moraju prilagoditi svoje djelovanje.
Digitalna
forenzika postoji otkako se na računalima pohranjivalo podatke koji se mogu
koristiti kao dokazi. Mnogo godina digitalna
se forenzika povodila i koristila samo u
vladinim agencijama, no u posljednje vrijeme postala uobičajena praksa koja se
provodi i u komercijalnom sektoru. Većina je softvera za analizu originalno
izrađena za pojedine organizacije te bila u njihovom vlasništvu. U
današnje vrijeme postoje i alternativni
slobodno dostupni (eng. open source)
programi koji pružaju mogućnost
usporedbe rezultata analize.
2.1.1
Pravila
forenzike digitalnih sustava
- Prvo i osnovno pravilo digitalne forenzike je princip očuvanja - dokazi se ne smiju mijenjati niti na jedan način a originalni (izvorni) podaci i računalna oprema moraju biti očuvani po svaku cijenu. Naime, čak i uključivanje ili isključivanje uređaja može obrisati, uništiti ili učiniti teže dostupnim dokaze koji su na navedenim sustavima sadržani. Stoga bi potragu za dokazima trebao obavljati samo obučeni forenzičar koji će dokumentirati postupke i metode, zaštititi podatke i medije od prepisivanja, napraviti identične kopije, izvršiti njihovu analizu i prirediti analizu prema pravilima struke i u skladu sa zakonskom legislativom, prilagođenu krajnjem korisniku - naručitelju, policijskim istražiteljima, odvjetnicima strane koja je naručila analizu ili pak potencijalno suprotstavljenoj strani.
- Drugo pravilo digitalne forenzike je identifikacija potencijalnog dokaznog materijala. Radi se o tvrdim diskovima, disketama, Prijenosnim memorijama, Flash memorijskim karticama, datotečnim dnevnicima i svim ostalim uređajima koji mogu sadržavati dokaze. Pritom je važno napomenuti kako sami mediji ili podaci ne predstavljaju dokaz, nego su potencijalni izvor dokaza.
- Treće pravilo digitalne forenzike glasi da materijal koji je nedvojbeno identificiran kao relevantan za istragu mora biti snimljen na rezervne medije, ispisan ili na neki drugi način sačuvan od uništenja.
- Nadalje, pravilo interpretacije definira smjernice pri interpretaciji dobivenih rezultata koji moraju biti u sukladnosti s metodama koje koriste sve strane potencijalno uključene u analizu slučaja. Pritom se osobita pažnja mora posvetiti korištenju alata za automatsko pretraživanje dokaznog materijala i pravilno interpretiranje njihovih izlaznih rezultata.
- Univerzalno primjenjivo pravilo digitalne forenzike je predstavljeno dokumentiranjem lanca pristupa medijima, podacima i dokumentima na ispitivanom sustavu. Forenzički analitičar digitalnih sustava mora detaljno opisati sustave i aplikativnu podršku koju je analizirao, forenzičke alate koji su korišteni, prirodu pronađenih dokaza, ali također i detaljno zabilježiti kronološki tzv. vlasništvo nad informatičkom/računalnom imovinom te mogućnosti (opseg i vrijeme) pristupa. Time se pridonosi integritetu dokaznog materijala.
- Na rad forenzičara ispitivanog sustava primjenjuju se sva pravila koja vrijede za primjenu znanstvene metode, uključujući korištenje priznatih i dokazivih metoda koje može reproducirati nezavisni forenzičar i pritom duplicirati, odnosno reproducirati rezultate, potvrđujući ih.
7. Istražitelji
se u interpretaciju podatak trebaju upuštati samo ako su upoznati s područjem
kojim se bavi slučaj kako bi se spriječilo kompromitiranje istrage i dokaza [12].
Forenzičar digitalnih sustava u pravilu može pretraživati, analizirati, vraćati obrisane i podatke i manipulirati praktično svim datotekama sadržanim na istraživanom sustavu, financijske izvještaje i podatke, bilance, dnevnike pristupa, tablične kalkulacije, baze podataka, poruke elektroničke pošte, te multimedijalne datoteke poput zvučnih datoteka i filmova. Nadalje, temeljem podataka o korištenju datoteka i aplikacija, može rekonstruirati način korištenja uređaja ili računalnog sustava, dokazati kada i kako je uređaj korišten, što je korisnik pretraživao na Internetu te povratiti značajnu količinu podataka o tome što je je korisnik pisao ili čitao koristeći uređaj, odnosno što je vidio na ekranu računala.
2.2 Zakon i digitalna forenzika
Zakon ima presudan utjecaj na digitalnu forenziku jer ima stroga pravila o
prihvaćanju prikupljenih podataka kao dokaza. Zakoni nisu isti u svim državama, ali su im namjene i namjere jednake. Kako bi se prikupljene informacije uistinu tretirale kao dokazi mora se održati
visoka
razina formalnosti u postupanju sa računalom i njegovim
spremnicima,
te ostalim istraživanim uređajima.
Posebna briga prilikom pristupa podacima osumnjičenika mora se voditi, o virusima,
elektromagnetskim i mehaničkim oštećenjima, a
ponekad i o računalnim zamkama (eng. booby- traps).
U istragama kod kojih vlasnik digitalne opreme nije dao pristanak za
inspekciju, a to su krivične
istražne radnje, posebno se mora paziti da stručnjak za računalnu forenziku ima sve
dozvole i zakonski autoritet za pregledavanje, kopiranje, otuđivanje i
korištenje svih uređaja i njihovog sadržaja tj
posjeduje odgovarajući sudski nalog. Ako to nije slučaj,
osim odbacivanja dokaza na sudu, teško je očekivati izbjegavanje pravne tužbe.
Stvar na koju također treba paziti je osjetljivost informacija do
kojih se došlo pretragom, a koje nisu vezane za one podatke važne za istragu.
Kako je digitalna forenzika novija znanstvena disciplina, zakoni koji su
temelj za priznavanje elektroničkih dokaza na sudovima su još uvijek u stanju
nedorečenosti, a konstantan napredak tehnologije dovodi do većeg broja dokaza,
alata i konfuzije.
U nastavku su navedena dva zakona
Republike Hrvatske vezana uz prikupljanje digitalnih dokaza, te zapljenu
digitalnih uređaja [10].
2.2.1
Pretraga
i oduzimanje pohranjenih računala i podataka
Svaka stranka će usvojiti zakonske i druge
mjere potrebne kako bi njena nadležna tijela bila ovlaštena izvršiti pretragu
ili na sličan način imali pristup:
·
Računalnom
sustavu ili njegovom dijelu, kao i računalnim podacima pohranjenim u njima.
·
Mediju
za pohranu računalnih podataka u kojemu računalni podaci mogu biti pohranjeni
na državnom području stranke.
2.2.2
Prikupljanje
računalnih podataka u realnom vremenu
1. Svaka stranka će
usvojiti zakonske i druge mjere potrebne kako bi njena nadležna tijela bila
ovlaštena u realnom vremenu:
·
prikupiti
ili snimiti primjenom tehničkih sredstava na državnom području te stranke, te
·
primorati
davatelja usluga u okviru njegovih postojećih tehničkih mogućnosti da:
- prikupi ili snimi
primjenom tehničkih sredstava na državnom području te stranke ili
- surađuje i pomogne
nadležnim tijelima da prikupe i snime
podatke o prometu u vezi s određenim komunikacijama na svojem državnom području
prenesenima pomoću računalnog sustava.
2.
Kada
stranka zbog uspostavljenih načela svojega unutarnjeg pravnog sustava ne može
usvojiti mjere navedene u prvoj točki
stavka 1, ona može umjesto toga usvojiti zakonske i druge mjere potrebne
kako bi se osiguralo prikupljanje ili snimanje u realnom vremenu podataka o
prometu vezanih uz određene komunikacije na njenom državnom području primjenom
tehničkih sredstava na tom području.
- Svaka stranka će usvojiti zakonske i druge mjere potrebne kako bi se davatelja usluga obvezalo da čuvaju u tajnosti činjenicu da je iskorišteno neko od ovlaštenja propisano ovim člankom, kao i sve informacije o tome [10].
2.3
Prihvatljivost
digitalnih dokaza
Kako bi digitalni dokaz bio prihvaćen,
mora biti pouzdan i doprinositi istrazi. Pouzdanost znanstvenih dokaza kao što
su izlazne datoteke digitalnih forenzičkih alata određuje sudac.
Postoje
četiri općenite kategorije Daubertovog procesa koje se koriste prilikom
procjene procedure korištene za analizu dokaza
— Ispitivanje: može li
se procedura ispitati
—
Statistika
pogrešaka: postoji li procjena pogreške procedure
—
Objava:
je li procedura objavljena i podvrgnuta metodi
ocjenjivanja radova u znanstvenim
istraživanjima ili projektima (eng. peer
rewiew)
— Prihvatljivost: je li
procedura općenito prihvaćena u znanstvenoj zajednici
U nastavku
su podrobnije objašnjene procedure . Kako se trenutno većina alata digitalne
forenzike koristi prilikom pribavljanja podataka sa tvrdih diskova te analize
datotečnih sustava, pojašnjenja se
uglavnom odnosi na alate i procedure
kojima se kopira podatke s jedne jedince pohrane ne drugu, te izvlačenje
datoteka i podataka iz datotečnog sustava forenzičke kopije [11].
2.3.1
Ispitivanje
Procedura za
ispitivanje dokazuje nam može li se forenzička metoda ispitati, kako bi bilo
sigurno da su njeni rezultati točni i precizni. Nad rezultatima procedure
provode se dvije kategorije testova:
— lažno negativni i
— lažno pozitivni.
Lažno
negativni testovi potvrđuju prosljeđuje
li alat sve podatke s ulaza na izlaz. Na primjer, kada alat izlista sadržaj
direktorija, tada bi svi podatci trebali biti vidljivi.
Slično, ako
u alatu postoji mogućnost izlista izbrisanih imena datoteka, sve se moraju
prikazati. U digitalnoj forenzici ova se kategorija najviše ispituje na
alatima, jer je najjednostavnija; na sustav se postave poznati podatci, oni se
dobave, analiziraju, te se time potvrdi kako se svi podatci mogu pronaći.
Lažno
pozitivni testovi potvrđuju da alat ne uvodi nove podatke u svojim izlaznim
podatcima. Na primjer, kada alat ispiše sadržaj direktorija on ne dodaje nove
podatke. Ova se kategorija teže ispituje od prethodne. Najčešće se koristi
metoda preispitivanja izlaza alata nekim drugim alatom iste funkcionalnosti. Iako
se na ovaj način dolazi do dobrih rezultata postoji potreba formaliziranja
metodologije ispitivanja.
Pravilan
način ispitivanja forenzičkog alata provodi se korištenjem javno dostupne
metode. Potrebno je utvrditi kriterije koje svaki tip alata mora zadovoljavati,
kao i testove i provjere koji utvrđuju zadovoljavaju li alati tražene
kriterije. Korištenjem specifičnih uvjeta pri ispitivanju alata može se pronaći
i ukloniti samo određen broj pogreški zbog previše velikog broja mogućih
testova. Na primjer, osmišljanje smislenog skupa kriterija i testova za sve
alate za analizu NTFS datotečnih sustava
gotovo je nemoguće provesti ako se uzme u obzir kako strukture datotečnih
sustava nisu javno dostupne. Kada se problem promatra s strane vremena u kojem
je potrebno provesti ispitivanje, malo je vjerojatno kako bi se mogao razviti
takvo ispitno okruženje koje bi validiralo svaku postojeću konfiguraciju
datotečnih sustava. Činjenica je kako bi kriteriji tih ispitivanja bili znatno
stroži kada bi se koristili prilikom
računalne digitalne analize, nego prilikom standardnih ispitivanja
aplikacija ili operacijskih sustava. Alat za analizu mora biti u stanju nositi
se s svim zamislivim situacijama; inače bi osumnjičenik moga potencijalno
stvoriti uvjet koji bi sakrio podatke od istražitelja. Općenito, originalna
aplikacija mora ispitati samo mogućnost kako se može nositi s svim uvjetima
koje sama može stvoriti. Iako još uvijek ne postoji standardizirana
metodologija ispitivanja, nedostatci i pogreške u javno dostupnima i
komercijalnim aplikacijama pronalaze istražitelji u polju forenzike i
sigurnosti informacijskih sustava, te o njima obavještavaju vlasnike istih.
Argument
koji se često spominje protiv javno dostupnih aplikacija je kako zlonamjerni napadači mogu pregledom izvornog teksta programa
pronaći i iskoristiti nedostatke i ranjivosti, no ovo ni u kojem slučaju nije
vezano isključivo s javno dostupnim izvornim kodovima, zapravo alati koji imaju
dostupan izvorni tekst programa samo će poboljšati kvalitetu ispitnog procesa jer se pogreške
(eng. bugovi) mogu
identificirati pregledom koda, te
osmišljanjem testova zasnovanih na dizajnu i načinu rada softvera. Ove bi
testove trebale provoditi kvalificirane osobe, a svi rezultati tih ispitivanja
moraju biti objavljeni. Vlasnici komercijalnih aplikacija i alata trebali
bi u najmanju ruku objaviti
specifikacije dizajna kako bi
institucije kao što su NIST CFTT, mogle učinkovitije ispitati procedure
alata.
2.3.2
Statistike
učestalosti pogrešaka
Smjernice
učestalosti pogrešaka služe nam kao reference postoji li poznata statistička
učestalost pogreške (eng. Error rates) za određeni alat. Alati digitalne forenzike
uobičajeno obrađuju podatke sljedeći niz pravila. Ta pravila utvrđuju
developeri koji su razvili originalnu ispitivanu aplikaciju. Na primjer, alat
korišten za ispitivanje datotečnih sustava koristi specifikacije datotečnog
sustava. Ako su te specifikacije javno dostupne tada do pogrešaka ne bi trebalo
doći, no ako specifikacije nisu javno dostupne kao što je slučaj kod NTFS
datotečnog sustava, tada je moguće da do pogrešaka dođe zbog određenog
nerazumijevanja načina funkcioniranja
sustava. Ovdje se mogu povući paralele s metodama ispitivanja asociranih s
prirodnim sustavima kao što su ispitivanja DNA strukture ili otisaka prstiju,
gdje se mogu dogoditi pogreške ovisno o tome kako je provedeno ispitivanje.
Alatima
korištenim u digitalnoj forenzici
definiraju se dva tipa pogreške;
pogreška implementacija alata (eng. Tool
Implementation Error), te pogreška apstrakcije (eng. Abstraction error). Do pogreška implementacije alata dolazi zbog
korištenja krive specifikacije ili
pogrešaka u izvornom tekstu programa. Pogreška apstrakcije događa se kada alat
donosi odluke koje nisu u potpunosti sigurne, odnosno točne. Ovaj se tip pogreške
najčešće događa prilikom korištenja tehnika koje smanjuju obujam podataka, ili
obradom podataka na način na koji to
originalno nije predviđeno.
Relativno
je jednostavno pridružiti pogrešku apstrakcije svakoj proceduri, a ona se
smanjuje daljnjim istraživanjem. Teže je dodijeliti vrijednost pogreške implementacije alata.
Njen se izračun provodi za svaki alat, a vrijednost pogreške ovisi o broju
pogrešaka u izvornom tekstu programa i njihovoj ozbiljnosti. Kako bi se došlo
do tih podataka potrebno je imati pristup prošlim zapisima lista pogrešaka tih
alata. Do ovih je podataka relativno jednostavno doći kada se radi o alatu čiji
je izvorni tekstu programa javno dostupan iz jednostavnog razloga jer čak iako
pogreška nije dokumentirana, može se usporediti najnovija verzija koda s
prošlom kakao bi se saznalo koji se dio koda mijenjao. Vrijednost učestalosti
pogrešaka bilo bi jako teško izračunati
za komercijalne alate zbog toga što se
njihove pogreške i propuste nikada službeno ne objavljuje, kao niti učestalost
pogrešaka ili broj ispravljenih zbog
straha od pada prodaje proizvoda. Kako jednadžba za izračunavanje tih pogrešaka
nije predložena, kao mjerilo koristi se popularnost alata, zbog pretpostavke da
alat s visokim postotkom pogreške ne bi bio toliko korišten ili kupovan. Za
početak ova može pomoći, no trebao bi se pronaći neki znanstveni način
utvrđivanja vrijednosti učestalosti pogreške
zbog toga što brojke o prodaji proizvoda ne pokazuju koliko se alat često
koristi ili kako kompleksne podatke analizira. Učestalost pogreške mora biti
pouzdana za najjednostavnije scenarije analize, kao i za one komplekse u kojim
osumnjičenik pokuša sakriti određene podatke od alata. Kako bi izračunali error rate prvo je potrebno razviti
ispitnu metodologiju koje zahtijevaju
početne smjernice. Alati s javno dostupnim kodom ili dokumentiranim
specifikacijama dizajna omogućuju
jednostavnije stvaranje metodologije ispitivanja.
2.3.3
Publikacija
Smjernice
o publikaciji pokazuju kako su procedure podvrgnute metodi peer review i kako je ta dokumentacija javno dostupna. Prije je ovo
bio glavni uvjet kako bi dokaz bio prihvaćen. Danas postoje peer review časopisi (npr. International Journal of Digital Evidence),
u kojima se opisuje koliko je na primjer
alat popularan, te navodi njegove mogućnosti, glavne procedure korištene za
analizu i dobavu podataka, ali ne i tehničke procedure korištene prilikom
izvlačenja podataka iz originalnog mjesta pohrane.
Za
analizu datotečnih sustava, procedure koje moraju biti objavljene su one koje
se koriste za razbijanje slike datotečnog sustava u nekada i tisuće dokumenata
koje korisnici stvore u datotekama i direktorijima. Neki datotečni sustavi kao
što je FAT imaju javno objavljene detaljne specifikacije, dok drugi kao što je
NTFS nemaju. Samo se zaslugom Linux zajednice može doći do detaljne NTFS
strukture. Važno je da se za alat objave procedure korištene za obradu
datotečnih sustava, pogotovo onih čije dokumentacije nisu javno dostupne.
Nadalje, većina alata korištenih za forenzičku
računalnu analizu datotečnih sustava prikazuje datoteke i dokumente koji
su nedavno bili obrisani, te ih u nekim slučajevima mogu i vratiti odnosno
obnoviti (eng. recover). Ovi zadatci
nisu dio originalnih specifikacija datotečnih sustava, te za njih ne postoji
standardizirana metoda izvođenja. Imena izbrisanih dokumenata pronalaze se
obradom neiskorištenog prostora, te pronalaženjem podataka koji zadovoljavaju
određene uvijete i provjere (eng. Sanity
check). Ako su ove provjere previše stroge, neka od izbrisanih imena i
dokaza neće biti pronađeni. Međutim, ako su zahtjevi previše slabi ili
popustljivi, prikazati će se previše velik broj podataka. Detalji ovih procesa
moraju se objaviti kako bi istražitelji mogli identificirati korištene procedure.
Forenzički
časopis FBI-a (eng. Federal Bureau of
Investigation) 1999. godine objavio je dokument o korištenju digitalne
fotografije, gdje se navodi kako proizvođači softvera koji se koristi za obradu
slika mogu biti zamoljeni da predaju izvorni tekst programa na pregled, te
kako odbijanje istoga vodi odbijanju
dokaza prikupljanih i obrađenih tim alatom. Ova izjava pokazuje kako softver
developeri moraju biti spremni na objavljivanje izvornih kodova svojih
proizvoda ukoliko žele da se oni koriste za generiranje, analizu i prikupljanje
mogućih dokaza. Ako proizvođač na to
nije spreman, dužnost mu je tu činjenicu naglasiti prije prodaje alata za
analizu. Ako sud dozvoli pregled izvornog koda od strane stručne osobe, ali ne
i njegovo objavljivanje, tada se ove slijednice mogu prihvatiti ako postoji
opće prihvaćena tehnika obrade podataka. Stručni svjedok može u tom slučaju usporediti izvorni
tekst programa s prihvaćenom procedurom, te provjeriti ako se ispravno
implementira.
2.3.4
Prihvaćanje
digitalnih dokaza
Slijednice
prihvaćanja digitalnih dokaza koriste se
u znanstvenoj zajednici prilikom
evaluacije objavljene procedure. Prihvaćanje alata nije ekvivalentno
prihvaćanju svih njegovih procedura. Ako postoji malen broj alata koji provode
neku proceduru, a niti jedan od njih nema objavljene detalje provedbe te
procedure ili njene poznate pogreške, tada će izbor alata vjerojatno biti
temeljen na ne proceduralnim faktorima kao što su sučelje ili programska
podrška. Dok se proceduralni detalji ne objave i postanu faktor prilikom kupnje
računalnih forenzičkih alata za analizu, broj korisnika pojedinog alata nije
valjana mjera prihvaćanja procedura. Alati s javno dostupnim kodom
dokumentiraju procedure koje koriste, prilaganjem izvornog koda, omogućujući
znanstvenoj zajednici da ih odbiju ili prihvate.
Kako
bi alati korišteni za digitalnu forenzičku analizu bili prihvaćeni potrebno je
poduzeti sljedeće korake:
— Razvoj razumljivih testova za
sve alate korištene za analizu
datotečnih sustava.
— Publikacija dizajna alata kako
bi se mogli izraditi efektivniji i
precizniji testovi za te alate.
— Stvaranje standarda za izračun
učestalosti pogrešaka za alate kao i procedure koje koriste.
— Publikacija specifičnih
procedura i njihovih opisa.
— Javne rasprave o učinkovitosti
alata.
Alati
korišteni u digitalnoj forenzici daju
nam odgovore na temelju kojih se može otpustiti zaposlenika, osuditi zločince,
dokazati nevinost... Cilj alata digitalne forenzike stoga ne bi
trebala biti samo dominacija na tržištu. Digitalna forenzika znanost je u nastanku
koja treba težiti stalnom usavršavanju. Korištene se procedure moraju objaviti,
ispitati njihova učinkovitost, debatirati o njihovoj preciznosti, te ih i formalno ispitati [11].
3. Digitalna forenzička istraga
Cilj računalne forenzičke istrage je identifikacija digitalnih dokaza
prikupljenih u sklopu istrage. U istrazi se prilikom rekonstrukcije tijeka događaja koriste fizički, kao i digitalni dokazi.
Primjeri istraga koje koriste digitalnu forenziku uključuju napade na računala,
neautorizirana korištenja korporacijskih računala, dječja pornografija, te bilo
koji fizički zločin u kojem je osumnjičenik posjedovao računalo, ili bilo kakav
elektronički medij sa kojeg je moguće
prikupiti podatke.
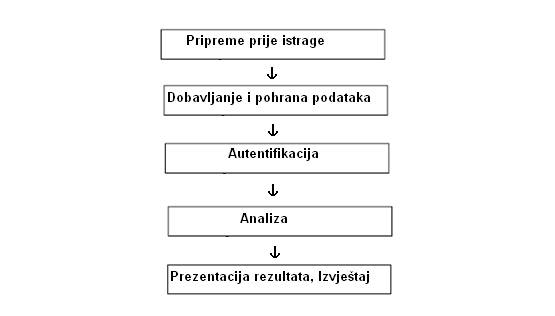
Digitalna forenzička istraga sastoji se od tri glavne
faze:
1.
Dobavljanje
dokaza
2.
Analiza
dokaza
3.
Prezentacija
rezultata
Faza dobavljanja omogućuje očuvanje stanja
digitalnog sustava kako bi se on kasnije mogao analizirati. Ova se faza
analogno može poistovjetiti s uzimanjem otisaka prstiju, krvi, ili tragova
guma, te fotografiranjem na mjestu zločina.
Kako se prilikom sakupljanja dokaza ne zna koji će materijali biti
korisni u istrazi, cilj je kopirati sve digitalne vrijednosti. Kopiraju se
alocirana i nealocirana područja tvrdog diska, odnosno izradi se identična
kopija diska (eng. image). Alati koji
se koriste moraju u što manjoj mjeri mijenjati istraživani medij i podatke na
njemu [12].
U fazi
analize prikupljeni se podatci ispituju, kako bi se identificirali dijelovi
dokaza potrebni u istrazi. Kategorije dokaza ugrubo se dijele na tri
kategorije:
·
Inkriminirajući
dokazi (eng. Inculpatory Evidence):
oni koji podupiru teoriju istraživača.
·
Oslobađajući
dokazi (eng. Exculpatory Evidence):oni koji pobijaju teoriju istraživača
·
Dokazi
o manipulaciji (eng. tampering): ovi
dokazi pokazuju kako je sustav podvrgnut namjernim promjenama kako bi se
izbjegla identifikacija.
Ova faza
uključuje pretragu sadržaja direktorija i datoteka, kao i povrat (eng. Recovery) izbrisanog sadržaja. Alati
korišteni u ovoj fazi analiziraju
sustave direktorija, sastavljaju liste imena izbrisanih datoteka, ostvaruju njihov povrat i
predstavljaju podatke u najkorisnijem formatu.
U ovoj se
fazi prilikom analize koristi identična kopija originalnih podataka, što se
može jednostavno provjeriti izračunavanje MD5 checksum. Važno je da ovi alati prikažu sve podatke koji postoje u
forenzičkoj kopiji sustava.
Faze
dobavljanja i analize podataka odvijaju se u istim koracima bez obzira gdje i
tko obavlja istragu (korporacije, državne agencije, vojska), dok se
prezentacijska faza znatno razlikuje u određenim okolnostima jer je u cijelosti
zasnovana na sigurnosnim politikama i zakonima određenih institucija u kojima
se provodi. U fazi prezentacije predstavljaju se zaključci
dobiveni analizom i proučavanjem dokaza.
Sam
oblik izvještaja ovisi o specifikacijama traženim od naručitelja istrage,
odnosno suda gdje se rezultati izlažu. Uobičajeni oblik sadržava kratak
zaključak o rezultatima istrage, detaljan opis dokaza te način njihova
prikupljanja kao i metode korištene prilikom analize dokaza.
Dokumentacija
izvještaja uobičajeno se sastoji od
nekoliko dijelova:
·
Radna
dokumentacija:dokumentirane su
korištene procedure, alati i metode, te doneseni zaključci.
·
Prvi
izvještaj(eng. Preliminary report):
ako se prilikom istrage zahtijevalo izvršavanje data sampling analize.
·
Konačni
izvještaj.
Slika 3.1Tijek digitalne forenzičke istrage
3.1
Pripreme
prije istrage
·
Prilikom
provedbe istraga unutar korporacija, uvijek je korisno razgovarati s IT
djelatnicima, te doznati način i lokacije skladištenja podataka. Loša strana
ovog pristupa je naravno moguće otkrivanje provedbe istrage neautoriziranim
osobama.
·
Određivanje
vremenskog razdoblja važnog za istragu, te obujam podataka koje treba
pretražiti kako bi se izbjegla analiza nepotrebno velike količine podataka, kao
i preskakanje moguće važnih.
·
Određivanje tipova informacija važnih za istragu, kako bi
se skratilo vrijeme i smanjio obujam pregledanih informacija.
·
Određivanje
riječi, imena, jedinstvenih fraza pomoću kojih je moguće filtrirati podatke, te
pronaći one važne
·
Prikupljanje
korisničkih imena i zaporki mrežnih i računa elektroničke pošte.
·
Utvrditi
broj računala te ostalih medija, kao i internet promet koji bi mogao sadržavati
važne dokaze.
Prilikom obrade računala čija se
vjerodostojnost ne može utvrditi, inicijalno se taj sustav smatra nesigurnim
dok se ne dokaže suprotno. Prilikom izvršavanja programa koriste se dijeljene
biblioteke za izvršavanje rutinskih sustavskih
naredbi, koje pritom mijenjaju vremena pristupa tim zajedničkim
datotekama. Vremena pristupa važna su prilikom istrage kada je potrebno
utvrditi slijed događaja pojedinih aktivnosti. Kako bi se izbjegle ovakve
situacije, izrađuju se kompleti alata koji koriste potrebne biblioteke
pohranjene i statički kompajlirane na nekom mediju. Preporučuje se odabir alata
koji kao rezultat daju izlazno specifične informacije čijom se kompilacijom
može utvrditi sustavske međuovisnosti i koje
je moguće statički kompajlirati.
3.2
Dobavljanje
podataka
Jedno od
pravila digitalne forenzike jest kako se nad originalnim podatcima ne smiju
provoditi analize već se stvara identična kopija kako se ne bi uništilo
originalne podatke. Stvaranje forenzičke kopije naziva se dobavljanje ili
akvizicija (eng. acquisition).
Forenzička kopija naziv je za završni produkt forenzičkog prikupljanja informacija s tvrdog diska ili drugih medija
za pohranu informacija istraživanog računala. Forenzička kopija naziva se
i bitstream
kopija, ili bitstream slika (eng. bitstream image), zbog toga što
predstavlja identičnu bit-po-bit kopiju originalnog dokumenta, datoteke,
particije, slike, fotografije, ili diska.
Svi su metapodatci, datumi dokumenata, slack područja, neispravni sektori u slici identične kopije
originala. U praksi je uobičajeno ostvariti nekoliko forenzičkih kopija u
slučaju da se nešto dogodi slici koja se obrađuje.
Prikupljanje
nije isto što i kopiranje dokumenata s jednog medija na drugi. Kopiranjem se ne
mogu očuvati datumi i vremenske oznake (eng. time stamps).
Postoji
nekoliko načina izrade slike, korištenjem specijaliziranog softvera:
·
Zrcalna
kopija: ovaj način očuvanja dokaza temelji se na metodi hvatanja (eng. capture) ili kopiranja svih podataka na
disk, kako bi se stvorila neinvazivna zrcalna kopija (eng. mirror image) kopiranog diska. Mirror
image može, ali i ne mora predstavljati identičnu kopiju originala zbog toga što se ona općenito koristi kao
sigurnosna kopija (eng. backup), a u
zahtjevnijim situacijama mirror image
ne tretira se kao forenzička kopija.
·
Sektor-po-sektor
kopija ili bitstream: ova naprednija metoda započinje na početku diska te
kopira svaki bit, jedince i nule, sve do kraja, bez brisanja ili ikakvog mijenjanja podataka. Kopiraju se i
neiskorišteni dijelovi, kao i nealocirani dijelovi diska zbog toga što se na
njima često nalaze izbrisani podatci.
Definicije nekoliko pojmova koji se često koriste kao sinonimi,
što pri svakodnevnom korištenju računala
ne predstavlja problem, no prilikom forenzičke analize razlika između bitstream kopije i kopije veoma je velika:
- Kopija: uključuje
samo informacije o datotekama, ne i o slack
ili nealociranom prostoru, nisu očuvane vremenske oznake.
- Pričuvna kopija (eng.
Backup): datoteke kopirane za buduću
restauraciju, služe kao sigurnosna kopija
- Slika (eng. Image): kopija datoteka kompletnog
diska kreirana zbog dupliciranja ili
restauracije
- Kopija bit-po-bit ili Bitstream kopija: Egzaktna replika svih
sektora
3.2.1
Isključiti
ili ne isključiti
Prihvatljiva
je činjenica kako je moguće gašenjem računala nepovratno izgubiti dio dokaza
ukoliko nisu bili pohranjeni, ali će integritet već prisutnih dokaza biti
očuvan. Ranjivi podatci moraju se sakupiti s uključenog računala. Sakupljanje
postojanih podataka provodi se
drukčije gašenje računala može pokrenuti
maliciozni softver koji na primjer briše dokaze. Ukoliko postoji sumnja kako
postoje takvi zloćudni programi, preporučuje se isključivanje kabla napajanja.
Nakon gašenja računala istraživač ima dvije opcije:
1.
Odstraniti
tvrdi disk , te ga ugraditi kao read-only komponentu na računalo
korišteno za forenzičke preglede.
2.
Ako
je nemoguće odstraniti medij za pohranu podataka, podatcima se pristupa bootanjem računala sa live verzijom operacijskog sustava kao što je Knoppix STD il Helix.
Oboje sadržavaju potrebne forenzičke alate potreban za izradu forenzičke
kopije.
3.2.2
Ispravan
način dobavljanja digitalnih dokaza
Temelji
računalne forenzičke istrage ne svodi se na kompromitirajuću e-poruku koja
dokazuje pronevjeru direktora kompanije. Istraga ovisi o tome kako se
forenzički prenese podatke s jednog mjesta na drugo bez njihova mijenjanja,
kompromitiranja ili uništavanja, te o naknadnoj analizi i prezentaciji
relevantnih podataka [11].
Dobavljanje
podataka na forenzički prihvatljiv način temelj je svake kvalitetne forenzičke
istrage. Ukoliko se taj korak ne obavi prema određenim pravilima, svi kasniji
pronalasci, kao i otkriveni dokazi i informacije mogu se odbaciti zbog
nepravilnog dobavljanja kopija originalnih podataka. Glavna zapreka prilikom
stvaranja prihvatljive forenzičke kopije je mogućnost da se prilikom pokušaja kopiranja podatci na neki
način izmijenjene. Oprema koja se koristi prilikom dupliciranja podataka ovisi
o mediju s kojeg se ti podatci trebaju kopirati. Uobičajeni postupak uključuje dokumentiranje svakog
učinjenog koraka prilikom dobave podataka. Generalizirani format procesa dobave
podataka može se podijeliti na nekoliko koraka:
1.
Određivanje
tipa medija na kojem se radi.
2.
Pronalazak
odgovarajućeg alata.
3.
Prijenos
podataka: koristeći odgovarajući opremu prenose se podatci na sterilni medij(u
koliko je to potrebno), pritom koristeći alat kojim je moguće potvrditi
integritet podataka, te njihovu autentičnost
4.
Autentificiranje i provjera integriteta prenesenih podataka provjerom checksum i hash
vrijednosti.
5.
Stvaranje
radne kopije forenzičke kopije kopije. U praksi originalnim se podatcima
pristupa jednom, forenzičkoj kopiji dva puta, a radnoj kopiji koliko god je
puta potrebno prilikom istrage. Razlog izrade duplikata kopije jest potreba za
radnom kopijom koju se obrađuje i koju
se u slučaju gubitka ili uništenja podataka jednostavno može zamijeniti bez
daljnjeg kompromitiranja originalnih podataka. Izradi duplikata pristupa se kao
da je forenzička kopija originalni skup podataka.
Korištenje
softvera za brisanje podataka s forenzičkog medija za pohranu podataka
važan je korak pri osiguravanju kako podatci dobavljeni na taj uređaj nisu
kontaminirani podatcima prijašnjih slučajeva. Osnovni proces brisanja medija za
pohranu sastoji se od zapisivanja niza
binarnih znamenki po cijelom fizički
raspoloživom području. Medij prebrisan ovom metodom naziva se sterilan uređaj
za pohranu. Softver za brisanje medija najčešće je uključen u pakete
forenzičkih alata, no postoje i samostalni kao što su Lsoft Technologies Hard Drive Eraser, White
Canyon Wipe Drive 5. Jedina mana ovog tipa softvera jest dugo vrijeme
izvođenja. Prilikom brisanja većih diskova, proces može trajati i danima.
3.2.3
Određivanje
tipa medija
Tipovi medija za
pohranu podataka mogu se podijeliti na:
·
Ugrađeni
uređaj za pohranu podataka (eng. Fixed
storage device): bilo koji uređaj za
pohranu podataka koji je trajno priključen u računalu.
·
Prijenosni
uređaji za pohranu podataka: floppy
diskete, flash memorije, iPod, MP3 player, mobilni telefoni, neki tipovi
ručnih satova...
·
Ugrađen
memorijski prostor za pohranu podataka
(eng. Memory storage area): s prijelazom
sa stolnih računala na mobilne uređaje, sve se više dokaza pronalazi u
memorijama tih uređaja. Očiti primjer ove kategorije jest mobilni telefon, PDA
dlanovnik, koji često spremaju podatke samo u izbrisivu (eng. Volatile) memoriju. Kada se baterija
iscrpi, podatci se gube. Manje očita mjesta za pronalazak dokaza u volatile
memorijama su RAM područja stolnih i prijenosnih računala te poslužitelja, kao
i mrežnih uređaja.
·
Mrežni
uređaj za pohranu podataka ( eng. Network
storage device): usmjerivači, preklopnici, pa i bežične točke pristupa
(eng. Wireless acess points) arhiviraju potencijalno korisne forenzičke
informacije.
·
Memorijske
kartice: mnogi uređaju koriste i digitalne memorijske kartice uz ugrađenu RADNU
memoriju kako bi se povećao kapacitet pohranjivanja podataka. Najčešći tipovi
su SD i MMC flash kartice.
3.2.4
Pronalazak
odgovarajućeg alata
Prilikom
dobavljanja forenzičke slike, koristi se metoda bit-po-bit kopiranja, kojom se kopira
svaki bit s originalnog medija od
fizičkog početka do fizičkog kraja. Koncept je veoma jednostavan, no bez
odgovarajućih alata njegovo izvršenje može biti problematično. Dobavljanje bitstream slike komplicirano je iz dva
razloga; Operacijski sustav ne prepoznaje cijeli tvrdi disk i integritet sustava može biti kompromitiran.
Operacijski
sustavi alociraju prostor na svojim medijima za pohranu podatka, no uvijek
preostane malen dio tvrdog diska koji nije dostupan operacijskom sustavu. Na
primjer, Windows OS prepoznaje 95.8 GB od 100 GB fizičkog prostora na tvrdom disku. Gubitak prostora za
pohranu podataka ne događa se samo na tvrdim diskovima već i na medijima kao što su flash memorijske kartice, kamere, pa čak i mobilnim telefonima.Operacijski
sustav rijetko koristi svaki fizički
raspoloživ bit. Većina operacijskih sustava radi na taj način, stoga se
istražitelj mora pouzdati na alat koji ne koristi operacijski sustav lokalnog računala kako bi dobavio bitove s
medija za pohranu podataka. Neki od tih alata navedeni su u nastavku:
·
FTK,
EnCase, Paraben: alati koji ispravno funkcioniraju na većini operacijskih sustava (Windows, Linux, Apple).
·
Hex
editori, utilities na razini sustava:
softverski alati koji se koriste za detaljniju pretragu struktura datotečnih
sustava i njihovih dokumenata. Za njihovo ispravno korištenje potrebno dobro
poznati specifične datotečne sustave.
·
Duplikatori
diskova: sklopovski uređaji kao što je Logicube Forensic Talon, dupliciraju
medije za pohranu podataka u kratkom vremenu, te na forenzički prihvatljiv
način s propusnošću i do 4 GB podataka u
minuti.
·
Zaštite
protiv pisanja (eng Write protectors,
blockers): Na primjer Weibtech
Forensic Ultradock sprječava slučajno ili namjerno zapisivanje, brisanje
ili formatiranje podataka na disku tijekom pregleda ili dobave podataka. Write blocker alati odgovaraju na
zahtjev pisanja operacijskog sustava porukom koju OS očekuje nakon što je već obavljeno pisanje
ili brisanje na mediju. Postoje dva tipa
alata write blocker; fizički i logički. Fizički write blocker presreće podatkovne signale s podatkovne sabirnice
računala, te odgovara odgovarajućim podatkovnim signalima na način na koji bi i
sama sabirnica odgovorila operacijskom sustavu. Write blocker alati ovoga tipa
rade nezavisno o operacijskom sustavu istraživanog računala. Logički write blocker najčešće dolaze u paketu
računalnih forenzičkih softvera, oni presreću
pozive za pisanje na softverskoj razini, i specifični su za svaki tip
operacijskog sustava.
3.2.5
Prijenos
podataka
Prilikom
dobavljanja podataka tipa sa računala na računalo, kao platforma za izvlačenje
podataka na računalo istražitelja koristi se istraživano računalo.Od svih
metoda prijenosa podataka, ova najčešće izaziva slučajnu korupciju podataka, zbog
načina na koji se podatci moraju dobaviti. Koriste se dvije metode spajanja
kabelima:
·
Paralelni
: najsporija metoda, no najbolja, spaja se izravno računalo s računalom.
·
Mrežni
: nešto brža metoda, spaja računalo na mrežu
istraživanog računala LAN kabelom.
Ograničavajući faktor obije metode
je količina podataka koja se može prenijeti u jedinici vremena. Obije
metode korisne su prilikom pregleda materijala, i traženja očitih dokaza, no
općenito ih se ne isplati koristiti za kopiranje podataka većih od 50GB.
Sljedeći
problem koji se može pojaviti korištenjem ove metode prijenosa podataka jest
mogućnost korupcije podataka ili modifikacija dokaza. Koristeći ovu metodu
operacijski sustav istraživanog računala
boota se pomoću forenzičkog boot medija. Ponaša se kao softverski write blocker koji spaja forenzičko računalo kako bi prijenos podataka bio moguć. Boot medij može biti floppy disketa, CD,
DVD ili čak USB uređaj. U slučaju nepažnje ili ne pridržavanja procedure
izvlačenja, postoji velika vjerojatnost kako će se računalo podići korištenjem svog lokalnog tvrdog diska, te time potencijalno obrisati
podatke koji su možda važni u istrazi, ili kompromitirati kredibilitet istrage.
Prijenos podataka između dva računala odvija se u sljedećim koracima:
1. Ukoliko je računalo ugašeno, isključiti kabel napajanja.
2. Otvoriti kućište, te odspojiti napajanje diska za pohranu podataka.
3. Ponovno spojiti kabel napajanja, uključiti računalo te ući u BIOS.
4. Promijeniti redoslijed na koji računalo diže sustav, kako bi korišten boot medij bio na prvom mjestu, te
sačuvati načinjene promijene.
5. Umetnuti korišteni
medij, restartati računalo, provjeriti funkcionira li sve.
6. Ugasiti računalo,
ponovo spojiti tvrdi disk te uključiti računalo,
pokrenuti forenzički softver za prijenos ili pregled podataka.
Dobavljanje
podataka kopiranjem s uređaja za pohranu
podataka na računalo znatno je brže i
sigurnije. Način dobave podataka:
1. Otkrivanje tipa istraživanog medija
2. Korištenje ispravnog write
blocker alata: ovaj korak može biti problematičan ukoliko se istraga
obavlja na licu mjesta zbog toga što forenzički paketi sadržavaju limitiranu
selekciju sučelja za spajanje.
3. Prikupljanje podataka forenzičkim
softverom.
4. Izrada radne kopije.
3.2.6
Provjera
integriteta sačuvanih podataka
Kako je digitalne
podatke iznimno jednostavno mijenjati u
forenzičkim je postupcima bitno utvrditi kako se podatci nakon dobavljanja i analize nisu mijenjali. Ukoliko forenzička
slika nije autentificirana, može se dogoditi da se svi dokazi prikupljeni s nje
ne mogu uzeti u obzir. Kako bi se takve situacije izbjegle koriste se alati ako
što su FTK Imager, ili ENCase prilikom stvaranja forenzičke kopije. Ovi
programi sastavljaju izvještaj koji uključuje dva digitalna otiska prstiju koji
se nazivaju MD5 i SHA1 hash
vrijednosti, pomoću kojih je moguće identificirati i autentificirati
prikupljene podatke. Hash vrijednosti
omogućuju matematičko dokazivanje kako su dokazi i njihovi duplikati identični.
Ukoliko se duplikat mijenja, hash
vrijednosti im se više neće poklapati.
Autentifikacijom elektroničkih dokaza utvrđuje se dodatno i jeli
računalo s kojeg su prikupljeni podatci u tom trenutku ispravno funkcioniralo.
Ponekada hash vrijednosti ne odgovaraju zbog
tehničkih razloga, od kojih su najčešći:
·
Medij
s kojega dobavljamo podatke počinje se kvariti, softver nije u mogućnosti
ispravno prenijeti podatke s jednog medija na drugi, stoga hash vrijednosti ne odgovaraju.
·
Korištena
oprema nije ispravna: originalni medij je ispravan, kao i ciljni medij, no
transportni medij nije.
Iznimni
slučajevi u kojima se checksum ne
mogu podudarati su oni u kojima se radi
na računalima, mobitelima, te ostalim uređajima koji su aktivni, tj podatci na
njima se još uvijek mijenjaju.
3.2.7
Prikupljanje
ranjivih podataka
Računalna se forenzika tradicionalno fokusirala na istraživanje, razvoj i implementaciju ispravnih tehnika, alata i metodologija za prikupljanje, pohranu i očuvanje osjetljivih podataka ostavljenih na medijima za pohranu. Osobe koje prve pristupaju istraživanom računalu (mrežni i sustavski administratori, policijski istražitelji), općenito reagiraju na sigurnosni incident tako da isključe i osiguraju računalo. Nakon isključivanja, sakupljaju se postojani podatci s medija za pohranu podataka. Isključivanje računala onemogućuje sakupljanje ranjivih informacija (eng. Volatile data).
Postoje mnogi open source alati koji omogućuju izvlačenje ranjivih podataka s računala, no većina ih je specifično dizajnirana za prikupljanje samo dijelova ranjivih podataka, ovisno o njihovoj lokaciji i tipu.
Ranjivi podatci pohranjeni su u memoriji sustava; na primjer sustavskim registrima, cache memoriji, radnoj memoriji, i gube se ukoliko računalo više nije spojeno na izvor napajanja, ili se resetira. Ranjivi podatci trebali bi se prikupiti ukoliko istražitelj nije siguran zbog čega računalo ne radi normalno, ako se primijeti neuobičajena aktivnost korisnika, odnosno ako je prekršena neko sigurnosno pravilo ili dobivena obavijest od strane zaštitne stijene ili IDS-a (eng. Intrusion detection system). Prva reakcija na računalni sigurnosni incident trebalo bi biti prikupljanje ranjivih podataka, te analiza rezultata kako bi se utvrdio daljnji slijed događaja.
Postojani podatci nalaze se na tvrdim diskovima računala, i ostalim medijima za trajniju pohranu podataka kao što su prijenosne memorije (USB memorije), flash kartice, CD, DVD, vanjski tvrdi diskovi, i obično se ne gube kada se računalo ugasi ili resetira. Općenito, postojani podatci se sakupljaju kada se zna kako se podatci vezani uz sigurnosni incident nalaze na stalnim mjestima za pohranu.
Prilikom prikupljanja postojanih podataka kontaminaciju je moguće izbjeći pridržavanjem ustaljenih i provjerenim metoda te korištenjem provjerenih alata koji stvaraju bit-po-bit kopiju podataka i generiraju checksum zbog provjere integriteta i autentifikacije kopije podataka. Prilikom prikupljanja ranjivih podataka, teže je izbjeći kontaminaciju, zbog toga što sami korišteni alati i njihove procedure mogu promijeniti datume i vremena pristupa podatcima, koristiti zajedničke dinamičke povezne biblioteke (eng. Dinamic Link Library, srkać. DLL), izazvati pokretanje zlonamjernih programa, ili resetiranje računala. Bit-po-bit kopiju ranjivih podataka očito nije moguće izraditi, no korištenjem provjerenih alata moguće je prikupiti podatke i rekonstruirati logičnu reprezentaciju trenutnog stanja istraživanog računala.
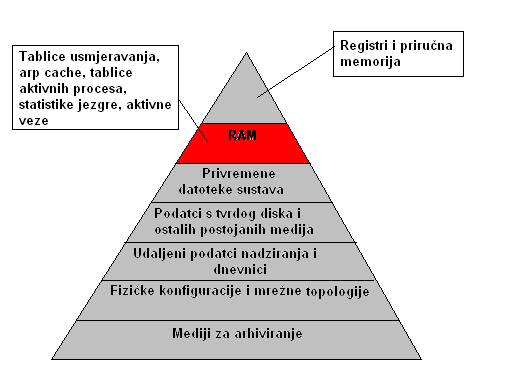
Slika 3.2 Hijerarhija ranjivosti podataka
Prilikom prikupljanja podataka s računala koje radi,
važno je uzeti u obzir hijerarhiju ranjivosti podataka: tj prvo se prikupljaju
podatci koji će se najvjerojatnije najbrže promijeniti, modificirati ili
izgubiti. Na Slici 3.2 prikazana je hijerarhija ranjivih podataka.
Ranjive podatke pohranjene u radnoj memoriji potrebno je, ako je moguće ,dohvatiti čim se dogodi sigurnosni incident kako bi se sačuvali podatci o trenutnom stanju računala uključujući prijavljane korisnike, aktivne procese, otvorene veze. Ovi podatci omogućuju rekonstrukciju vremenskog slijeda događaja sigurnosnog incidenta, nekad i mogućeg počinitelja. Nakon prikupljanja što je više moguće ranjivih podataka, odlučuje se o daljnjim akcijama na temelju njihove analize [11].
Dvije
najčešće pogreške koje se događaju prilikom prikupljanja ranjivih podataka:
·
Gašenje
ili resetiranje računala: U ovom slučaju svi se ranjivi podatci gube,
uspostavljene veze, gase se aktivni procesi, mijenjaju se MAC vremena.
·
Pretpostavka
kako su neki dijelovi računala pouzdani, te se njihovim korištenjem može slučajno pokrenuti zloćudne programe koji
mogu uništiti ključne dokaze
3.2.8
Tipovi
ranjivih informacija
S
istraživanog računala moguće je sakupiti dva tipa ranjivih informacija:mrežne i
informacije o sustavu.
Ranjive informacije sustava predstavlja skup informacija o trenutnoj
konfiguraciji i radnom stanju
istraživanog računala. Ova se skupina dalje dijeli prema alatima koji
sakupljaju samo određene tipove informacija kao što su:
·
Profil sustava
·
Trenutno vrijeme i datum sustava
·
Naredbena povijest
·
Aktivni procesi
·
Otvoreni dokumenti, bilješke, start up files
·
Trenutno prijavljeni korisnici
·
DLL i dijeljene biblioteke
Ranjive mrežne informacije predstavlja skup informacija o stanju mreže na
koje je spojeno istraživano računalo, ova se skupina dalje dijeli na:
·
Aktivne
veze
·
Otvoreni
portovi i sockets
·
Informacije
o usmjeravanju i konfiguraciji usmjerivača
·
ARP
cache za identifikaciju nedavno
uspostavljenih veza sa internetom pruža
uvid s kim je korisnik komunicirao, što je slao a što primao
Informacije
o usmjeravanju prikupljaju se zbog uvida u konfiguracije tablica usmjeravanja,
te nedavno dodane konekcije. Treba obratiti pozornost na statički dodane
usmjerivače, nepoznate IP adrese i MAC adrese.
3.2.9
Prikupljanje
skrivenih podataka
Izazov svakom forenzičkom
istražitelju predstavljaju skriveni,
ili prerušeni podatci. Zajednički naziv za takve podatke jest nevidljivi
digitalni dokazi (eng invisible electronic evidence). Istraživač mora
otkriti pokušaje prikrivanja, te doći do skrivenih informacija, time
svrstavajući ovaj dio računalne forenzike u jedan od najintrigantnijih i
najzahtjevnijih.
Kriminalci i
vlade skrivali su podatke tisućama godina, koristeći tehnike kao što su šifre pomicanja baze abecede za
dogovoreni ključ npr A=B, B=C, koju je prvi koristio Julie Cezar, pa do
današnje steganografije koja se koristi metodama integriranja podataka u sliku
ili neki drugi dokument. Cilj skrivanja podataka jest prikrivanje poruke, a to
se postiže koristeći jednu ili više od sljedeće tri taktike:
•
Nevidljivi
podatci: na primjer poruka je sakrivena
u prostoru tvrdog diska kojem operacijski sustav nema pristup .
•
Prerušeni
podatci: poruka je sakrivena u objektu
ili stvari koja izgleda nevažno, odnosno nepovezano kako bi poruka ostala
skrivena .
•
Nečitljivi
podatci: poruka se bez pokušaja
sakrivanja ili prerušavanja šifra, tako da ju nitko osim onoga za koga je
namijenjena ne može pročitati. Primjer ove metode jest kriptiranje;
primaoc ima ključ i zna gdje i kako pročitati poruku.
Ako su podatci skriveni, kako znati da su
uopće prisutni? Postoji toliko raznih načina skrivanja podataka, kako je za
njihov pronalazak potrebno koristiti razne alate i metode. Forenzički istražitelj treba tražiti
pokazatelje kako je netko koristio neku od metoda sakrivanja. Na primjer,
inženjerska kompanija sumnja kako njihov zaposlenik krade važnu intelektualnu
imovinu, šaljući ju preko kompanijine mreže novom kupcu. Istražitelji u potrazi
za digitalnim dokazima pregledom lokalnih tvrdih diskova ne nalaze ništa, no
prilikom pregleda kompanijinih dnevnika elektroničke pošte pronađu dva
elektronička pisma s fotografijama u prilogu, poslanima od strane
osumnjičenika. Kada se steganografskim putem sakrivaju podatci unutar drugih
dokumenata, veličina istih poraste, pogotovo ako su slike u pitanju. Koristeći
algoritme za detekciju steganografskih poruka, istražitelji otkriju kako su u
slikama skriveni planovi novog projekta kompanije.
Kriptiranje i kompresija
Formalna definicija kriptografije
glasi: kriptografijom se pronalaze načini i skrivaju informacije s
ciljem zaštite njihova čitanja bilo koga, osim osobe za koju su
namijenjene.
U računalnoj forenzici, najčešće se pojavljuju dva tipa modifikacije:
kriptiranje i kompresija. Obije metode koriste algoritme koji mijenjaju
inicijalne podatke.
Kriptiranje: čitki se tekst, podatak, poruka ili bilo koji drugi tip
dokumenta, kriptira koristeći algoritam i tajni ključ, kako bi nastao kodirani
podatak. Uz pomoć ključa šifre kodirani podatak ponovo postaje čitljiv tekst.
Kriptiranje ima samo jednu svrhu; učiniti podatke nečitljivima za sve osim
namijenjenog primatelja. Kriptirane podatka prilično je jednostavno uočiti jer
imaju slične strukture dokumenata ili ekstenzija.
Dva se tipa
kriptografskih metoda najčešće koriste:
·
Asimetrična: ovaj sustav
koristi dva ključa, javni i tajni. Javnim se ključem neke osobe kriptiraju
podatci, a primaoc poruke svojim tajnim ključem
dekriptira poruku.
·
Simetrična:
ovaj sustav koristi samo jedan ključ, koji dijele primaoc i pošiljatelj, on se
koristi za kriptiranje i dekriptiranje podataka, što olakšava kompromitiranje
njegove sigurnosti. Simetrični ključevi općenito su kraći i lakše se probijaju.
Kompresija:
Glavni cilj ove metode jest smanjiti
veličinu originalnog dokumenta, te kao rezultat smanjenja dokument postaje neprepoznatljiv
u usporedbi s originalnom formom, iako je sam razlog kompresija podataka, a ne
njihovo skrivanje.
Metode skrivanja podataka
Postoji
toliko načina skrivanja podataka, da je nemoguće sve navesti, no u nastavku su
ukratko opisani oni najčešće korišteni. Svaka od ovih taktika, s iznimkom
steganografije, poprilično se jednostavno otkriva kada se primjenjuju
pojedinačno, te se do skrivenih podataka
može doći korištenjem specijaliziranih alata. Pravi problemi nastaju kada
lukavi korisnici kombiniraju tehnike skrivanja podataka i prikrivanja svojih
akcija. Na primjer netko kriptira podatak koristeći asimetričnu kriptiranje kao
što je PGP, i tada umetne dokument u audio dokument koristeći stegenografski
program.
Ekstenzije
dokumenata
Popularna i
uvelike korištena metoda skrivanja podataka jest mijenjanje njihove ekstenzije
na kraju imena. Otkrivanje promjene ekstenzije obavlja se usporedbom zaglavlja
ispitivanog dokumenta s zaglavljem dokumenta istoga tipa za koji je istraživač
siguran kako ima ispravnu ekstenziju. Zaglavlje dokumenta niz je bitova
smješten na njegovom početku, te pomoću njegova čitanja programi otkrivaju mogu
li otvoriti dokument. Čak i kada je ekstenzija dokumenta promijenjena, program
za koji je originalno bio namijenjen i dalje može otvarati dokument, s druge
strane kada se promijeni zaglavlje dokumenta, program ga više ne prepoznaje.
Zaglavlja je
moguće mijenjati Hex editorima, programima koji doslovce čitaju podatke bit po
bit, bez obzira koje su ekstenzije.
Skriveni
dokumenti
Svi
operacijski sustavi dodjeljuju atribute dokumentima. Specifičan tip atributa
jest mogućnost skrivanja dokumenta, ili preciznije, mogućnost označavanja
dokumenta, datoteke kao skrivene, što se može poistovjetiti s brisanjem,
skriveni dokumenti su isto toliko skriveni koliko i obrisani dokumenti
obrisani, što je detaljnije objašnjeno u daljnjim poglavljima.
Skriveni
dijeljeni prostori
Hidden
shares dijeljena su
mrežna područja gdje se pohranjuju podatci, no dijeljena područja su sakrivena,
tj nedostupna. Ona se mogu nalaziti i na udaljenim računalima, te mogu biti
zaštićena lozinkama.
Alternativni
tokovi podataka
Neuobičajeni
koncept pohrane podataka metodom alternativnih tokova podataka (eng. Alternate data streams, kratica ADS)
započeo je s Windowsima NT, uveden kao zakrpa kompatibilnosti za Macintosh HFS
sustav. Implikacija ove zakrpe je kako se podatci mogu prikačiti na postojeće
datoteke bez mijenjanja njihovih
atributa, s iznimkom vremenske oznake. Ovi podatkovni tokovi omogućuju
asocijaciju višestruke forme podataka sa datotekom ili dokumentom. Na ovaj se
način može sakriti velike količine podataka, zbog toga što se ne otkrivaju
naredbom DIR, i veoma malo antivirusnih programa može otkriti korištene ADSa.
Jedan od slobodnih alata na webu koji otkriva prisutnost ADS skrivenih
datoteka jest Pointstone.
Slojevi
Najjednostavniji
primjer koji demonstrira primjenu slojeva (eng. Layers) jest postavit sliku
preko texta u desktop publishing programu. Na prvi pogled može
se vidjeti samo slika, nakon pomicanja slike vidljiv je tekst. Još jedan
jednostavan primjer jest mijenjanje teksta dokumenta u boju pozadine.Ukoliko
istražitelj prilikom pregleda naiđe na prazan dokument, preporuka je ispisati
ga jer fizička kopija može sadržavati
informacije nevidljive u digitalnom
obliku.
Steganografija
Steganografija
(eng. Steganography, kratica Stego) predstavlja kompleksnu verziju uslojavanja
i skrivanja podataka. Riječ Stego odnosi se na prikriveno pisanje,
kao što je nevidljivom tintom. U digitalnom svijetu, ova metoda uključuje
skrivanje poruka unutar slika, glazbenih
ili video isječaka. Problem otkrivanja steganografskih poruka leži u
tome što postoji velik broj algoritama i
steganografskih alata. Ako istražitelj ne zna kojim se alatom
osumnjičenik služio, neće biti u stanju izvući
skrivenu informaciju, no u kasnijim je poglavljima objašnjen postupak
otkrivanja steganografskih poruka u fotografijama, omogućujući time
istražiteljima barem potvrdu kako zbilja postoji skrivena informacija u slici
koju analiziraju. Još jedan način provjere postoje li na računalu poruke
sakrivene steganografskim alatom, osim same provjere postoje li takvi alati na
računalu, je traženje duplikata dokumenata, slika, audio i video zapisa. Velik
broj dupliciranih datoteka pokazatelj je kako je vjerojatno na računalu korisnik skrivao informacije steganografskim
alatom, te nemarno ostavio originale na disku. Tip pronađenih dokumenata može
ukazivati na to koji je steganografski
alat korišten, jer neki rade samo s određenim tipom podataka.
Zaobilaženje i uklanjanje zaštitnih mjera
Prilikom
pokušaja dešifriranja, izvlačenja ili otključavanja podataka, koristi se
nekoliko standardnih metoda za zaobilaženja ili probijanja lozinki kao što su
probijanja grubom silom, napad rječnikom, rainbow
napad, te provjerom cache memorije
jer neki operacijski sustavi tamo privremeno spremaju lozinke...
Preporučuje
se pokušaj probijanja
najjednostavnijih lozinki: malo
ljudi u toj mjeri mijenja svoje lozinke
da probijanje ili pronalazak jedne neće voditi otkrivanju ostalih. Kada korisnik na webu sačuva svoju lozinku i
korisničko ime, do njih se može doći pregledom catch smeća alatima kao što su Kain&abel.
No
čak i ako istražitelj nije u mogućnosti probiti ili pronaći lozinku, ovisno o
aplikaciji, moguće je doći do nekih informacija. Aplikacije kao što su procesori riječi, baze podataka, i
proračunske tablice, često čuvaju svoje podatke u formatu koji je čitljiv
pomoću hex editora. No treba uzeti u obzir kako u hex editorima nema
formatiranja, stoga većina podataka može biti nerazumljiva zbrka znakova, no
dijelovi mogu biti čitljivi.
Application specific integrated circuit (kratica ASIC) jedan je od najefektivnijih
načina probijanja kriptiranih sadržaja.
Računalni čipovi ASIC specifično
su programirani za dešifriranje određenih tipova kriptiranja. Ovakve čipove
uglavnom posjeduju vladine agencije, a učinkovitost im je neupitna, 40-bitni
ključ pronađe u roku od nekoliko
sekundi.
Mehanizmi za softversko samouništenje najteži su za
otkrivanje, no oni ne bi trebali biti problem, ukoliko se analiza obavlja na
radnoj kopiji. Sustav za samouništenje su programi koji uništavaju dokaze ako je zadovoljen skup parametara, kao što su
utipkavanje krive lozinke ili pogrešnog korisničkog imena više od dozvoljenog
broja puta.
3.3
Analiza
digitalnih dokaza
Metoda
analize ovisi o tipu forenzičke istrage koja se provodi; računalna, mrežna,
forenzika elektroničke pošte, mobilnih telefona. Forenzička slika zapravo je
jedan dokument, a takav format
omogućuje jednostavnu pretragu ključnih riječi kako bi se pronašlo
informacije, ili pregledalo umanjene sličice (eng.thumbnail) slika koje su smještene na originalnom disku.
Kada ljudi
čuju pojam računalna forenzika, poistovjete ga s kopanjem po podatcima
osumnjičenog, čitajući dokumente, memorandume, elektroničku poštu, instant
poruke, povijest posjeta internet stranicama, financijske dokumente,
fotografije i druge informacije. Sve prijašnje akcije, pronalaska i
prikupljanja podataka, bile su priprema za analizu i pregled dokaza.
Analiziraju se forenzičke radne kopije pohranjene na medijima za pohranu koje
je jedino moguće čitati kako bi se izbjeglo mijenjanje ili kontaminacija. Cilj
analize jest pronalazak i povezivanje činjenica, njihova interpretacija te
prezentacija zaključaka i pronalaska.
Nakon
ispravnog kreiranja forenzičke slike, istražitelju preostane potencijalno
velika količina podataka, od koje neznani dio može sadržavati informacije važne
za istragu. Kako ručna pretraga dokument po dokument u većini slučajeva nije
praktična, niti izvediva u razumnom vremenskom roku, preporučuje se sljedeća
strategija pregleda podataka:
·
Postavljanje pitanja i promatranje: ukoliko
istražitelj nije uključen u istragu od samog početka, treba prikupiti osnovne
činjenice i elemente slučaja, što se očekuje od istrage i na što se sumnja.
Kada je to moguće, preporučuje se razgovor s nadređenim, kao i osumnjičenim
osobama u svrhu smanjenja kriterija pretrage po podatcima.
·
Strategija pretrage mora uključivati liste ključnih
riječi i traženih pojmova: ovisno o
slučaju, nekada je dovoljan pretraga slika, elektroničke pošte ili mrežnog prometa.
·
Pregled digitalnih
dokaze odvija se prema strategiji razvijenoj u prošlom koraku: kako se
nailazi na nove dokaze ključne se riječi ili lokacije traženja mogu mijenjati.
Tragovi mogu voditi do lokacija ili dokaza koje nisu uzeti u obzir definiranjem
područja pretrage u koraku 2.
·
Formulacija objašnjenja, interpretacija pronađenih
dokaza, te izvlačenje zaključaka: istražiteljeva je zadaća objasniti što i kako
se dogodilo, a što svakako nije.
·
Preispitivanje zaključaka i metoda: uzimajući u
obzir pronađene dokaze, poželjno je preispitati metode i rezultate, te moguće
propuste.
·
Izvještaj o
zaključcima i pronađenim dokazima.
Niti jedan
alat za analizu ne može interpretirati digitalne dokaze ili doći do traga koji
spaja digitalne dokaze s elementima slučaja, to je glavna zadaća istražitelja.
Forenzički
se softver može koristit za strukturiranje upita te katalogizaciju rezultata,
no završni rezultat ovisi o istražitelju. Istražitelj postavlja upite nad
forenzičkom slikom sustava na strukturiran način. Iznimke su slučajevi kada treba pregledati malenu
količinu podataka ili istražitelj na raspolaganju ima neograničenu količinu vremena.
Efektivnost upita povećava se boljim poznavanjem i razumijevanjem elemenata slučaja, karakteristika zločina te
uključenih pojedinaca. Općenito, događa se kako među tisućama elektroničkih
poruka samo nekoliko njih sadrži važne informacije, čak ako istražitelj pronađe
nekolicinu, ne može biti siguran kako ih je pronašao sve, stoga pretragu mora provoditi racionalno i logično.
Strategije pretrage podataka često se osporavaju stoga se preporučuje detaljno
dokumentirati svaki korak, protokole pretrage, procedure, liste pretrage i
objasniti razloge poduzimanja određenih koraka. Pretraga po ključnim riječima
može biti problematična, zbog toga što se za pronalazak određenih informacija
mora postaviti dovoljno precizan upit, ali u istu ruku dovoljno općenit, kao se
ne bi izuzelo povezane podatke. Pretrage se provode u više navrata, s
modifikacijama lista pretraživanja [12].
3.3.1
Definiranje
liste pretrage
Rezultati istrage
ovise o listi pojmova za pretragu. Nepouzdanosti u listi mogu se reducirati što
većim znanjem činjenica o:
•
Upletenim
osobama: optuženik, tužitelj, mogući motivi koji daju uvid u
kontekst pretrage.
•
Okolnosti:
vremenski slijed aktivnosti i okolnosti
može pomoći prilikom uklapanja dokaza u cijelu priču.
•
Karakteristike
zločina: istražitelj treba biti upućen
u područje kojim se bavi istraga kako bi mogao interpretirati i povezati
pronađene dokaze, ukoliko ne razumije područje istraživanja, poželjna je
suradnja s osobom upućenom u NR računovodstvo, ukoliko se istražuje slučaj i
/ili dokazi povezan s tom temom.
•
Korištenje
iskaza (eng. deposition): iskaz
je naziv za svjedočenje pod prisegom uz prisutnost službenika suda, ali ne na
sudu.Izjave daju svjedoci koji mogu pridonijeti
istrazi ili posjeduju ključno
znanje o nekom od sudionika ili događaja, te stručnjaci koji daju svoje
mišljenje o nekom dijelu događaja ili pronađenih dokaza. Transkripti tih izjava
odličan su izvor pojmova pretrage, imena, datuma, i drugih informacija
3.3.2
Korištenje
forenzičkog softvera prilikom pretrage
Za
identifikaciju datoteka koje je potrebno pregledati koriste se kolekcije
forenzičkih alata. Iako se njihove
pretraživačke mogućnosti poboljšavaju, sami alati ne mogu provesti pregled i
interpretaciju pronađenih datoteka. Prilikom procesa akvizicije alat stvara
indeks pojmova koji predstavljaju osnovnu jedinice pretrage. Pojam može biti
samo znak ili skupina znakova, alfanumeričkih ili numeričkih, s razmacima na
obije strane. Indeksiranje produžuje vrijeme potrebno za akviziciju slike,
ali pojednostavljuje i ubrzava pretragu
i analizu.
Postoje dva
tipa pretrage po ključnim riječima:
·
Opcija
proširenja koja se odnosi na riječi:
-
Korijen riječi (eng. stemming):Pretraga po
varijacijama korijena tražene riječi
- Sinonimi: pretraga za sinonimima traženog pojma .
- Homonimi: pretraga po riječima koje zvuče slično kao traženi pojam.
- Fuzziness: pretraga s različitim načinima pisanja ili čestim pogreškama prilikom
pisanja traženog pojma ili riječi. Ovaj
tip pretrage ima smisla s imenima,
prezimenima, imenima gradova i tvrtki, te ostalih vlastitih imenica .
·
Opcija
ograničavanja pretrage koja se primjenjuje na vremenske okvire i veličine
pretraživanih podataka
- Raspon datuma kada je
dokument stvoren, odnosno zadnji puta sačuvan, ili oboje itd.
- Veličine datoteka ili
raspon veličina traženih odnosno broj traženih dokumenata Pretraga uz pomoć
Boolove logike(I, ILI, NILI). Svaki forenzički softver posjeduje specifične
ugrađene metode pretrage koje koriste boolovu logiku.
- Pojmove je moguće
povezati korištenjem boolovih operatora. Kako bi se stvorio traženi izraz ili
moglo filtrirali rezultate.
3.3.3
Preuzimanje
rizika
Metode i
izbori pretrage temelje se na
pretpostavkama. Ako su te pretpostavke krive, tada su i rezultati. Prilikom
pretrage postave se četiri glavne pretpostavke:
·
Osoba koja je pisala poruku ili dokument nije
koristila sleng ili kodne riječi kako bi izbjegla otkriće;
·
Dokaz nije nitko podmetnuo na istraživano
računalo;
·
Na računalo nije bilo slučajno skinutih
dokumenata za koje korisnici nisu znali;
·
Računalo nije kompromitirano zloćudnim
programima, zbog kojih bi bilo ranjivo.
Zbog tih
razloga istražitelj mora provesti vizualnu inspekciju sadržaja datoteka na
forenzičkoj slici. Do tragova se može doći pregledavanjem thumbnail slika ili čitanjem elektroničke pošte, pregled dokaza
iterativan je proces. Dokaze na koje se naiđe analizom prikupljenih podataka
mogu pomoći prilikom pretrage po ključnim riječima i obrnuto. Forenzički
softver omogućava pregled sadržaja datoteka, čak i ako su bili obrisani, osim u
slučaju da su podatci prebrisani. Alat
organizira datoteke prema kategorijama i statusu, te pušta korisniku na izbor
pregleda samo određenih elemenata ukoliko je to dovoljno. Kategorije na koje
većina alata razlaže podatke su:
·
Direktoriji s elektroničkim porukama;
·
Dokumenti u slack prostorima (eng. Slack space Documents);
·
Kriptirane datoteke proračunskih tablica
(eng. Spreadsheets Encrypted files);
·
Baze podataka izbrisanih datoteka;
·
Grafičke datoteke iz Recycle Bina;
·
Izvršni Data-carved
programi.
Data-carved dokumenti
su dokumenti sastavljeni od podatak pronađenih u nealociranim datotečnim prostorima. Data-carving alati pretražuju
nealocirane prostore tražeći informacije o zaglavljima, i moguće footerima, poznatih tipova dokumenata,
te potom rekonstruiraju taj blok podataka. Sami dokumenti ne postoje, čak niti kao izbrisani, stoga se
moraju „izrezbariti“ iz tog prostora.
Kada postoji
velika količina podataka, odvjetnici, vlasnici, naručitelji istrage mogu
zahtijevati da se provede data sampling tj.
provjera samo dijela podataka, ako taj slučajni dio podataka ne donese
očekivane rezultate, nadležna osoba može obustaviti daljnju istragu. Na primjer
ako uzorak podataka pokaže kako važan tip dokumenta ne postoji za određeno
vremensko razdoblje, veoma je vjerojatno kako nije potrebno nastaviti pretragu.
Podmetnute
dokaze teško je uočiti, važan aspekt te provjere jest ne brzati s zaključcima.
Jednostavna je pogreška završiti istragu nakon što je pronađen dokaz na
osumnjičenikovu računalu, no takva akcija može dovesti do impliciranja krive
osobe. Svi se rezultati moraju verificirati; na primjer provjera postoji li na
istraživanom računalu program ili mogućnost otvaranja, ispisa, mijenjanja
ili pokretanja pronađenih dokaza.
Poželjno je utvrditi i je li osumnjičenik imao pristup računalu u
pretpostavljanom vremenu kriminalnih radnji, datuma na inkriminirajućim
dokumentima, slikama, kao i provjeriti postavke sata, vremenske zone i datuma
računala u slučaju da nije ispravno. Ukoliko računalo ne koristi biometričke
uređaje za verifikaciju i autentifikaciju korisnika prilikom registriranja na
računalo kao što su otisak prsta, ili dlana, istražitelj ne može biti siguran
kako je upravo osumnjičenik bio na računalu
u to vrijeme. Iako bi korisničko ime i lozinka trebali garantirati
upravo identitet korisnika, to najčešće nije slučaj. Zaposlenici često ostave
svoja računala prijavljena, dijele korisničke račune i lozinke.
Istražitelj
može izvijestiti koje je slike pronašao u datoteci, ali možda neće biti u
mogućnosti otkriti i kao je ta slika tamo dospjela, isto tako recimo
inkriminirajući dokazi iz povijesti
surfanja korisnika, ne dokazuje kako je baš taj korisnik i počinio to za što ga
se tereti, ali u najmanju ruku baca određenu sumnju na njega. Digitalni dokazi
nekada ne mogu dokazati kako je zločin počinjen, ali mogu potvrditi motivaciju
ili namjeru kako je osumnjičenik namjeravao izvesti to za što ga se tereti [8].
4. Taksonomija digitalne
forenzike
Računalnom forenzikom otkrivaju se
tragovi koji spajaju osobe ili
organizacije s istraživanim dokazom.
Bilo da se radi o elektroničkoj poruci, chat razgovoru, podatcima skrivenima u
nealociranom prostoru ili dokumentima
istražitelji pronalaze inkriminirajuće bajtove podataka, koristeći ih
pri sastavljanja tijeka i vremenske
linije događaja, a ponekad motiva i počinitelja istraživane situacije.
Računalna se forenzika dijeli na šest područja, detaljnije opisanih u nastavku.
4.1
Forenzika
elektroničke pošte
Elektronička se pošta kao dokazni materijal
pojavljuje u većini civilnih kao i kriminalnih forenzičkih istraga.
Elektronička pošta i elektronička pošta zasnovana na internet poslužiteljima
(eng. Web based e-mail, kratica Web mail) širi se veoma brzo, te
jednostavno može završiti na računalu
korisnika kojem nije namijenjena.
Kada je Ray Tomilson 1971. godine putem mreže
poslao prvu elektroničku poruku, nije ni slutio kako će njegov izum deset
godina kasnije u kombinaciji s osobnim računalima i internetom prerasti u
globalni način komuniciranja; osobnog kako i poslovnog, zabave, načina razmijene
podataka, ali i nezamjenjiv izvor digitalnih dokaza. Elektronička pošta
zasnovana na internet poslužiteljima
veoma je korisna prilikom istrage. Na primjer ako osumnjičenik ima račun
na Google mail poslužitelju, postoji mogućnost da se uz odgovarajuća dopuštenja
pronađu čak i obrisane poruke, jer
Google svojom politikom o privatnosti korisnika ne garantira brisanje poruka na
rezervnim backup sustavima.
Svaka
elektronička poruka šalje se kao niz
paketa veličine bajta. Prilikom transporta na mreži, svaki od tih paketa sadrži
sljedeće elemente:
•
Izvorišnu
adresu: IP adresu računala
pošiljatelja, osim u slučaju kada je ta IP adresa prikrivena.
•
Odredišnu
adresu : IP adresu računala.
•
Payload: podatke ili poruku.
Usmjerivači
prosljeđuju pakete prema svojim tablicama usmjeravanja sve do krajnjeg
odredišta.
S
forenzičkog stajališta, klijent/poslužitelj sustavi e-pošte najbolji su za
traženje informacija zbog toga što se poruke skidaju na korisnikovo lokalno
računalo, tj tvrdi disk, što olakšava
istragu, jer forenzičar već ima pristup mediju za pohranu. Pristupa se i
poslužitelju zbog njegovih dnevnika aktivnosti e-pošte, te mogućih novih
poruka. Produkcijski poslužitelji
elektroničke pošte nije moguće isključiti radi istrage, stoga se prvo
pregledavaju sigurnosne kopije, te se jedino kao zadnjoj mogućnosti pristupa
isključenju poslužitelja [12].
4.1.1
Analiza
elektroničke pošte
Elektronička poruka sastoji se od dva dijela:
zaglavlja i tijela poruke. Iz
zaglavlja je moguće saznati izvorišnu i odredišnu adresu, tj pošiljaoca
i namijenjenog primaoca, a tijelo
poruke sadrži tekst poruke
Većina klijenata e-pošte po originalnim postavkama
prikazuju samo osnovne informacije
u zaglavlju:
·
Od: pošiljateljeva adresa. Ovo polje
može biti zamaskirano, tj kao pošiljatelj može bit naveden netko drugi,
dok je prava pošiljateljeva IP adresa prikrivena.
·
Za: primateljeva adresa, koja također može biti
prikrivena, odnosno zamaskirana.
·
Tema: ponekad je ovo polje prazno,ili sadrži
zavaravajuće informacije.
·
Datum: zabilježeno s računala pošiljatelja,no može
biti pogrešno , ukoliko je sat na njegovom računalu pogrešno postavljeno
Kako
istražitelj zapravo ne može vjerovati osnovnim
informacijama u zaglavlju, mora proširiti informacije koje se prikazuju
u njemu. Prošireno zaglavlje sadrži mnogo više informacija nego što je
usmjerivačima zapravo potrebno da dostave poruku do svog odredišta. Najkorisnija
informacija u proširenom zaglavlju zasigurno je IP adresa izvora, odnosno
domene. Pomoću ove informacije moguće je ući u trag pošiljaocu poruke. Prvi
poslužitelj elektroničke pošte kroz koji e-poruka prođe, dodijeli joj
jedinstveni identifikacijski broj, te ukoliko istražitelj pristupi dnevnicima
poslužitelja prije nego li se tražene informacije prebrišu, moguće je pratiti
stvarno vrijeme i smjer prolaska poruke
kroz mrežu. Osim pregleda zaglavlja i tijela poruke, potrebno je provjeriti i
ostale potencijalne izvore informacija:
·
Privitke
s ekstenzijama kao što su .doc, .xls, ili slike.
·
Ljude
koji su navedeni u cc (eng. Carbon copie,
Skrać cc.) ili bcc poljima.
·
Ljude
kojima je poruka proslijeđena.
·
Originalnu
poruku ili niz poruka na koje je ova odgovor, ili odgovor na istraživanu
poruku.
Ne
smije se pretpostaviti kako je prijavljeni korisnik poslao sve poruke;u mnogim
radnim okruženjima suradnici dijele
računala i lozinke, tako da mnogi imaju pristup istraživanom računalu
Proces forenzičkog izvlačenja e-poruka u
okolini klijent/poslužitelj slijedi općenite korake. Većina sustava za elektroničku poštu koriste
SMTP Simple Mail Transfer Protocol, POP Post Office Protocol,
ili IMAP Internet Message Access Protocol. Korištenjem ovih protokola
transport e-poruka postaje standardiziran. Izazov jest izvući e-poruke iz
raznih klijentskih aplikacija za e-poštu pomoću forenzičkih alata. Dva najčešće
korištena klijentska softvera:
·
Outlook: izuzev uobičajenih mogućnosti aplikacije za e-poštu, sadrži kalendar, listu
zadataka (eng. Task list), te
upravitelja kontaktima (eng. Contact
menager). Samim time pruža detaljan uvid u svakodnevnu rutinu
osumnjičenika. Za razliku od Outlok Expressa , Outlook sprema sve podatke
unutar jednog korisničkog identiteta, u dokumentu s extenzijom .pst kojem je
moguće pristupiti korištenjem forenzičkih alata kao što su FTK, i EnCase.
·
Outlook Express: čuva podatke u dokumentu ekstenzije .dbx, pregled je moguć
odgovarajućim preglednikom. Nadalje svaki korisnički račun stvoren u Outlook Expressu
posjeduje dodijeljenu heksadecimalnu
sekvencu brojeva, koje Microsoft koristi prilikom identifikacije računa. Ovisno
o verziji Windows operacijskog sustava, ti su identiteti korisničkih računa
pohranjeni u poddirektorijima /Dokumenti i postavke.
U Outlook
Expressu, Outlooku, AOL, Eudori i Thunderbirdu, e-poruke se pohranjuju lokalno
na istraživanom računalu, što znatno olakšava pregled i pretragu. Unatoč tome,
pregledom dnevnika mail poslužitelja
dolazimo do informacija koje povezuju poslužitelj i e-poruku, pregledom
identifikacijske poruke.
4.1.2
Ekstenzije
dokumenata elektroničke pošte
U slučajevima kada
je potrebno dohvatiti samo dokumente
potrebne za pregled e-poruka, ili kopirati neki dokument sačuvan unutar
elektroničke pošte, moguće je koristiti sustav na istraživanom računalu
ili specijalizirani softver kao što
je Outlook Extract Pro ili Outlook
Export. Ispravniji, sigurniji i jednostavniji način je korištenje forenzičkih
alata kao što su EnCase ili FTK, s ugrađenim preglednicima koji omogućavaju
dohvat sadržaja baze podataka, te njihov
eksport na druge medije za daljnju analizu.Forenzički alati automatiziraju
proces dohvata podataka, te ih je jednostavnije analizirati i generirati
izvještaj
Tablica 4.1 Ekstenzije dokumenata za česte klijente e-pošte
|
Klijent elektroničke pošte |
Ekstenzija |
Tip dokumenta |
|
AOL |
.abi ili .arl .aim ili .bag |
Organizatorski dokument Instant Mesenger |
|
Eudora |
.mbx |
Baza poruka |
|
Outlook Express |
.dbx .dgr .eml |
Komprimirana baza podataka Faks informacije e-poruke e-pošta |
|
Outlook |
.pab .pst .wab |
Osobni imenik Komprimirani osobni dokument Imenik |
|
Thunderbird |
.msf |
Dokument sažetaka poruka |
Forenzički softver
može otvoriti gotovo sve formate e-poruka, te omogućuju:
·
Preciznu
i učinkovitu pretragu poruka;
·
Dohvat
informacija zaglavlja;
·
Ispis
cjelovitih e-poruka, uključujući zaglavlja, adresara;
·
Grupiranje
poruka po podatcima, ili klasifikaciji podataka.
Sve se ove
akcije provode na radnim kopijama originalnih podataka.
4.1.3
Analiza
elektroničke pošte zasnovane na internet poslužiteljima
Za osobnu se
komunikaciju često koriste Web servisi za elektroničku poštu, kao što su
Google, Hotlmail, Yahoo. Ovi se servisi koriste bez uporabe softvera klijenata
elektroničke pošte, no zapravo predstavljaju
klijent/poslužitelj sustav. Web
mail sustav predaje e-poruku
koristeći SMTP protokol, a dohvaća koristeći POP ili IMAP protokole. Web pošta
ne sprema se na lokalno računalo, osim ako to korisnik ne zatraži. Pristup
računu e-pošte na poslužitelju ili dobava podataka o korisničkom računu od
strane pružatelja usluga znatno smanjuje količinu posla forenzičkom
istražitelju. Ako pristup nije dozvoljen, do web mail poruka može se doći pregledom radne i cache memorije. Kada korisnik provjerava poruke, ili sastavlja
novu, operacijski sustav sačuva podatke s ekrana na tvrdi disk, pogotovo ako
korisniku treba duže vrijeme da sastavi poruku. Najbolja mjesta za traženje web mail poruka na lokalnom računalu su:
·
Područje
privremenih datoteka kao što su
sustavski swap prostor ili cache
memorija.
·
Nealociran
prostor, nakon brisanja privremenih datoteka i dokumenata.
Forenzička
dobava podataka iz privremenih datoteka dugotrajan je proces, čak i ako se
koristi forenzičke alate, zbog toga što se pokušava rekonstruirati internetske stranice iz neformatiranog
digitalnog prostora.
Web mail na lokalnom računalu zapravo ima oblik web stranice s funkcionalnošću
e-pošte, dakle traže se dokumenti ekstenzija .html. Kako pregled svih web
stranica kojima je korisnik pristupao nije vremenski prihvatljiv pothvat,
njihov se broj može znatno smanjiti ako se uzme u obzir:
·
Korištenje
ključnih riječi i fraza; na primjer osumnjičenikova adresa elektroničke pošte, te
fraze vezane uz istraživani incident;
·
Pregled
servisa koje osumnjičenik koristi (Google, Hotlmail...).
4.1.4
Privremeni
dokumenti
Operacijski
sustavi privremene dokumente stvaraju
za aplikacije koje šalju i
primaju podatke preko mreže. Ti se podatci prvo pohranjuju u radnu memoriju, a
kada se RAM popuni, OS pomiče podatke niže na listu prioriteta podataka koji su
potrebni aplikacijama, te ih zapisuje na tvrdi disk. Ne postoji jedinstveno područje gdje se
spremaju privremeni dokumenti jer neke
aplikacije stvaraju dodatne privremene datoteke uz one što ih stvara OS.
Aplikacije koje nemaju mogućnost privremene pohrane podataka, prepuštaju
operacijskom sustavu da ih pohrani
koristeći swap datoteke ili virtualnu memoriju. Kada
aplikacija zatreba privremeno pohranjen podatak, OS ga dobavlja aplikaciji te
briše s tvrdog diska. Kako je swap
datoteke samo izbrisan, do podataka je
moguće doći, jer još uvijek fizički postoje na disku ukoliko novi nisu zapisani
preko njih.
Internet
Explorer ima mogućnost pamćenja stranica kojima se pristupilo putem Web
pretraživača. Iako je broj dana koje Explorer čuva te informacije prepušteno
korisniku na regulaciju, te informacije ne nestaju nakon brisanja. Explorer
koristi index.dat dokument kako zbog
stvaranja baze podataka posjećenih stranica, cookiesa, te raznih drugih detalja vezanih uz korištenje
pretraživača. Iz index.dat dokumenta
moguće je izvući te podatke i rekreirati povijest surfanja korisnika praktički sve do trenutka
kada je korisnik prvi puta pristupio internetu na tom računalu i pretraživaču.
Mozilla i Opera koriste slične metode pohrane povijesti surfanja.
4.1.5
Instant
poruke
Kompanije
komuniciraju s korisnicima putem instant poruka, zaposlenici unutar kompanija
međusobno razgovaraju instant porukama (eng. Instant messaging, kratica IM), a veoma su rado korištene za osobne
razgovore. Osobe međusobno razmjenjuju poruke koje putuju preko poslužitelja, a
princip rada gotovo je identičan kao e-pošta, s glavnom razlikom, kako se odvija
u stvarnom vremenu. Neki od IM softvera pružaju mogućnost bilježenja povijesti
razgovora, no malo ljudi se odlučuje za tu opciju. Dijelove razgovora moguće je
pronaći na IM poslužiteljima, no cijele razgovore samo ako je uključena opcija
zapisivanja povijesti, ili ako se snima mrežni promet računala korištenog za
slanje IM poruka u vrijeme trajanja razgovora. Započele su se koristiti i nove
metode forenzike uživo, alati kao što su WebCase omogućuju djelomično forenzičko praćenje podataka u stvarnom vremenu
pohranjivanjem IP adresa i chat sesija, te ostale komunikacije putem internet
veze. WebCase proizvod je tvrtke
VereSoft .
4.2
Forenzika
podataka
Forenzika podataka koristi iste koncepte i
metode korištene za rekonstrukciju
oštećenih podataka i povrat izbrisanih podataka, uz dodatak write block alata i računanje hash vrijednosti zbog provjere
integriteta i autentičnosti podataka. Najveće zapreke forenzičkoj obradi
podataka predstavlja broj različitih
operacijskih sustava, kao i specijaliziranog sklopovlja s vlastitim načinom
upravljanja podatcima.
Područja mobilne i mrežne forenzike pronalaze
tragove podataka ili metapodatke dok oni prolaze kroz sustave, no većina se
traženih podataka nalazi u medijima za pohranu podataka istraživanog računala
kao što su tvrdi diskovi ili radne
memorije [12].
4.2.1
Tvrdi
disk
Osnovni
medij za pohranu podataka kod većine je
računala magnetni disk. Osnovni dizajn diskova nije se mijenjao desetljećima;
oni koriste magnetski materijal koji se polarizira pozitivnim ili negativnim
nabojem. Ova dva tipa polarizacije magneta omogućuju pohranu binarnih podataka
nula i jedinica kao magnetske naboje, te predstavljaju jednostavan način
pohrane velike količine podataka na
relativno stabilnoj fizičkoj platformi. Tvrdi diskovi ovog tipa sastavljeni su
od istih osnovnih elemenata strukture:
·
Glava
za čitanje: fizički element tvrdog diska koji čita i zapisuje magnetski
materijal lociran na metalnim pločama.Većina današnjih tvrdih diskova posjeduje
dvije glave, za istodobno čitanje gornje i donje površine ploče.
·
Staza:
kružno područje na ploči koje sadržava informacije.
·
Cilindar:
staze više ploča poslagane jedna iznad druge.
·
Sektor:
najmanja jedinica pohrane na mediju za pohranu podataka.Staze su podijeljene na
sektore, njihova veličina obično iznosi 512 bajta.
Veličine
tvrdih diskova variraju, ovisno o kombinaciji cilindara, glava i sektora (eng. Cyilinders, heads, sectors, kratica
CHS).
Basic Input Output System (BIOS) sam očitava standardne postavke
proizvođača za BIOS s tvrdog diska, te se korisnik ne mora manualno pobrinuti
za njih, no moguće je namjestiti nestandardne postavke samostalno. U slučaju da
računalo iz nekog razloga izgubi
specijalne postavke uređaja za pohranu, korisno je imati digitalni zapis pohranjen na nekom mediju van računala.
Kada istražitelj analizira računalo čije su postavke tvrdog diska nestandardne,
takav zapis izvor je informacija koji pomaže pri prikupljanju potencijalno
korisnih podataka. U nastavku slijede kratki opisi načina funkcioniranja
datotečnih sustava Microsofta, Applea i Linuxa, kao najčešće korištenih OS.
Microsoft OS
Najrašireniji
i najpopularniji OS današnjice. Windowsi
organiziraju podatke na tvrdom disku
koristeći sljedeće fizičke elemente:
·
Klaster
(eng. Cluster): Grupacija sektora
kojom se smanjuje broj zapisa potrebnih za praćenje smještaja datoteka na tvrdom disku. Što je veći disk, u klasteru
će biti smješten veći broj sektora, kako alokacijske tablice ne bi prerasle
razumnu veličinu. Danas uobičajena veličina klastera iznosi 32KB. Kako su
sektori definirani na sklopovskoj razini nazivaju se i fizički adresni prostor,
a klasteri koji su definirani na razini operacijskog sustava logički adresni prostor.
·
Particija
ili logički volume:Logički odjeljak
fizičkog uređaja za pohranu podataka. Ovisno o operacijskom sustavu, fizički
medij za pohranu podataka razdijeljen je na manje logičke jedinice kako bi OS
mogao funkcionirati ispravno, no u današnje vrijeme particioniranje je više korisnikova metoda organizacije
datoteka, nego limitacija od strane operacijskog sustava. Kada se tijekom
istrage naiđe na velik dio
neparticioniranog prostora na disku, preporučuje se detaljniji pregled jer neki
korisnici znaju privremeno obrisati podatke s diska kako bi ih prikrili.
·
Glavni
boot zapis (eng. Master Boot Record,
kratica MBR): područje na uređaju za pohranu podataka koje OS koristi kada
traži medij za boot prilikom uključivanja. Iako MBR ima nekoliko primjena,
glavna mu je zadaća pohrana informacija
o particijama definiranim na fizičkom tvrdom disku. MBR je smješten ispred prve
particije na disku u glavnom području
boot zapisa (eng. Main boot record area,
kratica MBRA). MBR sadrži i bootstrap
informacije, te jedinstvene identifikatore medija za pohranu koji se mogu
koristiti za praćenje prijenosnih memorija priključenih na računalu.
Windows
koristi dva datotečna sustava FAT i NTFS:
FAT (eng. File Allocation Table) originalan je datotečni sustav razvijen u Microsoftu.
Koristi se za organizaciju podataka na mediju za pohranu. OS koristi FAT sustav za lociranje datoteka
na računalu. FAT pokazuje na početni klaster dokumenata, a sadrži i imena datoteka,
vremenske i datumske oznake (eng. Time
and date stamps), imena direktorija, te njihove atribute.
Iako su FAT
sustavi po računalnim standardima već zastarjeli, korisno je znati osnovne
mehanizme njihova funkcioniranja. Mnogi stariji OS sustavi još se uvijek
koriste jer su stabilni i mogu raditi na jednostavnim računalnim sustavima. FAT
sustavi uključuju i mnogo neiskorištenog prostora, te su savršeni za sakrivanje
podataka. Na primjer dokument veličine 20Kb manji je od standardne veličine
klastera, višak prostora naziva se file slack. Ako veličina dokumenata
zauzima više od jednog klastera FAT sustavi povezuju klastere (eng. Cluster chaining); kraj jednog klastera
pokazuje na sljedeći klaster u lancu i tako sve do kraja. Pokazivanje
funkcionira unaprijed, ali ne i u suprotnom smjeru, dakle ne pokazuje na
prethodni klaster. Alati za forenzičku analizu mogu rekonstruirati obrisane
podatke. Kada se podatci zapisuju u FAT
datotečni sustav, lokacija klastera se koristi za identifikaciju logičke
lokacije dokumenta na mediju za pohranu podataka. Kada se podatak obriše FAT
sustav u tablicu upisuje heksadecimalni niz znakova E5, koji označava kako je
klaster slobodan za ponovnu uporabu. Forenzički alati pretražuju tablicu FAT
sustava za tim heksadecimalnim znakovima kako bi locirali obrisane podatke,
koji još uvijek fizički postoje zapisani
na disku. Ta se područja nazivaju
nealocirani prostor, zbog toga što nije dodijeljen niti jednom podatku na
uporabu, te je često popunjen s izbrisanim podatcima ili dijelovima starih
dokumenata. Forenzički softver najbolji je način automatiziranog pronalaska i
dobavljanja podataka iz nealociranih područja jer mediji za pohranu podataka
često imaju gigabajte nealociranog prostora, čija bi ručna pretraga trajala
danima, ako ne i tjednima.
NTFS mnogo
je složeniji sustav u usporedbi s FAT sustavima, te ima sljedeća svojstva:
·
Napredni
atributi dokumenata (eng. Enhanced file
atributes): NTFS uz standardne (read-only, arhiva,sustav te skriven) atribute dokumenata uključuje i indeksiran, komprimiran, i
enkriptiran. U NTFS sustavima povećana je kontrola pristupa nad datotekama i dokumentima
·
Alternativni
tokovi podataka (eng. Alternate data
streams): Ove se podatkovne strukture vezuju na postojeće dokumente.
Struktura podataka tipa ADS može se smatrati metapodatcima, ali isto tako mogu
biti neovisni izvori podataka. ADS podatci
spojeni su s glavnim podatcima, ali logički odvojeni, te mogu biti i
veći od podataka na koje su vezani. ADS podatci u potpunosti su nevidljivi
datotečnima sustavima i korisnicima.
Iako datotečni sustav zapravo ne zna kako ADS podatci postoje, oni mogu
zauzimati poprilično velik prostor, na dokumente veličine 2Kb može biti vezan stream veličine 20Mb.
·
Kompresija
dokumenata:NTFS dozvoljava transparentnu kompresiju podataka korištenjem LZ77
algoritam za kompresiju. Ovaj proces usporava računalni sustav, a ne pruža
dodatnu sigurnosnu prednost, stoga ga korisnici općenito ne koriste ukoliko
imaju prostora na disku.
·
Kriptiranje:
Sustav za kriptiranje dokumenata (eng Encrypting
File System, kratica EFS ) koristi asimetrični sustav kriptiranja,
korisnik posjeduje privatni ključ, a OS javni. Sustav za enkripciju kriptira, odnosno dekriptira podatke na
sustavskoj razini,i transparentan je korisniku koji je inicijalno kriptirao
podatke, asocirajući ključeve s informacijama korisničkog računa . Pristup EFS kriptiranim podatcima najlakši je korištenjem data
recovery agenta, što omogućava istražitelju resetiranja ili zaobilaženja
lozinki.
·
Dnevnici
promjena (eng. Journaling): ovaj
sustav na NTFS-u bilježi sve promjene na metapodatcima asociranim s dokumentima
na sustavu.
·
Shadow kopija: Ova NTFS aplikacija sprema slike dokumenata ili
datoteka u određenim vremenskim trenutcima, za kasniju korisnikovu ili uporabu
nekih aplikacija.
·
Mount points: Jedna od načina
dodavanja logičkog volumena NTFS sustavu
Prva velika
razlika između FAT i NTFS sustava jest ta da NTFS smatra sve objekte koji se
nalaze unutar datotečnog sustava dokumentima, uključujući MFT (eng.Master File Table). MTF je u NTFS
sustavu ekvivalent tablice baze podataka
u FAT sustavima. MTF adresira dokumente za NTFS sustav, no pohranjuje puno više
podataka u obliku metapodataka nego FAT sustavi. MTF sadrži informacije o dokumentu
kao što su vremenske oznake, adrese klastera, imena, sigurnosne identifikatore
(eng. Security Identificators, kraticaSID), atribute dokumenata, čak i
imena data stream podataka asociranih
s dokumentom. Jedna od većih prednosti NTFS sustava je ta da ako je podatak
manji od 800 bajta, cijeli može biti sačuvan unutar MFT tablice, samim time
neće zauzimati klaster i stvarati slack
file prostor.
Obrisanim se
dokumenata rukovodi na dva moguća načina:
·
Recycle
Bin briše dokumente korištenjem Windows GUI sučelja: dokumentu se mijenja ime,
i premješta ga se u Recycle Bin. Unese se zapis u Info2 zapisnik, on kontrolira
datoteke koje sadrže metapodatke kao što su putanja do njegove lokacije i
informacije o datumu i vremenu.
·
Datotečni
sustav označava klastere slobodnima za daljnju uporabu: NTFS sustav koristi
istu metodologiju kao i FAT sustavi kada su u pitanju obrisani dokumenti.
Klastere označe kao slobodne za novo korištenje, te promjene oznaku u MFT
tablici. Isto se događa kada korisnik isprazni Recycle Bin. U tom trenutku
datotečni sustav označi klaster dostupnim, a dokument smatra trajno izbrisanim,
a on time on postaje dio nealociranog
prostora.
Apple HFS
Razvijen u
kompaniji Apple sredinom osamdesetih godina. Ostao je u uporabi sve do prelaska
na Mack OS X koji je zasnovan na Unix operacijskim sustavima.
Hierarchical File System (kratica HFS) koristi podatkovne i resursne pokazivače za
odvajanje podataka i metapodataka
dokumenata. Aplikacija zapisuje u podatkovni pokazivač lokaciju
podataka, dok se u resursne pokazivače
zapisuje informacije kao što su ikone i izbornik.
HFS sustav
koristi katalog za lokaciju svih
dokumenata i datoteka na disku. Informacije potencijalno korisne istražitelju
nalaze se u dijelu katalog dokumenata
rezerviranom za zapise. Tamo su pohranjene informacije kao što su:
·
Identifikacija
čvora kataloga (eng. catalog node
identification, kratica CNID): HFS svakom dokumentu, datoteci i direktoriju na disku
dodjeljuje jedinstven broj;
·
Veličina dokumenata;
·
Vremenska oznaka: datum i vrijeme stvaranja,
modifikacije ili izrade kopije datoteke ili dokumenta;
·
Područje prostiranja ( eng. Extent): diskovna lokacija
prvog dijela dokumenata;
·
Fork:
Pokazivač na resursne pokazivače.
HFS sustav
koristi volumes za logičku
segmentaciju fizičkog medija za pohranu. Volume
može predstavljati dio ili cijeli medij za pohranu podataka. Dokumenti se
pohranjuju u logičke blokove veličine 512 bajta, a one koji premašuju veličinu
jednog bloka smještaju se u blokove alokacije; niz slijednih blokova. Kada je
podatak manji od veličine bloka ili alociranog prostora, na neiskorištenom se
prostoru nalaze „obrisani“ stari
podatci.
Linux/Unix
Linux OS koristi mnoge tehnike i koncepte datotečnih sustava starijih Unix sustava. U
Linux sustavu OS sve smatra dokumentom; uključujući sve sklopovske periferne
uređaje kao što su monitor ili memorija. Svi dokumenti imaju pridružena
svojstva, i atribute. Linux datotečni sustav koristi manje jedinice prostora za pohranjivanje,
kako bi se uštedilo na prostoru i smanjila količina neiskorištenog prostora. Najmanja
jedinica prostora pohrane naziva se blok. Početne veličine blokova su 512
bajtova, ali one variraju ovisno o veličini korištenog volume.
Linux sustav
sastoji se od četiri glavne komponente:
·
Boot
blok: Lokacija pohrane bootstraping
koda kojim se podiže Linux sustav
·
Podatkovni
blok: Logičke adrese podataka pohranjenih na disku
·
Inode:
Pokazivač na blok adrese podataka, povezuje podatkovne blokove te stvara indeks
sličan bazama podataka o informacijama vezanim uz dokumente ili direktorije.
Prilikom stvaranja svakog novog dokumenta ili direktorija Linux sustav stvara asocirani Inod koji sadrži sljedeće informacije;
adresu bloka dodijeljenog podatku,broj
blokova koje koriste dokument ili direktorij, broj poveznica do
dokumenta,identifikacijski broj korisnika i grupe.
·
Super
blok: Ekvivalent NTFS MTF-u , ili Apple HFS-u, vodi računa o inod
pokazivačima i o statusu svih blokova na
mediju za pohranu. Veličina blokova određuje količinu podataka koje je moguće
rekonstruirati jer veliki blokovi u praksi sadrže više neiskorištenog prostora,
s podatcima preostalim od prijašnjih zapisivanja.
Linux vodi
zapis o oštećenim i pokvarenim dijelovima diska u čvoru za neispravne blokove
(eng. Bad Block Inode kratica BBI).
BBI sadržava listu svih oštećenih i neuporabljivih sektora i blokova, no može
ga se modificirati da uključuje i funkcionalne blokove, te time efikasno
sakriti podatke. Ovom Inod-u moguće je pristupiti s root ili administrator
ovlastima.
4.2.2
Obrisani
podatci
Kada
korisnik obriše dokument, datotečni sustav postavi marker u sustav za
upravljanje datotekama, kako bi OS znao kako taj dokument više nije u tom
klasteru ili bloku. Ovim postupkom sustav logički obriše podatak iz svojih
zapisa, ali nije fizički obrisao binarne podatke s medija za pohranu. Ne
obavljanjem fizičkog brisanja OS ostavlja virtualno binarno arheološko
nalazište, veoma korisno forenzičkim istražiteljima. Što su tvrdi diskovi
veći, količina podataka preostalih od prijašnjih zapisa povećava se, jer
je sustavu na raspolaganju više prostora za pohranu, i više mu vremena treba da
ponovo dođe do mjesta na disku gdje je već nešto bilo zapisano. Datotečni
sustav nealocirani prostor smatra praznim i spremnim za daljnju uporabu, a u njemu se mogu nalaziti i
cached podatci. Na primjer, provjerom
Google pošte, slika ekrana u određenim trenutcima sprema se na disk i koristi se za ubrzanje pregleda internetske
stranice. Ovaj proces ima neželjen efekt čuvanja internetske stranice koju je
korisnik posjetio čak i nakon brisanja cache
dokumenta. U starijim datotečni sustavima kao što je DOS, nealocirani prostor
sadrži obrisane podatke, dok se u novijim verzijama operacijskih sustava
koristi dvostupanjski proces koji uključuje Recycle
Bin. Stoga se prije provjere nealociranog područja preporučuje pregled
Recycle Bina.
Dohvat obrisanih dokumenata
Forenzički
alati nakon pregleda diska sastavljaju listu obrisanih dokumenata. Na primjer u
listi se mogu nalaziti izbrisane slike, koje se još uvijek nalaze na mediju za
pohranu zajedno sa svim važnim metapodatcima i oznakama datuma i vremena.
Najbolji se rezultati postižu ako je dokument još uvijek čitav sadržan na disku
ili je bio zapisan u FAT ili MFT
tablicama.
Dohvat cached dokumenata
Kada
istražitelj želi pronaći i dohvatiti obrisane podatke koji su nastali kao
produkt „hvatanja“dokumenata kao što su catch dokumenti internet stranica ili privremeni catch dokumenti aplikacija, potrebna je
detaljnija ručna pretraga nakon uporabe forenzičkog softvera. Predloženi koraci
olakšavaju pretragu:
·
Pokrenuti
pretragu forenzičkim softverom, cilj je pronalazak svih referenci na ključne
riječi koje je istražitelj unio. Rezultat su sve internetske stranice koje
sadržavaju navedene ključne riječi
·
Ručna
pretraga po dobivenim rezultatima, uz
daljnju specifikaciju traženih pojmova i riječi; ovaj način pretrage
omogućuje pregled podataka koje bi forenzički alati za dohvat izbrisanih
dokumenata preskočili zbog nepotpunih zaglavlja, a koji mogu sadržavati korisne
informacije.
Dohvat obrisanih podataka iz nealociranih prostora
Prilikom pretraživanja oštećenih dokumenata ili fragmenata
dokumenata iz nealociranih područja, nije moguće provoditi standardnu pretragu
jer bi se neki dokumenti preskočili zbog na primjer nepotpunih zaglavlja, nedostatka dijela dokumenta ili ekstenzije. Nadalje takvi podatci obično
nemaju očuvane metapodatke zbog načina na koje aplikacije hvataju podatke.
Nekada se matapodatci mogu pronaći ugrađeni u samom dokumentu. Na primjer,
pretraga ključnim riječima može izgledati ovako; traži se Microsoft Word
dokument, a kao ključne riječi koristi se sekvenca zaglavlja MS Worda, i tema
dokumenta npr. kompanija za ekspresnu dostavu pošte. Metapodatci mogu biti
nepovratno izgubljeni na sustavskoj razini, ali moguće je da još uvijek postoje
na aplikacijskoj razini.
Dohvat podataka iz slack područja dokumenata
U slack
područjima dokumenata moguće je pronaći starije podatke, iako su im početci
podatkovnih blokova ili klastera prepisani s novim podatcima. Na primjer;
tipičan klaster sastoji se od dva različita dokumenta, gornji dio klastera
sadržava trenutno korištenu HTML informaciju, a drugi dio klastera stari
dokument s postavkama. Problem često stvara otvaranje pronađenih dokumenata jer
su im informacije zaglavlja prepisani s nekim novim podatcima. U tim slučajevima
postoje dvije opcije: ukoliko istražitelj zna o kakvom se tipu dokumenta radi,
može mu prilijepiti zaglavlje odgovarajućeg tipa na sam početak zapisa
dokumenta, ili ručno iskopirati podatke van formata. Oba se postupka provode
korištenjem hex editora i sličnih alata.
Neki su formati fleksibilniji i u većini slučajeva prihvate kopiranje
novog zaglavlja, kao što su grafički dokumenti i normalno prikažu čak i
djelomično očuvan dokument, no baze podataka odbijaju otvaranje i najmanje oštećenih podataka.
Nepristupačan prostor
Podatci se
mogu sakriti i u dijelove diska do kojih OS nema pristupa. Razlozi zbog kojih
OS nema pristupa nekim dijelovima diska mogu biti oštećenje ili
limitacija datotečnog sustava. Hex editorom moguće je pristupiti i promijeniti
konfiguracijske dokumente datotečnog sustava u dijelu koji kontrolira
označavanje oštećenih dijelova diska. Informacije se tada mogu pohraniti i
sakriti u dio diska koji je datotečni sustav prozvao oštećenim. Informacije je
moguće sakriti u dijelove medija za pohranu koje OS ne prepoznaje, veličine i
do 1GB. Ova su područje najčešće locirana
na fizičkom kraju medija, i podatci sačuvani na tom dijelu dostupni su
jedino hex editorom. Informacije koje se želi sakriti dovoljno je kopirati u
hex editor i sačuvati u nedostupan dio diska. Iako se ove metode skrivanja
podataka i dalje koriste, jednostavnije je i učinkovitije informacije kriptirati, nego modificirati
medij za pohranu i podatke.
4.2.3
Radna
memorija
Temeljni
cilj tehnologija korištenih u računalnoj forenzici jest konzistentnost podataka, tj prilikom istrage
i analize ne smije se mijenjati niti jedan bit originalnih podataka. Kada su
traženi dokazi smješteni u radnoj memoriji, ovaj je cilj nemoguće provesti u
djelo. Problem kod prikupljanja podataka iz radne memorije predstavlja
činjenica da ukoliko na istraživanom računalu već nije pokrenut alat za
forenzički dohvat podataka, samo njegovo pokretanje mijenja sadržaj radne
memorije. U slučajevima gdje RAM sadržava potencijalno korisne dokaze, jedna je
opcija korištenje WinHex editora. Linux i Unix sustavi jedinstveni su po tome
što je moguće iskrcati cijeli sadržaj radne memorije na neku sigurnu lokaciju korištenjem
ugrađenih funkcija.
Microsoft
Windows nema usporediv sustav. Pokretanjem čak i utility-a na sustavskoj razini može prouzročiti promjenu podataka.
U poglavlju mrežne forenzike opisan je koncept aplikacija forenzičkih klijenata i poslužitelja, oni
predstavljaju najsigurniji način kopiranja sadržaja radne memorije.
4.2.4
Windows
Registar
Prije
Windows 3.11, konfiguracijski dokumenti aplikacija, utilityes i sklopovlja, bili su raštrkani po cijelom sustavu.
Microsoft je odlučio centralizirati sve konfiguracijske datoteke u jednu bazu
podataka koja se naziva Registar.Tijekom dvadeset godina Registar je evoluirao
u kompleksnu bazu podataka koja prati i
bilježi praktički sve promijene na računalu
kao i konfiguracijske postavke. Tipove podataka koje je moguće pronaći u
Registru:
·
Informacije
o lozinkama: Iako je većina korisničkih imena i lozinki kriptirana, moguće je
pročitati informacije korištenjem odgovarajućeg alata. Ovisno o verziji
Windowsa i aplikaciji, korisničko ime i lozinka
pohranjeni su u različitim dijelovima Registra. Neki od tipova lozinki u
Registru su AutoComplete, računalne, Web mail
i Internet stranice.
·
Startup aplikacije: Ovo
područje Registra sadrži listu startup
programa i njihove konfiguracijske informacije.
·
Sklopovlje
za pohranu podataka: Registar sadrži listu trenutno i prethodno spojenih uređaja za pohranu
podataka.
·
Bežične
mreže: zapis koji sadrži sve bežične mreže na koje se sustav spaja, zapisuju se
service set identifikatori SSID
·
Internet
informacije: čuvaju se informacije o utipkanim URL adresama i putanjama
skidanja podataka s interneta.
·
Nepročitane
elektroničke poruke: Registar vodi računa o broju nepročitanih poruka u
korisničkom Outlook računu, i o vremenskim oznakama.
Računalni
forenzički softverski paketi kao što su FTK i Paraben analizator Registra,
jednostavno izvlače informacije iz Registra.
4.2.5
Filtriranje
pretrage
Problem
moderne računalne forenzike ogromne su količine podataka. Kako se tipične
veličine tvrdih diskova počinju mjeriti u terabajtima, filtriranje pretrage
postaje ključno za učinkovito istraživanje i pronalazak digitalnih dokaza.
Problem je najviše izražen prilikom istraga podataka velikih organizacija,
njihovih baza podataka. Za početak potrebno je definirati koji se tip podataka traži, područje kojima
je osumnjičenik imao pristup, te ako je potrebno kasnije proširiti pretragu.
Iako se ovakvim pristupom riskira preskakanje pregleda dijelova koji mogu
sadržavati važne podatke, takav je rizik isplativ ukoliko se uzme u obzir
vremensko trajanje obrade svih podataka, te mogućnost potrebe isključenja kompanijine računalne infrastrukture na
neograničeno vremensko razdoblje. Forenzički softver kao što je EnCase može
filtrirati pretragu na razne načine; korištenjem GREP opcije pretraživanja
kojom se pronalaze i izvlače specificirane vrste podataka, ili korištenjem
internalnih filtera nad označenim podatcima kako bi se iz daljnje istrage
isključili oni koji ne sadrže određene informacije. Softverski paket Paraben
posjeduje otprilike iste mogućnosti filtriranja.
4.2.6
Dobava podataka
Računalni
forenzički softver omogućuje relativno
jednostavno izvlačenje podataka iz medija za pohranu zbog nekoliko razloga:
·
Većina
procesa pretrage i izvlačenja podataka je automatizirana.
·
Prosječni
korisnici ne razumiju kako funkcionira računalo, niti načine pohrane podataka
na računalo.
·
Tehnički
sposobniji korisnici ponekad nemaju pristup svim dijelovima računala ili mreže
na kojem ostavljaju digitalne otiske prstiju.
·
Većina
osumnjičenika ne skriva podatke, već ih samo kriptira, ili sakriva koristeći
steganografiju.
Osnovno
izvlačenje podataka koristeći softver kao što je Paraben, FTK, EnCase relativno
je jednostavno nakon što se na radno računalo
dobavi forenzička kopija, slika
originalnog medija za pohranu. Tada se koriste automatizirani procesi izvlačenja
podataka i generacije izvještaja. Sljedeći koraci prikazuju izvlačenje
obrisanih dokumenata:
·
Dobava forenzičke
kopije i popisivanje cijelog sadržaja medija za pohranu, izdvajanje samo
obrisanih podataka.
·
Identifikacija
obrisanog dokumenta koji sadrži informacije vezane uz istragu, analiza i pretraga
dokumenta za metapodatcima kao što su zaglavlja i vremenske oznake.
·
Ispitati internu
strukturu podataka: ako podatak treba biti grafički, otvara ga se s prikladnim
preglednikom iz softverskog paketa
forenzičkih alata, biti će ga moguće otvoriti ukoliko interna struktura
podataka odgovara zaglavlju.
·
Označiti ili
uključiti dokaz u izvještaj: izvještaji trebaju sadržavati što je više moguće
dokaznih dokumenata i njihovih
metapodataka.
·
Izvlačenje podataka
i analiza, traženje skrivenih podataka, metapodataka ili informacija
specifičnih za istraživani slučaj
·
Izrada radne kopije
koja će se koristiti za daljnje analize
4.2.7
Analiza
dobavljenih podataka
Nakon
izvlačenja podataka, slijedi njihova analiza.Tehnički dio forenzičke istrage
uglavnom je jednostavniji jer su alati
za pronalazak podataka prilično efikasni. Pravi izazov leži u povezivanju i
pronalasku dokaza. Kod analize podataka treba uzeti u obzir sljedeće :
·
Vremenski
slijed događaja: kao se dokaz uklapa u vremenski slijed događaja
·
Poveznica
s osumnjičenikom: kako je dokaz povezan s osumnjičenikom, je li ta poveznica
potvrđena drugim činjenicama ili dokazima.
·
Trag
dokaza: kako je dokaz dospio na mjesto gdje je pronađen, može li se pratiti
digitalni trag dokaza koji se uklapa u vremenski slijed događaja
·
Integritet
dokaza: Jeli dokaz ili dokument zbilja ono za što se predstavlja, postoje li
skriveni podatci u njemu, može li biti krivotvorina, ili podmetnut.
·
Zašto:
Zbog čega je podatak lociran tamo gdje je, zbog čega su dokazi u tom formatu.
4.3
Forenzika
dokumenata
Što dokument govori o osobi koja ga je
stvorila gotovo je jednako važno namjeni tog dokumenta. Kada istražitelj
pronađe dokument s inkriminirajućim dokazima, mora dokazati tko ga je napisao i kada. Nekako mora povezati
dokaz s osumnjičenikom, tada u igru ulazi forenzika dokumenata i metapodatci.
Metapodatci su podatci o podatcima. Razlikuju se za različite tipove podataka i
domena, na primjer metapodatci o dokumentima razlikuju se od metapodataka o
internetskim stranicama, no oboje opisuju u nekom obliku karakteristike
podataka koje predstavljaju. Dio metapodatka za sliku na primjer sadržava
vremensku oznaku koja prikazuje kada je fotografija nastala. Računalna
forenzika, asocijacijom i forenzika dokumenata imaju isti cilj kao i klasična
forenzika: sastaviti istinitu verziju događaja potkrijepljenu dokazima. Ključ
provođenja računalne forenzičke istrage je ne samo postaviti prava pitanja, već
i znati interpretirati način na koji računalo odgovori na pitanja. Ovo se poglavlje
bavi pronalaskom tragova skrivenih u dokumentima koji mogu odgovoriti na
pitanje poklapaju li se ljudska i računalna verzija događaja [12].
4.3.1
Pronalazak
dokaznog materijala u dokumentima: Metapodatci
Dokumenti
predstavljaju najvažnije mjesto
pronalaska metapodataka. Sljedeća lista opisuje osnovne tipove metapodataka za
tipičan tekstualni dokument:
·
Autor:
Nebitno dolazi li informacija od operacijskog sustava ili instalacije softvera za obradu riječi, u
dokument se ugrađuje ime;
·
Organizacija:
Dobavlja se iz istog izvora kao i informacija o autoru;
·
Revizije:
Kao dio stvaranja revizijskog zapisa pohranjuje se ime prethodnih autora i
putanja do mjesta na kojem je dokument pohranjen;
·
Prethodni
autori;
·
Predložak:
Ova informacija prikazuje koji je predložak ugrađen u dokument;
·
Ime
računala: ova informacija povezuje dokument s računalom na kojem je nastao;
·
Tvrdi
disk:ime diska i putanja do mjesta na kojem je pohranjen podatak;
·
Mrežni
poslužitelj: Nastavak informacija o tvrdom disku, ukoliko je dokument pohranjen
na mrežnom poslužitelju, metapodatak sadrži ime mrežne putanje
·
Vrijeme:
ovaj informacija ukazuje na to koliko je dokument vremena bio otvoren prilikom
uređivanja;
·
Izbrisani
tekst: neki metapodatci sadrže i izbrisani tekst;
·
Objekti
Visual Basic-a;
·
Vremenske
oznake: datum i vrijeme stvaranja, pristupa, i modifikacije (eng created, accessed, and modified, skrać
CAM.);
·
Ispis:
Metapodatci sadrže i informacije je li i
kada je dokument ispisan.
Iako se
većina metapodataka izvlači iz Microsoft-ovih alata i aplikacija, metapodatke
se može pronaći u gotovo svim aplikacijskim softverima; u Adobe PDF
dokumentima, multimedijalnim zapisima, internetskim stranicama, bazama podataka,
čak i geografskim softverskim aplikacijama.Tip i količina pronađenih
metapodataka ovisi o aplikaciji i koliko je korisnik sklon unošenju osobnih
informacija na računalu. Metapodatci locirani unutar dokumenta mogu se svrstati
u dvije kategorije: metapodatci kojima korisnik može pristupiti, i oni kojima
ne može. Ukoliko metapodatci nisu vidljivi, potrebno ih je izvući.
Lista
opisuje informacije koje se može pronaći pregledavajući metapodatke dostupne
korisnicima:
·
Osnovne
informacije o korisniku
·
Statistika
dokumenta: broj stranica, paragrafa, vremenske oznake
Prilikom
izvlačenja metapodataka potrebno je koristit specijalne softverske alate kao
što su Metadata Analyzer ili iScrub. Ovi alati analiziraju dokumente na
binarnoj razini pri analizi dnevnika revizije, Objekata Visual Basic-a ili
izbrisanog teksta koji bi se još mogao nalaziti u podatcima.
4.3.2
Pregled
CAM informacija
Korištenjem
CAM (eng.Create, Access, Modify)
vremenskih oznaka često je moguće odrediti vremenski tijek događaja. Lokacija
CAM informacija ovisi o OS. Korištenjem CAM metapodataka moguće je rekreirati
osumnjičenikov tijek kretanja, povijest dokumenta ili pratiti putanju dokumenta kroz mrežu. Vremenske oznake u CAM
metapodatcima znače:
·
Stvaranje
(eng. create): prikazuje vrijeme i datum
kada je dokument stvoren na tom mediju za pohranu. Ova se vremenska oznaka
mijenja svaki puta kada se dokument kopira na novi medij, čak i unutar istog
uređaja za pohranu.
·
Pristup(eng.
acess): specificira zadnji puta kada
je dokument otvoren, ili pregledan ali ne i mijenjan
·
Modificiranje(eng.
modify): sadrži datum i vrijeme
mijenjanja dokumenta. Na dokumentima
koji su kopirani na nove medije, vremenska oznaka modificiraj može biti starija
od vremenske oznake stvaranja.
Datumi i
vremena asocirana s CAM informacijama dobivaju se od sustavskog sata, stoga u
slučaju da je on krivo postavljen, vremenske su oznake također pogrešne.
Pitanje koje ostaje prilikom pregleda vremenskih oznaka jest jeli korišteno
lokalno računanje vremena ili Zulu.
Svijet je podijeljen na 24 vremenske zone, koje se označavaju po slovima
engleske abecede; vremenska zona Z (Zulu), predstavlja vrijeme u Greenwich-u,
Engleska. Zulu se računanje vremena u avijaciji koristi kao standardno, tako se
bez obzira na vremensku zonu zna koliko je sati. Problem koji se javlja
prilikom pregleda vremenskih oznaka je taj da je dokument možda stvoren u Hong
Kong-u, poslan u London, te kopiran u New Yorku, sve unutar nekoliko sekundi.
Ovaj raspon lokalnih vremena može
zbuniti istražitelje, i postaje veoma teško odrediti vremenski tijek događaja
dokumenta. Za većinu je ljudi korištenje lokalnog ili Zulu računanja vremena
semantičko pitanje, ali za istražitelje znači točnost preciznost, i pouzdanost vremenskih oznaka.
Kako su CAM
informacije postale ključne u rješavanju računalnih forenzičkih slučajeva,
stvoreni su softverski paketi koji mogu poremetiti CAM informacije, te popuniti
polja vremenskih oznaka sa slučajnim nizom vremena i datuma., ili ih
jednostavno obrišu, te se forenzičari moraju pouzdati u vremenske oznake
sekundarnih izvora kao što su poslužitelji elektroničke pošte.
4.3.3
Otkrivanje
dokumenata
Na žalost
forenzičkih računalnih istražitelja , dokumenti mogu biti skriveni na mnogo
mjesta, prikriveni, prerušeni kriptirani. Prvo mjesto gdje treba tražiti
dokumente jest naravno u aplikacijama u kojima su stvoreni. Većina softverskih
aplikacija pohranjuje listu dokumenata koji su nedavno bili otvarani,
mijenjani, stvoreni, te gdje su sačuvani. Ova metoda pretrage prikladna je iz
razloga jer upućuje na vanjske uređaje za pohranu podataka kao što su
PRIJENOSNE memorije. Sljedeći korak u
otkrivanju dokumenata jest korištenje forenzičkog softvera kao što je FTK ili
EnCase, te otvaranje svih dokumenata određenog traženog tipa. Ovaj pristup može
doprinijeti preskakanju dokumenata ukoliko ih je korisnik zamaskirao u neki
drugi tip dokumenata promjenom zaglavlja ili ekstenzije.
Aplikacijski programi općenito prepoznaju
dokumente po ekstenziji ili po zaglavlju, dok
se OS općenito oslanja na ekstenziju kako bi utvrdio tip dokumenta.
Zaglavlje se
sastoji od niza znakova, na samom
početku dokumenta koji označavaju kojem tipu dokumenta pripada. Postoje tisuće
tipova dokumenata, te pronalazak zaglavlja dokumenta stvorenog nekom manje
poznatom aplikacijom može biti izazovno. Na sreću većina dokumenata pripada
tipovima podataka koje stvaraju popularni softverski i dobro poznati paketi. Na stranici [18], moguće je provjeriti koje zaglavlje ide uz
istraživani dokument.
Promjenom
ekstenzije dokumenta, niz znakova na početku zaglavlja se ne mijenja, te
aplikacija koja je originalno stvorila dokument, bez problema ga i otvara.
Većina forenzičkog softverskog alata
provodi analizu potpisa kako bi utvrdili odgovaraju li ekstenzije tipu dokumenta deklariranom u zaglavlju, te
sastavljaju popis sumnjivih datoteka i dokumenata. Ukoliko se zapisi poklapaju,
dokument je vjerojatno ono za što se predstavlja, ukoliko se ne poklapaju,
dokument je zamaskiran kao nešto drugo, kako bi se prikrili podatci, ili zavaralo istražitelje.
Modificiranje zaglavlja
Dokument ne
mora biti tipa za koji se izdaje čak ni
ako mu se zaglavlje i ekstenzija poklapaju. Ukoliko korisnik promijeni
ekstenziju dokumenta, modificira zaglavlje, te promijeni ime dokumenta u neki
sustavski, analizom potpisa može se samo utvrditi poklapaju li se ekstenzija i
zaglavlje, te se taj dokument ne označuje kao sumnjiv. Ukoliko istražitelj
sumnja u modificiranje zaglavlja, provjera se provodi sljedećim koracima:
·
Ukoliko
se prilikom pokušaja otvaranja dokumenta pojavi poruka pogreške u dokument se
iskopira zaglavlje njegovog tipa za koje je istražitelj siguran kako je
ispravno.
·
Korištenjem
hash vrijednosti poznatih tipova dokumenata, moguće je eliminirati
originalne dokumente iz daljnje obrade. Gotovo na svakom operacijskom sustavu
postoje biblioteke s hash
vrijednostima, sadrže hash
vrijednosti najpopularnijih aplikacijskih softvera i tipova njihovih
dokumenata. Ukoliko je korisnik modificirao zaglavlje i ekstenziju, hash vrijednost tog dokumenta neće se
poklapati s onom standardnih hash
vrijednosti istog tipa sačuvane u
biblioteci.
·
Pregled
dokumenata koji su nedavno modificirani,
ili se modificiraju prilično često; korisnik mora modificirati dokument kako bi
ga otvorio, te ponovno modificirati zaglavlje prilikom skrivanja.
4.3.4
Pronalazak
poveznica i vanjskih medija za pohranu podataka
Kada
se dokument kopira ili sačuva na lokalnom računalu, generira se dokument poveznica
(eng. Link file), kako bi OS znao gdje je dokument lociran. Ovi
link dokumenti često su jedini dokaz kako je neka vanjska jedinica spajana na
računalo. Forenzičkim je softverom moguće pronaći čak i obrisane dokumente poveznice. Ovisno o
korištenom forenzičkom softveru, koraci rekonstrukcije dokumenata
poveznica variraju, no cilj im je isti;
utvrđivanje traga ili poveznice s jednog uređaja na drugi. Utvrđivanje traga
važan je proces jer se njime povezuje na primjer uređaj na kojem je pronađen
dokument s računalom na kojem je nastao.
Uz
dokumente poveznice, tragove o mogućim vanjskim medijima moguće je pronaći i u
Windows Registru.
Ako
dokument poveznica upućuje na mrežnu
putanju kao što je na primjer \\poslužitelj\test.doc, istražitelji imaju malo
vremena za njihovo praćenje jer se informacije na usmjerivačima i
poslužiteljima relativno brzo prepisuju novim podatcima. Dokumenti
poveznice pružaju veliku količinu
informacija, moguće jednake važnosti kao
i sam dokument do kojeg vode zbog vremenskih i lokacijskih oznaka koje sadrže.
Većina
kompanija i organizacija posjeduje određeni oblik sigurnosnih kopija svojih
baza podataka te ostalih važnih informacija. Forenzičkim istražiteljima ove
kopije pružaju uvid u sranje računalnog sustav kroz vrijeme, i čuvaju se dugo
nakon što su originalna računala zamijenjena. Malo ljudi zna za njihovo
postojanje ili imaju pristup sigurnosnim kopijama. Čak ako uspiju obrisati sve svoje digitalne
tragove na računalu, ne mogu i na sigurnosnim kopijama.
4.4
Forenzika
mobilnih uređaja
Većina ljudi
ne shvaća mogućnosti pametnih telefona (eng. Smart phones), iPoda, MP3 playera, BlackBerry-a, PDA dlanovnika
(eng. Personal digital assistant).
Mobilni telefon ili PDA u današnje vrijeme otprilike posjeduju računalnu moć
računala proizvedenog u proteklih pet godina. Mobilni telefoni skoro standardno rade s gigahercnim
procesorima, radnim memorijama i do 512 MB, tvrdog diska veličine 80 i više GB. Većina je mobilnih
telefona u potpunosti bežično funkcionalna, sadrže Bluetooth, infracrvenu i 802.11
tehnologiju. Definicija mobilnog uređaja malo je neprecizna zbog toga što mnogi
uređaji kao što su iPod-ovi i video kamere postaju sve manji i mobilniji.
Većina se mobilne forenzike danas provodi na mobilnim telefonima i PDA
dlanovnicima. Tehnologije se u mobilnom svijetu mijenjaju veoma brzo, te
snalažljivi korisnici često otkriju metode prikrivanja podataka i uporabe novih
uređaja za nenamijenjene svrhe prije nego forenzički istražitelji u potpunosti
uspiju analizirati uređaje, te pronaći njihove slabosti i mogućnosti. U većini
je računalnih područja ovaj problem prisutan, no posebno u području mobilnih
tehnologija, jer je brzina promijene tako velika.
Iako
korisnici često povećavaju količinu radne memorije i tvrdih diskova na svom računalu,
ona u biti koriste istu tehnologiju godinu za godinom. Prilikom istrage
mobilnih uređaja treba imati na umu kako
se razlikuju od računala u tri bitne činjenice:
·
Česte
promjene operacijskih sustava, sklopovskih standarda, tehnologija pohrane
podataka, sučelja.
·
Postoji
mnogo različitih platformi mobilnih uređaja, dok je kod računala više manje sve
standardizirano.
·
Koriste
bežičnu tehnologiju za komuniciranje.
Tri su
osnovna načina na koji mobilni uređaji komuniciraju, uz radio mobilnih telefona
koji koriste sve kompanije koje proizvode mobilne telefone.
1.
802.11: ovu normu koriste sve bežične mreže koje
danas postoje. Domet mobilnog uređaja koji koristi 802.11 znatno varira i ovisi
o snazi uređaja, ali uglavnom minimalno 100 metara promjera .
2.
Bluetooth: relativno nov
norma korišten na malim udaljenostima, otprilike 20 metara
3.
Infracrvena komunikacija: koristeći stariju metodu
komuniciranja mobilni uređaji mogu razmjenjivati informacije koristeći
infracrveni dio spektra. Ova je metoda usmjerene prirode, tj za komunikaciju
među uređajima njihovi infracrveni portovi moraju biti okrenuti jedan prema
drugome.
Računalna
forenzika u svom je pristupu poprilično
standardizirana, dok mobilna forenzika
još uvijek iskušava različite
pristupe istraživanja. Ovo je područje računalne forenzike relativno novo i ne
vrijede ista pravila kao i kod standardne forenzike; na primjer klasična
pravila kao što je zabrana pisanja na istraživani medij, ponekada se ne može
provoditi prilikom istraživanja u mobilnoj forenzici [12].
4.4.1
Forenzički
pogled na mobilne uređaje
Ovisno o
tipu mobilnog uređaja moguće je pronaći sljedeće tipove dokaza prilikom
analize:
·
Pretplatnički
identifikator: Na mobilnim telefonima ovu informaciju koriste mreže mobilnih
telefona za autentifikaciju korisnika te verifikaciju tipa usluge vezanu uz tog
korisnika. Drugim riječima, moguće je povezati identitet mobilnog uređaja s
zapisima koje čuva pružatelj mobilne usluge. Subscriber Identity Modules (kratica SIM), te informacije imaju
ugrađene u sebi, ukoliko uređaj ne podržava SIM kartice. Informacije su
kodirane na sam uređaj.
·
Dnevnici:
Mobilni uređaju često sadrže dnevnike primljenih, propuštenih, odgovorenih
poziva, i biranih brojeva kojima je moguće utvrditi određene vremenske
sljedove. Nadalje, dnevnici sadržavaju i GPS informacije, spajanja na mrežne
ćelije, vrijeme prekida veza s mrežnim ćelijama. Ovi dnevnici mogu i ne moraju
postojati ovisno o uređaju, no ako postoje
veoma je jednostavno locirati korisnika.
·
Imenik/Lista
kontakata: lista potencijalnih svjedoka, žrtava, i suučesnika koja može
sadržavati sliku, adresu elektroničke pošte, fizičke adrese, alternativne
brojeve telefona, te mnoge druge informacije.
·
Tekstualne
poruke: One sadrže dijelove dokaza kao i vremenske oznake, koje su veoma važne
u istrazi. Kao i kod medija za pohranu podataka, i ovdje je moguće
rekonstruirati i pronaći oštećene ili obrisane poruke.
·
Kalendar:
može sadržavati informacije o kretanju osumnjičenika, njegovim obvezama i
ljudima s kojima je kontaktirao.
·
Elektronička
pošta
·
Instan
poruke: verzija poruka koje se razmjenjuju u stvarnom vremenu, mogu sadržavati
čitave razgovore i vremenske oznake.
·
Slike
·
Audio
zapisi
·
Multimedijalne
poruke
·
Aplikacijski
dokumenti:Napredniji mobilni uređaji imaju mogućnost pregleda i kreiranja
dokumenata, prezentacija, proračunskih tablica i mnogih drugih formata
dokumenata.
Većina
mobilnih uređaja ima mogućnost korištenja vanjskih medija za pohranu kao što su
SD kartice, one često služe i za prijenos podataka s računala na mobilni uređaj
i obrnuto, stoga su važan izvor potencijalnih dokaza.
Cilj
forenzičkog softvera uvijek je dvojak:
·
Zaštita
postojećih podatka na originalnom uređaju, ovaj korak osigurava integritet
prikupljenih podataka
·
Postaviti
mehanizma koji će računajući hash
vrijednosti potvrditi integritet
Funkcije
izračuna hash vrijednosti te write protect softver i sklopovlje
omogućuju ove ciljeve koje koriste svi forenzički alati. No kod mobilnih je
uređaja ponekad potrebno pisati po njihovoj memoriji kako bi dohvatili informacije. Cilj u ovakvim
slučajevima jest zapisati što je moguće manje informacija. Najbolji primjer
akvizicije podataka korištenjem neforenzičkih alata jest korištenje sinkronizacijskog
softvera kako bi se pristupilo podatcima na mobilnom uređaju. U osnovi podatci
se kopiraju s originalnog uređaja, no time se mijenjaju datumske i vremenske
oznake podataka. U tom je slučaju teško dokazati kako integritet podataka nije kompromitiran.
Ukoliko se
istraga provodi na nekom novom mobilnom uređaju za kojeg još ne postoje
modificirani forenzički alati, što je čest slučaj uzimajući u obzir brzinu
mijenjanja tržišta mobilnih uređaja, preporučuje se izrada dodatnih kopija
podataka, te precizno bilježenje korištenih procedura i metoda.
4.4.2
Mobilni
telefoni i SIM kartice
Područje
forenzičke akvizicije i izvlačenja podataka s mobilnih telefona jedno je od
najzahtjevnijih zbog prirode brzog mijenjanja industrije, te širokog izbora
nestandardnih uređaja na tržištu. Unatoč svim njihovim razlikama, mobilni
telefoni sastoje se od tri temeljne komponente:
·
Read Only Memory (ROM): Na ovom je području
mobilnog telefona smješten OS , a često i softver za rješavanje problema
korišten za dijagnostiku uređaja.
·
Random Access Memory (kratica RAM): Ovo se područje
memorije koristi za privremenu pohranu podataka ; ukoliko se mobilni telefon
isključi, podatci se gube.
·
Jedinica za pohranu podataka: Iako većina mobilnih
telefona imaju internu memoriju koja je najčešće zasnovana na tehnologiji flash memorije, većina naprednijih
modela telefona dolaze s ugrađenim utorima za memorijske kartice koje proširuju
kapacitet pohrane podataka uređaja.
Vanjski
mediji za pohranu podataka dolaze u obliku
MiniSD kartica, SD kartica, ili MMC mobilnih kartica. Za čitanje ovih
kartica na računalu potrebi su posebni čitači kartica.
Mobilna mreža
Jedna od
prvih stvari koje istražitelj treba znati je na koji je tip mobilne mreže
spojen telefon:
·
Code Division Multiple Access (CDMA): Ne posjeduje
Subscriber Identity Module (SIM) modul, što
znači da su svi podatci sačuvani na mobilnom telefonu.Koristi se pretežno u
SAD-u.
·
Global System for Mobile Communication (GSM): Ovi
sustavi koriste SIM module kao odvojene komponente dizajnirane da budu prenosivi
s jednog telefona na drugi. Razvili su ga Nokia i Ericsson, a koristi se
pretežno u Europi.
·
Integrated Digital Enhanced Network (iDEN):
Koristi sustav naprednih SIM kartica
(eng. advanced SIM cards , kratica USIMs), razvijen u
Motoroli
O tipu mreže
ovisi koji se forenzički alat koristi
prilikom obrade mobilnog telefona.
Istraživani uređaj
Nakon
utvrđivanja sustava u kojem mobilni
telefon radi, sljedeći je korak utvrđivanje specifičnog tipa mobilnog uređaja
kako bi se utvrdile njegove karakteristike i mogućnosti. Identifikacija tipa
mobilnog telefona provodi se pretragom proizvođača, serijskog broja uređaja
koji se obično nalaze ispod baterije, sinkronizacijskog softvera, kodovima
proizvođača. Kroz kod proizvođača moguće je doći do informacije kao što su
proizvođač telefona, model, kod zemlje u kojoj je proizveden, a nalazi se
uglavnom oko istog područja gdje i serijski broj. U operacijskom sustavu
mobilnog telefona moguće je pronaći sljedeće informacije: Electronic Serial Number (kratica ESN), Integrated Circuit Card Identification (kratica ICCID), International
Mobile Equipment Identifier (kratica
IMEI).
Nakon
utvrđivanja tipa mobilnog telefona traži se lista karakteristika koje navodi
proizvođač, te se na temelju te liste
izdvoje najvjerojatnija mjesta gdje
je moguće pronaći dokazne
materijale. Iako specifikacije proizvođača mogu
biti znatno različite od stvarnog stanja u mobilnom telefonu zbog
korisnikove prilagodbe, pregledom specifikacija dobije se uvid u:
•
Metode
bežičnog spajanja: koristi li telefon bluetooth,
WiFi ili infracrvenu tehnologiju uz mobilnu tehnologiju komuniciranja
•
Pristup
internetu
•
Kamera
•
Upravitelj osobnim informacijama (eng. Personal information manager ,
kraticaPIM): variraju u komponentama, no većina ih sadrži kalendar, imenik, i
softver za produkciju i pregled raznih tipova dokumenata
•
Poruke: može li se telefonom slati poruke, multimedijalne poruke, ili
elektronička pošta
•
Aplikacije: s kojim je tipom aplikacija telefon
isporučen
•
Sučelje za spajanje, ili kabel: kakav tip kabela je
potrebno za spajanje telefona s računalom
SIM kartica
Subscriber
Identity Module (SIM), upotrebljava se s GSM i iDEN mrežama. Omogućava
korisniku prebacivanje podataka kao što su
imenik i poruke, te korisničke autentifikacije među mobilnim telefonima.
Iako korisnik može mijenjati mobilne telefone, i dalje ga se može pronaći korištenjem SIM kartice.
Kako bi se izbjeglo kontaminiranje dokaza ne preporučuje se pristupanje
telefonu korištenjem druge SIM kartice. Kloniranje SIM kartica korištenjem
forenzičkih alata najsigurniji je način pristupanja mobilnom telefonu. SIM
kartica zaštićena je PIN brojem (eng. Personal
identification number), čija je zadaća
ne samo zaštita podataka na kartici , već i na samom uređaju. PIN broj dugačak je od četiri
do osam znamenki, te provodi sigurnosnu opciju blokiranja uređaja ukoliko se
unese pogrešan PIN određen broj puta, najčešće tri. Mobilni se telefon nakon
blokiranja može otključati PUK brojem (eng. PIN
Unblocking Key), a ako se kojim slučajem nekoliko puta unese i krivi
PUK broj, uređaj se više ne može odblokirati.
Do nedavno
su se dlanovnici (PDAs) koristili kao
samostalni uređaji, no danas su mogućnosti PDA, mobilnog telefona i pagera,
nalaze u pametnim telefonima (eng. Smart
phones). Danas se rijetko nailazi na ove uređaje, i to većinom Palm OS,
koja je najpopularnija PDA platforma koja se trenutno još uvijek koristi.
Analiza, obrada i prikupljanje podataka na PDA obavlja se na isti način kao i
za mobilne telefone. Realno gledajući, jedina razlika između PDA i mobilnog
telefona jest ta što se PDA-om ne može obavljati pozive.
4.4.3
Digitalne
kamere
Digitalni
fotoaparati i kamere u današnje se vrijeme zapravo svode na isti uređaj.
Prilikom njihova pregleda najbitnije je naravno područje za pohranu fotografija
i snimaka. Iako je broj proizvođača digitalnih fotoaparata i kamera golem,
način komunikacije opreme većinom je standardiziran. Većina digitalnih kamera
koristi standardni ili mini USB priključak za spajanje s računalom, te
standardne memorijske kartice kao što su MiniSD ili CompactFlash, za proširenje
kapaciteta pohrane. Većina trenutno
dostupnih sustava prilikom istrage tretira se kao samo još jednu jedincu za
pohranu podataka olakšavajući time posao istražiteljima, jer je moguće korištenje
standardnih metoda i alata za digitalnu
forenziku. Kako se analize i pretrage povode preko USB porta, potrebno je
omogućit opciju zabrane pisanja po
mediju, kako se prilikom analize podatci ne bi slučajno modificirali. Isto
pravilo vrijedi i za čitanje ili prijenos podataka s memorijskih kartica.
Kao i kod
digitalnih kamera, većina digitalnih audio uređaja kao što su MP3 playeri, ili
iPod-ovi, tretira se kao medij za pohranu podataka te se skladno tome i
obrađuje forenzičkim alatima.
4.4.4
Odabir
alata za forenzičku obradu
Polje
mobilne forenzike još je relativno novo stoga ne postoji jedan alat ili skupina
alta koji pokriva sve moguće situacije. Računalna forenzika dijeli se na dva
načina akvizicije podataka: fizičku i logičku akviziciju. Tehnike mobilne forenzike
prate isti format, no zbog velikog broja postojećih platformi, logička
forenzička akvizicija tip je koji se najčešće provodi. Očit razlog korištenja
ovog tipa akvizicije je taj da forenzički softver koristi OS mobilnog uređaja
za izvlačenje podataka. Fizička akvizicija podataka ima prednost nad logičkom ,
jer je njome moguće izvući podatke koje OS ne vidi ili nema pristup.
Polje
mobilne forenzike primarno se bavi
akvizicijom podataka s mobilnih telefona. Alati korišteni za akviziciju, mogu
se koristiti i na PDA uređajima. Alati za mobilnu forenziku pripadaju dvjema
grupama: GSM i CDMA tipovima za akviziciju. Drugim riječima, neki forenzički
alati rade samo analizu uređaja, dok neki i uređaja i SIM kartice. Neki su
alati toliko specijalizirani da rade samo na određenom tipu mobilnog uređaja.
U nastavku
su navedeni alati koji rade na SIM
karticama i mobilnom uređaju:
•
Paraben : Parabenov skup alata za mobilne uređaje
pokriva područja od Palm uređaja sve do Garmin GPS _ Logicube
•
CellDEK kit
•
Oxygen
software
U sljedećoj su listi navedena
dva SIM forenzičkih alata
•
Crownhill
•
InsideOut
Forensics
4.4.5
Sklopovlje
korišteno u mobilnoj forenzici
Tip
forenzičkog sklopovlja korištenog za mobilnu forenziku varira od standardne
opreme za računalnu forenziku. Razlog je tome
što se ovdje radi s većim brojem raznog tipa uređaja s mogućnostima
bežičnog komuniciranja.
Osnovni
sklopovlje sastoji se od:
•
Faradayeve
torbe (eng. Faraday bag): sprječava
komuniciranje mobilnih uređaja s vanjskim bežičnim uređajima, tako da presreće
radio valove , te se ponaša kao velika vanjska antena, koja preusmjerava radio
signal od mobilnog uređaja. Dakle sprječava primanje i slanje podataka, izolira
uređaj. U okruženju mobilne forenzike, izolacija uređaja prvi je korak prilikom
dolaska na scenu istraživanja.
•
Čitač
SIM kartica
•
Razne
kabele za spajanje uređaja s računalom
te punjenje baterija
4.4.6
Izoliranje
mobilnih uređaja
Prilikom
istrage mobilnog uređaja on mora biti izoliran ne samo od drugih mobilnih telefona, već i od bilo kakve komunikacije
korištenjem bluetootha, WiFi-a ili
infracrvene komunikacije. Pod svaku se cijenu mora izbjeći kontaminacija
podataka na mobilnom uređaju nakon što je zaplijenjen. Razlozi su sljedeći:
•
Praktični:
istražitelj ne želi da mu podatke i
moguće dokaze prebrišu novi
•
Sigurnosni:
postoje uređaji i mehanizmi kojima je moguće zaključati ili uništiti uređaj iz
daljine
•
Legalni:
Sud može odbaciti sakupljene dokaze ukoliko postoji sumnja u njihov integritet
Mobilni se
telefon može izolirati na nekoliko načina:
•
Izolacijom
bežične komunikacije korištenjem Faradey-eve torbe ili uređaja za ometanje.
Ovaj način izolacije funkcionira do trenutka kada se iscrpi baterija uređaja, a
kako većina uređaja povećava snagu odašiljanja prilikom pokušaja spajanja,
baterija se samim time brže troši.
•
Isključivanjem
uređaja
•
Postavljanje
uređaja u zrakoplovni način rada u kojem su isključeni svi bežični načini
komunikacije, mana ovog pristupa jest potreba interakcije s uređajem te se time
riskira mogućnost promijene dijela podataka
4.4.7
Pronalazak
mobilnih podataka
Nakon
izolacije telefona potrebno je održavati
baterije napunjenima ukoliko se ne želi
izgubiti podatke smještene u radnoj memoriji. Sljedeći korak jest pronalazak
traženih informacija. Ovisno o tome radi li se s GSM ili CDMA uređajem,
procedure izvlačenja podataka neznatno variraju. Ako se radi s SIM karticama,
ona se prvo klonira, ili izradi image
podataka korištenjem čitača kartica, ali pritom pazeći da se onemogući pisanje
na originalni medij. Nakon izvlačenja podataka za analizu, forenzički alati
izvršavaju pronađi i dohvati
automatizirane funkcije.
Kada
se podatci izvlače iz samog uređaja, korištene procedure ne razlikuju se od
onih korištenih kod SIM akvizicije.
4.5
Mrežna
forenzika
Računalna
forenzika svoje korijene vuče iz rekonstrukcije oštećenih podataka, tako je i
mrežna forenzika potekla iz mrežne sigurnosti,
otkrivanje napada i neovlaštenog pristupa mrežama. Istrage o
cybernapadima ili neovlaštenim upadima tretiraju se kao istrage u polju mrežne
forenzike. Glavni su problemi kako zaustaviti upad, i pritom očuvati dokaze za
kasniju analizu ili uporabu na sudu. Mrežna se forenzika bavi s podatcima koji
se mijenjaju iz milisekunde u milisekundu, s terabajtima podataka koji se mogu
pohraniti na mreži bez prekoračenja kapaciteta. Mreže su spojnice prometa
velikog volumena, što forenzičke istrage čini izazovnim [12].
4.5.1
Primjene
mrežne forenzike
Iako većina
sustava kao što su sustavi za otkrivanje upada na mrežu (eng. Intrusion Detection Systems, skrać IDS),
mogu pronaći i pratiti mrežne informacije, forenzičkim se alatima dodatno može
provesti analizu vremenskog tijeka (eng. timeline),
rekonstrukcije elektroničkih poruka, analize metapodataka, analiza paketa
odnosno okvira (eng. frame), ili ckechsum kako bi se matematički pokazalo
da se podatci nisu promijenili od vremena kada su pronađeni i dohvaćeni. Drugi,
manje poznat aspekt mrežne forenzike je
podskup forenzičkog softvera koji djeluje na mrežu tretirajući ju kao što bi
forenzički alati obrađivali statičko računalo. Drugim riječima moguće je
provesti računalnu forenzičku analizu preko mreže, i time nije nužno potrebno
imati fizički pristup istraživanom računalu. Iako je dobavljanje slike računala
tj forenzičke kopije preko mreže tehnološki izvedivo, treba uzeti u obzir
legalna ograničenja ukoliko se istraživano računalo nalazi u nekoj drugoj
državi.
Mrežni je
sklopovlje standardizirano u velikoj mjeri, te je time olakšana istraga, zbog
mogućnosti primjene istih alata prilikom analiza svih sustava i mreža.
Osnovna
struktura rada mrežnog forenzičkog sustava zasnovana je na klijent poslužitelj
mrežnom sustavu. Na poslužiteljima se nalaze svi podatci, a klijenti spojeni na
taj poslužitelj skidaju ili primaju
podatke s njega. U mrežnoj forenzici, ovaj je model malo modificiran; umjesto
da klijent komunicira s poslužiteljem, agent
komunicira sa poslužiteljem. Agenti ili senzori prenose informacije poslužitelju. U slučaju mrežnih forenzičkih
agenata, prilikom prosljeđivanja podataka aktivirane su zaštitne mjere koje
onemogućuju mijenjanje podataka prilikom tranzita, te kako bi se provjerilo
jesu li podatci sumnjivi ili sigurni s tehničkog stajališta. Agenti se koriste
u korisničkim računalima, dok se senzori smještaju na mrežnoj opremi kao što su
usmjerivači i preklopnici.
Osnovna se
struktura mrežnih forenzičkih alata može razvrstati u tri grupacije:
·
Poslužitelj
za upravljanje i kontrolu (eng. Command
and control server): upravlja operacijama mrežnih forenzičkih alata, te u
većini slučajeva poslužitelj dolazi s GUI programskim paketom preko kojeg je
moguća jednostavna komunikacija sa svim dijelovima mrežnog forenzičkog sustava.
Iz tog se poslužitelja postavljaju
programski agenti, akvizicijski parametri, dobavlja se slika, te sve
ostale akcije prikupljanja i analize
·
Poslužitelj
za pohranu (eng storage server):
repozitorij svih podataka preuzetih s
mrežnih izvora. Podatci prikupljeni od agenata i senzora se ispituje,
forenzički autentificira i tada pohranjuje. Velikim količinama podataka na tim
poslužiteljima upravljaju baze podataka kao što su Microsoft SQL.
·
Agenti:
većina agenata nije veća od 200KB, te rade u prikrivenom načinu rada,
prikupljaju i podatke koje OS ne vidi ili do kojih nema pristupa, razmješteni
po istraživanim sustavima ili mrežama.
Softver forenzičkih agenata može se maskirati kao jedan od standardno
korištenih programa, a svoje informacije šalju kriptirane, čak i nasumičnim
redoslijedom kako bi se zamaskirao podatkovni teret.Ukoliko je potrebno
prenijeti pre veliku količinu podataka, kako bi njihov prijenos ostao
nezamijećen, forenzički se softver podešava da prijenos obavlja kada je promet
na mreži minimalan.
Većina je
mrežnih uređaja standardizirana u
interakciji s drugim mrežnim uređajima, no unutar svakog tipa mrežnog uređaja
kao što su usmjerivači, preklopnici ili privatna čvorišta (eng. Hub), postoje mnoge varijacije
konfiguracija i mogućnosti postavki.
4.5.2
Kategorizacija
podataka
Tipovi
podataka koji se mogu dohvatiti koristeći mrežne forenzičke alate variraju od
forenzičkih kopija tvrdog diska do dnevnika usmjerivača.
Podatci se
sakupljaju sa sljedećih uređaja:
·
Host računala: Provodi se
standardna forenzička akvizicija; image uređaja za pohranu podataka, sadržaj
radne memorije, statički dokazi fizički locirani unutar dosega agenata, svi se
ovi podatci prebacuju na forenzički poslužitelj. Dodatno se sakupljaju i
podatci u stvarnom vremenu koji se nalaze u mrežnoj kartici računala. Host
računala su radne stanice ali i poslužitelji (mrežni, poslužitelj elektroničke
pošte, poslužitelji baza podataka)
·
Usmjerivači
(eng. Router): dizajniran za prijenos
podataka među mrežama. Tip informacija koje se nalaze na usmjerivaču vezane su
uz dnevnike prometa, pohranu mrežnih razgovora ili dokumenata. Dnevnici prometa
sadrže pogreške koje su se dogodile tijekom usmjeravanja, statusne informacije
komponenti usmjerivača. Usmjerivači čuvaju određen broj IP i MAC adresa koje
vode do ostalih mreža i host računala.
·
Zaštitna
stijena (eng. firewall): sadrži
detaljne dnevnike aktivnosti na sustavu kao što su pokušaji napada,
neovlaštenog pristupa, nedostavljanih paketa, sigurnosna pravila, aplikacije
koje imaju ili nemaju dozvolu komuniciranja s mrežom, ili primanja podataka s
mreže, izvore sumnjivih akcija, protokole i servise kod pokušaja neovlaštenog upada, te
napadačevu IP adresu.
·
Preklopnik
(eng. switch): korisne
informacije nalaze se u sadržajnoj
adresabilnoj memoriji (eng. Contetn addressable memory, kratica CAM).
U njoj su smještene informacije o pridruživanju MAC adresa specifičnim
portovima, kao i podatci o virtualnim lokanim mrežama (eng. Virtual local area netwotk, kratica
VLAN). Preklopnici ne vode dnevnike aktivnosti, zbog toga što ne posjeduju
dovoljno memorijskih ili procesuralnih kapaciteta, no korisni su za dodavanja
mrežnih zrcala, koji se koriste za kopiranje podatkovnih tokova u stvarnom
vremenu.
·
Sustavi
za otkrivanje upada(IDS): u IDS dnevnicima sadržane su sve aktivnosti
procijenjene kao sumnjive. Ovi se dnevnici vode za naknadnu analizu i
otkrivanja načina sprječavanja sličnih sumnjivih događaja u budućnosti. U
dnevnicima su sadržane sljedeće
informacije; rezultati skeniranja portova, promet koji dolazi s
nepoznatih portova ili sumnjivim protokolima,prepoznate prijetnje kao što su
crvi, virusi, ili neovlašteni pokušaji pristupa mreži, anonimni pokušaji
korištenja FTP servisa mreže, IP adrese napadača, korišten bandwidth.
·
Sustav
za sprječavanje upada (eng. Intrusion
prevention system, kratica IPS): sustav blokira ili gasi primijećene
potencijalne prijetnje na mreži. IPS u dnevnicima zapisuje gotovo iste tipove
informacija kao i IDS, no njegova je glavna zadaća analizirati podatke na mreži
u stvarnom vremenu te utvrditi postoji li prijetnja sustavu.
·
Mrežni
pisači: U dnevnicima pisača mogu se pronaći dokumenti, slike i ostale
informacije poslane na ispis, ponekad i sa
pripadajućim metapodatcima. Na većinu je današnjih mrežnih pisača moguće postaviti agenta koji će
presretati sve podatke poslane na pisač.
·
Mrežni
uređaj za kopiranje: U njegovim se dnevnicima mogu pronaći slične informacije
kao i kod mrežnih pisača
·
Bežične
točke pristupa (eng. Wireless acess point
, kratica WAP): Dnevnici mu sadrže sve informacije kao i kod žičanog usmjerivača,
s dodatkom informacija kao što su SSID i dolazne pristupne veze.
4.5.3
Rekonstrukcija
događaja sa podatcima o prometu na mreži
Većina
mrežnih forenzičkih alata analiziraju prikupljene podatke te rekonstruiraju
događaje i vremenski tijek automatiziranim procesima, no poželjno je da
istražitelj razumije osnovne koncepte i načine na koji je alat došao do tih
rezultata.
Prvi
korak u analizi prikupljenih podataka jest korelacija vremenskih oznaka prikupljenih iz različitih
izvora, iza iste ili povezane podatke. Dave Mills, Universitiy of Delawear,
razvio je protokol koji sinkronizira sve
uređaje na mreži, te time otklanja potrebu ručnog postavljanja vremenskih
funkcija svake mrežne komponente. Protokol mrežnog vremena (eng. Network Time Protocol, kratica NTP),
održava vremenske postavke svih mrežnih
komponenti u milisekundu točnosti od Koordiniranog univerzalnog vremena (eng. Coordinated Universal Time, kratica
UTC).
Mrežna
komunikacija oslanja se na precizne vremenske oznake kako bi sve izmjene podataka
funkcionirale ispravno. Na primjer preciznost je veoma važna u sinkroniziranim
mrežama velike brzine, financijskom softveru, poslovnim komunikacijama, vojnim
aplikacijama itd..
Mrežne
komponente osim IDS i IPS, te sličnih
sustava sustava, samo prosljeđuju pakete i podatke do njihovog odredišta. IPS
sustavi analiziraju i podatke kako bi utvrdili postoji li prijetnja odredišnom
računalu, no za podatke se uglavnom brine host računalo mreže. Host računalo
koristi Transmission Control
Protocol/Internet Protocol (TCP/IP) protokol za slaganje podatkovnih tokova
podataka u razumnu cjelinu. Podatci se protokolom razlažu na pakete, šalju do
odredišta, te se tamo opet sastavljaju korištenjem sekvencijskih brojeva i potvrda.
Istražitelj pakete uhvaćene na
mreži može ponovo sastavit korištenjem njihovih sekvencijskih brojeva.
4.5.4
Raspoznavanje
različitih tokova podataka
Jedan od
načina raspoznavanja jednog toka podatak
od drugog, jest pregledom korištenog protokola pomoću kojeg su podatci poslani. Broj dostupnih protokola
zaista je velik, no većina proizvođača i softverskih kompanija koriste
standardne protokole kako bi osigurali kompatibilnost. U sljedećoj su listi navedeni najčešće
korišteni mrežni protokoli:
·
Address resolution protocol (ARP): Pronalazi
MAC adresu na temelju IP adrese drugog host
·
Internet control message protocol (ICMP): Šalje
poruke pogreške i ostalih informacija. Ping i Traceroute koriste ovaj protokol
·
Internet protocol security (IPSec):
Sigurnosni protokol koji kriptira ili autentificira pakete podataka
·
BitTorrent: Koriste ga peer to peer mreže za prijenos velikih
količina podataka
·
Domain name system (DNS): Prevode IP adrese u
ljudski čitljiva imena
·
Dynamic host configuration protocol (DHCP):
Host računala koriste ovaj protokol za dobivanje IP adresa na mreži
·
File transfer protocol (FTP): Pomaže
prijelazu podataka s jednog host računala na drugo, preko mreže
·
HyperText Transfer Protocol (HTTP): Prenosi podatke kao što su
internetske stranice s jednog host
računala na drugo
·
Internet message access protocol (IMAP): Koristi se
u sustavima elektroničke pošte
·
Network time protocol (NTP)
·
Post office protocol version 3 (POP3): Protokol
elektroničke pošte koji dobavlja elektroničke poruke na mreži
·
Secure shell (SSH): Stvara siguran kanal među host računalima na
mreži
·
Simple mail transfer protocol (SMTP): Protokol
elektroničke pošte, korišten za njeno slanje preko mreže
4.5.5
Mrežni
forenzički alati
Mrežni
alati sakupljaju podatke iz već postojećih dnevnika aktivnosti komponenti mreže, ili se instaliraju na mrežu
s ciljem sakupljanja podataka u realnom vremenu.
Mrežni
ispitni pristupi (eng Test Access
Port, kratica TAP) ključni su u mrežama koje
sadrže preklopnike, zbog toga što
preklopnici prosljeđuju podatke samo među portovima koji aktivno
komuniciraju. Mrežni TAP ugrađuje se izravno na mrežni medij te mogu nadzirati
sav promet koji dolazi i izlazi iz preklopnika na svim portovima. Kada podatci
stignu do preklopnika, kopira se cijeli tok dok oni nastavljaju putovati do
odredišta.
Mrežni
se TAP može smatrati stostrani hub velike brzine jer mu ne trebaju IP ili MAC
adrese, zbog toga što samo kopira podatke, i to sve od krivo formiranih paketa
do VLAN informacija. Moguće ga je instalirati na mreže ostvarene optičkim
vlaknima, bakrenim kabelima pa čak i WAN (eng. Wide Area Network). Omogućuje istovremeno kopiranje podataka s obije strane razmjene podataka na mreži.
TAP portovi ne zahtijevaju dodjeljivanje adresa
nevidljivi su svim sudionicima razmjene podataka na mreži, kako nisu
vidljivi nisu ni podložni napadima, jer čak iako netko primijeti malena
kašnjenja prilikom dostave podataka, nema načina da pronađe uzrok. Mane TAP
portova su da kopiraju sve, te ukoliko istražitelj ne filtrira podatke,
spremanje svog materijala može bit problematično. Druga mana jest da
udvostručuje količinu prometa na mreži ukoliko se koristi ista mreža koju se
nadzire za prebacivanje podataka na medij za pohranu.
Zrcala
Mrežni
usmjerivači i preklopnici koriste višestruke portove. Preslikavanje portova
koristi se kada je potrebno promet svesti na jedan port gdje IDS analizira
promet, te pronalazi potencijalno opasne podatke, ili alat za forenzičku
analizu i sigurnost.
Način
na koji preklopnik ili usmjerivač prenosi podatke s jednog porta na drugi, i
kako brzo, ograničavaju korisnost zrcala (eng. Mirrors). Na mrežama velike brzine
gubljenje podataka zbog kolizija , te odbačenih podataka povećava se porastom
prometa na mreži. Ukoliko se u tom slučaju sav promet zrcali na jedan port,
mrežni se uređaj zakrči podatcima. Najčešća uporaba zrcaljenja portova je
kopiranje mrežnog prometa određenog računala ili korisnika. Zrcalu je moguće
pristupiti s udaljene lokacije, stoga je ranjivo za napade i promjene
konfiguracija.
Promiskuitetni NIC
Ova
se metoda prikupljanja i nadziranja podataka ne koristi često. NIC je kartica
mrežnog sustava, a dualan spoj na mrežu omogućava nadzor i skeniranje mrežnog
prometa. Jedna od prednosti korištenja ovog tipa TAP-a jest ta da je ugrađen
direktno u računalo istražitelja, stoga se podatci ne moraju prenositi preko
mreže do medija za pohranu. Ova mu je činjenica ujedno i mana, jer nije
efektivno mobilan.
Bežične mreže
U
mrežama ostvarenim bakrenim kabelima ili kabelima s optičkim vlaknima,
informacije su zarobljene u tom kabelu, te ukoliko netko želi pristup tim
informacijama mora se fizički spojiti na mrežu. Bežične mreže šalju sve
informacije zračnim putem, i svatko s antenom pri ruci može kopirati i sačuvati
poslane podatke. TAP mora biti pasivan sustav kako i prikrio svoje postojanje i
bio zaštićen od napada. S sklopovskog gledišta , može se koristiti bilo što što
je sposobno primati podatke na pravoj frekvenciji, kao što su NIC kartice ili
primaoc radio frekvencija. Važan aspekt pregleda mrežnog prometa je koji se tip
softvera koristi za pregled i analizu podataka. Prijenosno računalo s bežičnom
karticom može snimati mrežni promet jer već posjeduje ugrađene protokole koji
prevode bežični signal u digitalni kod koji OS razumije. Program po imenu
Kismet koristi NIC kartice, te može raditi pod različitim operacijskim
sustavima. On generira dnevnike koji su kompatibilni s većinom IDS i forenzičkih sustava, te time olakšava
analizu prikupljenih podataka. Treba imati na umu da su podatci koji putuju među
bežičnih točaka pristupa paketi, no ako se podatci presretnu prije nego što
napuste bežičnu točku pristupa, ili nakon što stignu u nju, te dohvatiti
podatke u originalnom obliku.
4.6
Istraživanje
dosjea X: Egzotična forenzika
Digitalna
budilica i brojilo potrošnje električne energije točan su pokazatelj kada se
budimo, računalni dnevnici bilježe informacije
koje korisnik traži i vrijeme kada ih je tražio, alarmni sustavi bilježe
odlaske i dolaske ukućana, mobilnim telefonom moguće je utvrditi lokaciju osobe
računalna blagajna bilježi transakcije debitnih kartica, svaki dio naše
svakodnevnice obilježen je korištenjem digitalnih uređaja koji na neki način
bilježe naše navike i kretanja.
U
ovom su poglavlju navedeni neki od uređaja iz ljudske svakodnevnice iz kojih je
moguće izvući određenu količinu korisnih informacija.
4.6.1
Telefonske
automatske sekretarice
Pregled i akviziciju podataka s digitalne automatske
sekretarice potrebno je pristupiti mikročipu za pohranu podataka, preslušati
govorne poruke, ili spojiti uređaj s računalom. Današnje su sekretarice zapravo
digitalni audio snimači spojeni na telefonsku liniju. Većina ih dolazi s USB
portom, kako bi se uređaj mogao spojiti s računalom zbog dohvata ili pohrane
važnih poruka. Sekretarice s USB priključcima smatraju samo još jednim medijem
za pohranu podataka. Korisnici veoma jednostavno dokumente, podatke slike te ostale informacije mogu sakriti upravo na
digitalnu automatsku sekretaricu. Pregled, akvizicija i analiza podataka
obavljaju se kao i kod bilo kojeg medija za pohranu podataka.
4.6.2
Pregled
sustava za video nadzor i kućnih sigurnosnih sustava
Uređaji
za kućnu zabavu kao što su digitalni video snimači (eng digital video recorder, skrać DVR) mogu
služiti kao eksterni tvrdi diskovi. DVR tehnologija koristi se i u nadzornim
sustavima. Većina DVR uređaja koristi
tvrde diskove za pohranu video zapisa. Standardnim je forenzičkim
postupkom moguće izraditi sliku prostora
za pohranu, te analizu podataka na njemu.
Većina
kućnih sigurnosnih sustava ukomponirani
su u mala računala s minimalnim OS i nekoliko sklopovskih komponenti. Ovi
sustavi koriste medij za pohranu podataka za čuvanje dnevnika događaja,
sigurnosnih šifri, i konfiguracijskih postavki koji je kod korišten i koda za
aktivaciju, odnosno deaktivaciju sigurnosnog sustava. Ukoliko svaka osoba
posjeduje svoj kod, moguće je jednostavno utvrditi osobu i vrijeme pristupa
sigurnosnom sustavu. Ovi se sustavi mogu isprogramirati za obavljanje određenih
akcija u određenim vremenskim intervalima, stvarati nove šifre, izgasiti nadzor
na određenim dijelovima, kompletno se isključiti, uključiti. Sve se te akcije
mogu pregledati i analizirati u dnevniku događaja.
4.6.3
Praćenje
automobila
Praćenje
automobila nikada nije bilo jednostavnije korištenjem GPS tehnologije. Koncept
GPS tehnologije jednostavna je: primaoc (eng. receiver) koristi satelitske signale kako bi utvrdio poziciju
automobila s preciznošću od nekoliko metara. Implementacije je malo složenija,
kada se doda satelite, atmosferske interferencije i efekte refleksije i
raspršenja radio valova, izračun lokacije nije toliko jednostavan. Sustav
koristi grupu od 24 satelita u Zemljinoj orbiti, i moguće je s razumnom
točnošću utvrditi gdje se primaoc nalazio u određenom trenutku. Noviji GPS
uređaji sadrže medij za pohranu podataka, ugrađeni MP3 player, te sučelja za
spajanje s mobilnim uređajima putem Bluetootha
izravnom vezom, ili USB kabelom. GPS
uređaji sadržavaju mnogo korisnih informacija, a kako se mogu spajati sa
računalom, njihov se prostor za pohranu podataka kopira, ispituje i analizira
kao i svaki drugi medij za pohranu podataka.
4.6.4
Identifikacija
radio frekvencijom
U
metodi identifikacije radio frekvencijom, ili RFID, koriste se veoma mali
odašiljači male snage. Primaoc (eng. receiver)
prima signal kojim može identificirati osobu, životinju ili objekt. U svom
najjednostavnijem obliku RFID odašiljač odašilje signal radio frekvencije
kodiran identifikacijskim brojem. Kada čitač primi kodirani signal, pretvara ga
u digitalni i prosljeđuje uređaju na koji je priključen. RFID koristi na
benzinskim postajama, automatima s kavom ili grickalicama koji imaju mogućnost plaćanja karticama,u
supermarketima, kućnim ljubimcima za utvrđivanje lokacije i identifikaciju, kasinima,
identifikacijskim sustavima studenata, zaposlenika, putovnica.
S
forenzičkog stajališta, pomoću FRID može se rekonstruirati kretanje osobe ili
objekta. Kako RFID sustavi rade s
frekvencijama radio valova, svatko s pravim tipom primaoca može presresti
signal [12].
5. Digitalna forenzika slika
Digitalne slike nastale uporabom raznih uređaja koriste se u sve većem broju područja; od vojnih i nadzornih do medicinskih dijagnoza te komercijalne uporabe i privatne fotografije. Sukladno tome, niz novih forenzičkih problema proizlazi iz tako ubrzanog rasta napretka i raširenosti uređaja koji mogu generirati digitalnu sliku. Na primjer, možemo se zapitati kakvi se tipovi sklopovskih i programskih komponenti koriste u tim uređajima. Analizom digitalne fotografije utvrđujemo korišteni senzor . Kako je dobivena slika? Jeli nastala u mobilnom telefonu, kameri, video kameri, fotografskim skenerom ili je stvorena umjetno korištenjem softvera za obradu fotografija? Je li slika manipulirana nakon stvaranja, je li autentična ili modificirana na neki način? Sadrži li sakrivene podatke ili steganografski sakrivene informacije? Mnoga se forenzička pitanja mogu ogovoriti pronalaskom mjesta nastanka digitalne fotografije ili njenog procesa stvaranja. Znanje o metodama akvizicije slika mogu pomoći pri odgovaranju na buduća forenzička pitanja koja se tiču prirode dodatnog procesiranja kojima je slika mogla biti podvrgnuta nakon nastanka.
5.1
Forenzika
komponenti kamera
Forenzika komponenti teži identifikaciji algoritama i parametara upotrijebljenih u raznim komponentama uređaja korištenih za generiranje slika. Analizom komponenti traži se intrinzične otiske i tragove koji su ostali na digitalnoj slici nakon blokova procesiranja u informacijskom procesnom lancu, potom se te tragove koristi kako bi se mogli procijeniti parametri komponenti. Nakon procjene parametara intrinzičnim identifikacijama otisaka, forenzika komponenti koristi se kao baza za obradu težih forenzičkih problema kao što su otkrivanje kršenja prava i patenata uređaja ili korištene tehnologije, zaštita prava intelektualnog vlasništva, te identifikacija uređaja.
Učestali način utvrđivanja krađe intelektualnog vlasništva pregled je dizajna i implementacije proizvoda, te traženje sličnosti s uređajima za koje se tvrdi kako već postoje patenti. Ovaj pristup može biti veoma zamoran, ne efikasan i iziskuje mnogo vremena, a u većini bi slučajeva zahtijevao usporedbu linije po linije koda softverskih modula uređaja. Forenzika komponenti pruža sistematičnu metodologiju za otkrivanje kršenja patentnih prava identifikacijom algoritama i parametara korištenih u svakoj komponenti procesnog informacijskog lanca štiteći time prava intelektualnog vlasništva.
Forenzika komponenti služi i kao temelj utvrđivanja vjerodostojnosti slika i fotografskih uređaja. S brzim razvojem alata za manipulaciju multimedijalnih podataka, sve je važniji integritet sadržaja kao i uređaja s kojeg je sadržaj dobavljen, pogotovo kada se koristi kao dokaz na sudu, istrazi, novinarstvu, vojnom obavještavanju... Na primjer, informacije o modulima sklopovlja i programskih komponenti te njihove parametre u uređajima pomažu u izgradnji sustava identifikacije uređaja. Takvi su sustavi korisni prilikom akvizicije podataka koje provode razne organizacije, kompanije i forenzički istražitelji, kao i za utvrđivanje koji se uređaj ili tip uređaja koristilo za dobivanje određene slike. Forenzika komponenti pomaže pri izradi modela za definiranje karakteristika slike dobavljene s nekog tipa uređaja, te time olakšavaju forenzičkim alatima utvrđivanje postojanja modifikacija u slikama. Nadalje, poznavanjem karakteristika slike i modela uređaja na kojem je nastala moguće je utvrditi koji se tip procesiranja obavljao nad slikom otkako je napustila medij za pohranu originalnog uređaja.
Forenzika komponenti može se provoditi na tri načina ovisno o prirodi dostupnih informacija i ulaznih podataka:
·
U invazivnoj
forenzici istražitelj ima pristup uređaju, može ga rastaviti, izolirati
svaku komponentu, te utvrditi individualne parametre tih komponenti određenim metodama.
·
U slučaju djelomice neinvazivne forenzike istražitelj i dalje ima pristup uređaju, no ne smije ga
rastavljati ; u tom slučaju može sastaviti određene ulazne podatke koje unosi u
uređaj kako bi prikupio procesorne metode
i parametre individualnih komponenti.
·
U kompletno neinvazivnoj forenzici istražitelj
procjenjuje parametre komponenti na temelju uzoraka podataka dostupnih
na uređaju [3].
5.1.1
Metodologije forenzike komponenti
Kada se scena iz stvarnog svijeta želi uslikati korištenjem digitalne kamere, informacije o sceni prolaze kroz različite uređaje dok na kraju ne nastane digitalna slika. Svaka od tih komponenti u lancu procesiranja informacije modificira ulaz specifičnim algoritmima i skupom parametara, te ostavljaju intrinzične otiske i tragove na slici. U nastavku su ukratko opisane neke od metoda koje neinvazivno procjenjuju parametre raznih komponenti kamere .
Slika 5.1 Obrada informacija u digitalnim kamerama
Procjena funkcije odgovora kamere
Funkcija odgovora kamere (eng camera response function, kratica CRF) mapira energiju svijetla scene u vrijednosti intenziteta slike. CFR se koriste u nekoliko aplikacija kao što su algoritmi računalnog vida korištenim za utvrđivanje oblika objekta iz sjene, autentifikacijskim algoritmima gdje se CFR koristi kao prirodni vodeni žig. Za procjenu CFR trenutno se najčešće koriste eksperimentalni nelinearni modeli koji polučuju djelomično uspješne rezultate, dok se metode procjene CFR na temelju fotografija još uvijek istražuju.
Procjena mreže filtera boje i interpolacijskih parametara
Za komponente kao što su CFA i moduli interpolacije boja, znanje o komponentama izlaza daje kompletne informacije o ulaznim podatcima jer su ulaz i izlaz u korespondenciji s uzorcima interpoliranih podataka. Za procjenu koeficijenata interpolacije boja koristi se između ostaloga i EM algoritam. Prvo pretpostavimo kako pixeli slike pripadaju jednom od dvaju modela
1. Pixel
je linearno koreliran sa svojim
susjedima i dobiva se algoritmom linearne interpolacije
2. Pixel
nije koreliran sa svojim susjedima
Na tim se pretpostavkama izvodi iteracijski dvokoračni EM algoritam. U koraku očekivanja, izračunavaju se vjerojatnosti o pripadnosti modelima za svaki uzorak, dok se u koraku maksimizacije nalaze specifični oblici korelacije među pixelima. EM algoritam generira dva izlaza: dvodimenzionalnu mapu vjerojatnosti koja sadrži koeficijente vjerojatnost pripadnosti pixela jednoj od dviju mogućnosti i težinske koeficijente. Procijenjene mape vjerojatnosti mogu se efikasno koristit pri otkrivanju jeli slika u boji rezultat interpolacije ili ne. Koeficijenti interpolacije pomažu pri razlikovanju različitih algoritama interpolacije.
Slika 5.2 Algoritam za procjenu CFA i interpolacijskih koeficjenata
Procjena post interpolacijskog procesiranja
Operacije procesiranja kao što su balansiranje bijele boje, te korekcije boja kamere provode nakon interpolacije boje kako bi se osiguralo da objekt koji je bijel u stvarnom svijetu, tako izgleda i na fotografiji. Operacije balansiranja bijele boje tipično su multiplikativne i svaka se boja u fotografiji umnaža za odabranu konstantu puta u prostoru boja kamere. Zbog multiplikativne prirode operacije balansiranja bijele boje one ne mogu biti procijenjene analizom samo jedne fotografije neinvazivnim metodama s prihvatljivom razinom točnosti. Preciznije se mogu procijeniti djelomice neinvazivnom metodom u dva koraka: prvo se dobave dvije fotografije s različitim ugrađenim postavkama balansiranja bijele boje, i tada se rješava niz jednadžbi korištenjem Von-Kreis hipoteze.
JPEG kompresija još je jedna popularna post interpolacijska procesna komponenta u digitalnim kamerama. JPEG kompresija može se smatrati kvantizacijom na razini diskretne kosinusne transformacijske domene. U ovom slučaju izlaz komponente, ne daje nam kompletne informacije o pripadajućem ulazu; ali pruža grubu procjenu ulaznih informacija unutar dosega veličine kvantizacijskog koraka. Statistička se analiza zasnovanu na binning metodama koje se koriste za neinvazivno predviđanje kvantizacijske matrice. Ti algoritmi daju dobre rezultate u procjeni veličine kvantifikacijskog koraka.
5.1.2
Primjena
forenzike komponenti
U nastavku su ukratko opisane neke od primjena forenzike komponenti koje prikazuju kako se koriste intrinzični tragovi zapisani u digitalnim fotografijama, na koja pitanja pružaju odgovore i kakve se dokaze iz njih može izvući [3].
Forenzika identifikacije kamera
Procijenjeni parametri komponenti kamera mogu se koristit kao faktori za identifikaciju modela i tipa kamere korištene za izradu ispitivane digitalne fotografije. Kao metoda za identifikaciju kamera pomoću parametara komponenti koristi EM algoritam. Sa njime se procjenjuju težinski koeficijenti, te lokacije maksimuma i veličine frekvencijskog spektra mape vjerojatnosti. Za ispitivanje metode koriste se slike uslikane dvjema kamerama s kontroliranim ulaznim vrijednostima, zajedno sa nasumce dobavljenom slikom s interneta ili usnimljene trećom kamerom.
Druge metode predlažu veći broj karakteristika za identifikaciju kamere: prosječnu vrijednost pixela, RGB parove korelacije, energetske vrijednosti omjera RGB, statistike domene waveleta, te metrike kvalitete slike. Za klasifikaciju se koriste i Support Vector Machines (kratica SVM) kojima se postiže visoka točnost klasifikacije.
Forenzička analiza kršenja autorskih prava, povreda intelektualnog vlasništva i licenciranja
Forenzika komponenti može se koristiti za identifikaciju osnovnih osobina vezanih uz određeni uređaj prilikom potvrđivanja kršenja autorskih prava i licenciranja komponenti uređaja. Metode klasifikacije na primjer koriste sličnosti u algoritmima interpolacije koje koriste različite kamere.
Otkrivanje izreži i kopiraj krivotvorina, na temelju nekonzistentnosti u parametrima komponenti
Stvaranje modificirane slike kopiranjem dijela slike često uključuje dobavljanje različitih dijelova slike od fotografija slikanih različitim kamerama koje vjerojatno koriste različite skupine algoritama tj parametara u internim komponentama. Nedosljednosti u procijenjenim uzorcima senzora dobivenih iz različitih dijelova slike ili nedosljednosti u intrinzičnim tragovima otisaka (kao što su interpolacijski koeficijenti ili CFR), koje ostavljaju komponente kamere mogu se koristit za identifikaciju digitalnih krivotvorina nastalih kopiranjem, rezanjem ili slaganjem dijelova fotografiju novu sliku.
Forenzika komponenti kao dio osnovnog modela otkrivanja krivotvorina
Operacije procesiranja slika uključuju očuvanje sadržaja i manipulacije promjene sadržaja. Procesiranje obavljeno na slici nakon izlaska iz kamere generalno se teško otkriva i procjenjuje zbog nedostatka informacija o tipu manipulacija što vodi do pogrešnih izbora modela. Za otkrivanje manipulacija bez fokusa na identifikaciju tipa manipulacije ili njegovih parametara provodi se analizom varijance i wavelet statistika višeg reda. Ove metode zahtijevaju uzorke manipuliranih i nemanipuliranih slika kako bi se statističke vrijednosti mogle predstaviti klasifikatoru, te naučiti granica klasifikacije koja će istraživanu sliku smjestiti u jedan od razreda ovisno o njenim statističkim svojstvima. Mana ovih metoda je ta da možda neće biti u stanju ispravno klasificirati slike manipulirane metodom koja nije uzeta u obzir prilikom njihove konstrukcije [3].
5.2
Neuniformnost
fotografskih senzora
U ovom se poglavlju
opisuju načini kako se neuniformnost izlaza (eng. Photo response nonuniformity, kratica PRNU) fotografskih senzora
može koristiti za raznovrsne forenzičke zadaće kao što su identifikacija
uređaja, povezivanje uređaja i fotografije, povratak procesne povijesti i
otkrivanje digitalnih krivotvorina [2].
PRNU intrinzično je
svojstvo svih digitalnih fotografskih senzora koji nastaje zbog neznatnih
varijacija među individualnim pixelima u njihovoj sposobnosti pretvorbe fotona u elektrone. Svaki senzor otpušta slab uzorak sličan šumu u svaku sliku koju generira. Ovaj uzorak koji
se može smatrati identifikacijskim otiskom
senzora, u biti je nenamjeran stohastički vodeni žig raširenog spektra
koji preživljava procesiranje, kompresiju s gubitcima ili filtraciju.
Postoje dva tipa
fotografskih senzora koji se najčešće nalaze u digitalnim kamerama,
fotoaparatima i skenerima: charge coupled
device CCD uređaj, i komplementarni metal oksid poluvodič (eng. complemetrary metal oxide semiconductor,
kratica CMOS). Sastoje se od velikog broja foto detektora, koji se još nazivaju
i pixelima. Pixeli se izrađuju od silikona i hvataju svjetlo pretvarajući
fotone u elektrone koristeći fotoelektrični efekt. Akumulirani se naboj prenosi
van senzora, amplificira, i tada pretvori u digitalni signal koristeći A/D
pretvornik. signal se dalje procesira
prije pohrane podatka u formatu slike kao što je Joint Photographic Experts Group
(kratica JPEG).
Pixeli su obično
pravokutnog oblika, duljine nekoliko mikrona. Količina elektrona koje uzrokuje
svjetlo incidenta u svakom pixelu ovisi o fizičkim dimenzijama fotosenzitivnog
područja pixela i o homogenosti silikona. Fizičke dimenzije pixela
variraju neznatno zbog nesavršenosti
proizvodnog procesa. Nehomogenost koja je prirodno prisutna u silikonu pridonosi
varijacijama u kvantnoj efikasnosti među pikselima tj. sposobnosti pretvaranja
fotona u elektrone. Različitosti među pixelima mogu se zabilježiti matricom ![]() koja
je istih dimenzija kao senzor. Kada se
fotografski senzor osvijetli s idealno uniformnim svjetlom intenziteta
koja
je istih dimenzija kao senzor. Kada se
fotografski senzor osvijetli s idealno uniformnim svjetlom intenziteta ![]() , u odsutnosti drugih izvora šuma senzor će
registrirati signal sličan šumu oblika
, u odsutnosti drugih izvora šuma senzor će
registrirati signal sličan šumu oblika ![]() . Izrazom
. Izrazom ![]() obično se označava PRNU.
obično se označava PRNU.
Matrica ![]() odgovorna je za veliki dio onoga što nazivamo
identifikacijski otisak kamere. Otisak se može
procijeniti eksperimentalno, na primjer
slikanje fotografija jednoliko osvijetljenih površina, te računanje
srednjih vrijednosti slika kako bi se izoliralo sustavsku komponentu svih
slika. U isto vrijeme srednja vrijednost
pobija slučajne komponente šuma kao što su shot
noise odnosno nasumična varijacija u broju fotona koji stignu do
pixela uzrokovano kvantnim svojstvima
svjetlosti, the read out šum nasumični šum uveden tijekom očitanja
senzora, itd..
odgovorna je za veliki dio onoga što nazivamo
identifikacijski otisak kamere. Otisak se može
procijeniti eksperimentalno, na primjer
slikanje fotografija jednoliko osvijetljenih površina, te računanje
srednjih vrijednosti slika kako bi se izoliralo sustavsku komponentu svih
slika. U isto vrijeme srednja vrijednost
pobija slučajne komponente šuma kao što su shot
noise odnosno nasumična varijacija u broju fotona koji stignu do
pixela uzrokovano kvantnim svojstvima
svjetlosti, the read out šum nasumični šum uveden tijekom očitanja
senzora, itd..
Osim PRNU,
identifikacijski otisak kamere sadrži
sve sustavske defekte senzora
uključujući i užarene i mrtve pixele (eng. Dead and hot pixels) koji konzistentno proizvode izlaze visokog i niskog iznosa neovisno o iluminaciji, i tako zvanu
tamnu struju (eng. Dark curent) uzorak sličan šumu koji se dobiva slikanjem s zatvorenim objektivom. No najvažnija
komponenta otiska jest PRNU.
PRNU je
slabo prisutan u tamnim područjima gdje
je intenzitet svjetlosti približno jednak nuli. Dijelovi slike gdje su pixeli popunjeni do krajnjih granica,
te daju samo konstantan signal, ne nose tragove PRNU, ili bilo kakvog drugog
šuma. Svi su fotografski senzori građeni
od poluvodiča, i njihove su proizvodne tehnike slične, stoga će njihovi otisci
biti sličnih svojstava . Iako je PRNU stohastičke naravi, relativno je stabilna
komponenta senzora tijekom njegova životnog vijeka. Faktor ![]() je
veoma korisna forenzička veličina zaslužna za jedinstven identifikacijski
otisak senzora sa sljedećim svojstvima:
je
veoma korisna forenzička veličina zaslužna za jedinstven identifikacijski
otisak senzora sa sljedećim svojstvima:
·
Dimenzionalnost:Otisak prsta je stohastički
po prirodi i sadrži veliku količinu informacija
što ga čini jedinstvenim za svaki senzor
·
Univerzalnost: svi senzori ostavljaju PRNU
·
Generalnost: Otisak prsta prisutan je u
svakoj slici nezavisno o optici kamere, njenim postavkama ili sadržaju scene
fotografije, s iznimkama kompletno tamnih slika
·
Stabilnost: Stabilan je u vremenu i kroz
širok spektar uvjeta kao što su visoka
ili niska temperatura te vlažnost
·
Robusnost: Preživljava kompresiju s
gubitcima, filtriranje, gama korekcije, te mnoge druge procedure procesiranja
Identifikacijski
otisak digitalne kamere može se koristiti u mnogim forenzičkim situacijama i
zadaćama. Prilikom ispitivanja postojanja specifičnog otiska u slici može se
arhivirati za pouzdane identifikacije uređaja (npr. kako je određena slika
nastala na određenoj kameri) ili dokazati da su dvije slike slikane istim
uređajem. Ova se metoda naziva povezivanje uređaja (eng. Device linking).
Prisutnost
otiska kamere na slici indikativna je
činjenica da je istraživana slika prirodna, a ne računalno stvorena ili
krivotvorine. Kada se ne ustanovi postojanje otiska senzora na pojedinim
regijama slike, to može ukazivati na zamijenjene dijelove slike i njenu
manipulaciju. Ovaj zadatak spada u provjeru integriteta slike. Utvrđivanjem
snage ili oblika otiska moguće je
rekonstruirati povijest procesiranja. Na primjer, identifikacijski otisak
kamere može se koristiti kao obrazac za procjenu geometrijske obrade kao što je
skaliranje, rezanje ili rotacija. Negeometrijske operacije također utječu na jačinu otiska u slici i mogu se potencijalno otkriti. Spektralne i
prostorne karakteristike otiska mogu se koristiti prilikom identifikacije
modela kamere ili provjere radi li se o skeniranoj slici koja pokazuje
prostornu aniztropiju (dobivaju se različiti podatci mjerenjima u različitim orijentacijama) ili o digitalnoj
fotografiji.
Metode procjene
identifikacijskog otiska modela kamere
ili njegovo otkrivanje u slikama zasniva se na statističkim procjenama signala
i teoriji detekcije. Za opis metoda koristi se model pojednostavljenog senzorskog izlaza, koji se koristi za
procjenu najveće vjerojatnosti otiska.
Procijenjeni se
signal preprocesuira kako bi se otklonili određeni sustavski uzorci koji bi
mogli povećati krivu klasifikaciju pri
određivanju kamera i pogrešaka pri verifikaciji integriteta slike. Zadaća
otkrivanja PRNU formulira se kao dvokanalni problem i pristupa mu se korištenjem testa
generaliziranog omjera vjerojatnosti u Neyman-Pearson postavkama. Prvo se
određuje detektor za identifikaciju uređaja, tek se nakon toga prilagodi za
povezivanje fotografije s kamerom i uspoređivanje identifikacijskih
otisaka dvaju slika.
5.2.1
Procjena
identifikacijskog otiska senzora
PRNU se ugrađuje u sliku tijekom faze akvizicije, a prije kvantizacije signala ili bilo kojeg drugog tipa procesiranja. Kako bi se izradio algoritam za procjenu identifikacijskog otiska senzora mora se formulirati model senzorskog izlaza (eng. Sensor output).
Iako je proces nastanka digitalne slike kompleksan i znatno varira ovisno o modelu korištene kamere, neki su osnovni elementi zajednički svim kamerama. Svjetlo koje dolazi iz optike kamere projicira se na mrežu pixela fotografskog senzora. Naboj koji nastaje interakcijom fotona i silikona kvantizira se i amplificira. Tada se signal iz svakog kanala boje uštima kako bi dobili skalirani dobitak i balansirani postotak bijele boje.
Kako većina senzora ne može registrirati boje, pixeli su opremljeni filtrima za boje koji propuštaju samo svijetlost specifične valne duljine, odnosno boje (crven, plavi, zelen). Mreža filtera naziva se mreža filtera boje (eng. collor filter aray, skrać CFA). CFA tanki je film na senzorima koji selektivno propušta određene komponente svijetlosti da prođu kroz njega do senzora. Kako bi dobili sliku u boji signal se interpolira.
Boje je moguće dalje podesiti na računalu koristeći gama korekcije i korekcije boja kako bi se prikazivale ispravne nijanse. Kamere mogu provoditi i tehnike filtriranja kao što su odšumljivanje ili pooštravanje. Na samom kraju lanca procesiranja slika se sprema u JPEG formatu, ili nekom drugom, što uvjetuje kvantizaciju slike.
U praksi, za dobivanje dobre provjere identifikacijskog otiska senzora potrebno je od dvadeset do pedeset fotografija, ovisno o modelu i tipu kamere.
5.2.2
Identifikacija
kamere korištenjem identifikacijskog otiska senzora
U nastavku je opisana metodologija otkrivanja porijekla slike ili video zapisa koristeći identifikacijski otisak senzora [2]. Najčešće se u praksi provode identifikacije uređaja na temelju prikupljenih slika. Ovdje je zadatak odrediti je li određena slika nastala uporabom određenog fotoaparata. To se postiže ispitivanjem rezidualnog šuma slike, te utvrđivanjem posjeduje li identifikacijski otisak kamere.
Predviđajući dva sljedeća usko povezana forenzička zadatka formulira se hipoteza ispitnog problema identifikacije kamera u okruženju koje je dovoljno općenito kako bi pokrilo preostale zadatke povezivanja kamere i utvrđivanje sličnosti identifikacijskih otisaka. Prilikom utvrđivanja veze između fotografije i kamere, dvije se slike uspoređuju kako bi se utvrdilo da potječu iz iste kamere pošto sama kamera možda i nije dostupna za analizu.
Zadatak ispitivanja dva procijenjena identifikacijska otiska izvršava se i prilikom usporedbe dvaju video zapisa jer se individualni video okviri koriste kao sekvence, a iz niza slika iz moguće je dobiti identifikacijski otisak video kamere.
U svakoj forenzičkoj aplikaciji važno je smanjiti broj lažno pozitivnih rezultata prilikom analize. Prilikom identifikacije kamera to znači da vjerojatnost kako ispitivana kamera nije stvorila fotografiju mora biti ispod nekog korisnički određenog praga.
Identifikacijski se otisak kamere procjenjuje zasebno za svaki kanal boje zasebno koristeći estimator maksimalne vjerojatnosti (eng maximum likelihood estimator) od pedesetak slika plavog neba dobavljenih u TIFF formatu. Procijenjeni se otisci procesiraju korištenjem procedure svođenja srednja vrijednosti u stupcima i recima na nulu kako bi se otklonili preostali uzorci koji nisu jedinstveni za taj senzor. Ovaj je korak veoma važan jer bi ti artefakti stvarali nepotrebne smetnje na određenim prostornim pomacima i skaliranjima faktora smanjili PCE, te povećali vjerojatnost lažno pozitivne klasifikacije. Identifikacijski otisci procijenjeni za sva tri kanala boje kombiniraju se u jedan otisak korištenjem linearnog konverzijskog pravila pretvaranja slika u boji u crno bijele
![]()
gdje ![]() predstavlja procjenu najveće vjerojatnosti od
matrice
predstavlja procjenu najveće vjerojatnosti od
matrice![]() .
.
5.2.3
Otkrivanje
krivotvorina korištenjem
identifikacijskog otiska kamere
Identifikacijski se otisak kamere koristi i za potvrđivanje integriteta slika. Određeni tipovi modifikacija slika mogu se identificirati otkrivanjem otisaka na manjim regijama, kao što su blokovi. Pretpostavka je kako regija kopirana s drugog dijela slike ili sasvim druge fotografije neće sadržavati ispravan identifikacijski otisak, no treba uzeti u obzir kako neke modifikacije neće uništiti ili modificirati PRNU, te ih neće biti moguće otkriti korištenjem ove metode. Dobar je primjer promjena boje mrlje, da izgleda kao mrlja krvi [2].
Algoritam otkrivanja krivotvorina ispituje prisutnost otiska
u svakom bloku veličine ![]() zasebno, i tada spaja sve lokalne rezultate u
identifikacijski otisak. Za svaki se
blok
zasebno, i tada spaja sve lokalne rezultate u
identifikacijski otisak. Za svaki se
blok ![]() ,
algoritam detekcije formulira kao hipoteza koja ispituje
,
algoritam detekcije formulira kao hipoteza koja ispituje

Gdje ![]() predstavlja ostatak šuma u bloku,
predstavlja ostatak šuma u bloku, ![]() pripadajući je otisak bloka,
pripadajući je otisak bloka, ![]() predstavlja intenzitet bloka, a
predstavlja intenzitet bloka, a ![]() predstavlja modelirani šum za koji se
uzima da je bijeli Gaussov šum (eng White Gaussian noise) s nepoznatom varijancom
predstavlja modelirani šum za koji se
uzima da je bijeli Gaussov šum (eng White Gaussian noise) s nepoznatom varijancom
![]() .
Omjer vjerojatnosti testa je normalizirana korelacija
.
Omjer vjerojatnosti testa je normalizirana korelacija
![]()
Prilikom otkrivanja krivotvorina, mora se kontrolirati oba tipa pogreške; neuspjeh identifikacije manipuliranog bloka, te pogrešna identifikacija nemanipuliranog kao manipuliranog. Iz ovog se razloga procjenjuju distribucije ispitnih statistika za obije hipoteze.
Gustoća vjerojatnosti
![]() može se procijeniti korelacijom poznatih
signala
može se procijeniti korelacijom poznatih
signala ![]() ostatcima šuma
nekih drugih kamera. Distribuciju
ostatcima šuma
nekih drugih kamera. Distribuciju ![]() u
u ![]() mnogo je teže dobiti jer na nju jako utječe
sadržaj bloka. Tamni blokovi imaju manju
vrijednost korelacije zbog
multiplikativnog karaktera PRNU.
mnogo je teže dobiti jer na nju jako utječe
sadržaj bloka. Tamni blokovi imaju manju
vrijednost korelacije zbog
multiplikativnog karaktera PRNU.
Identifikacijski
otisak ne mora biti prisutan u bloku zbog jake JPEG kompresije ili
zasićenosti pixela (eng. saturation).
Teksturirana područja imati će niže vrijednosti korelacije zbog jakih šumova
modeliranja. Ovaj se problem može riješiti građenjem prediktora korelacija
koji je u stanju utvrditi vrijednost
ispitne statistike ![]() i njenu distribuciju ako blok
i njenu distribuciju ako blok ![]() nije modificiran i zaista potječe od
ispitivane kamere. Prediktor je zapravo karta, mapa koja se mora stvoriti za
svaki model kamere posebno. Mapiranjem se dodjeljuju procjene korelacija
nije modificiran i zaista potječe od
ispitivane kamere. Prediktor je zapravo karta, mapa koja se mora stvoriti za
svaki model kamere posebno. Mapiranjem se dodjeljuju procjene korelacija ![]() svakoj trojci (
svakoj trojci (![]() ),
koji predstavljaju mjeru intenziteta, zasićenost i teksture bloka
),
koji predstavljaju mjeru intenziteta, zasićenost i teksture bloka ![]() .
Mapiranje se provodi korištenjem regresije ili metodom strojnog učenja,
trenirajući klasifikatore na bazi
podataka blokova slika koji su nastali u
ispitivanoj kameri. Veličine blokova variraju od veličine 64x64 do 128x128
pixela, previše maleni blokovi uvode varijancu u korelaciju
.
Mapiranje se provodi korištenjem regresije ili metodom strojnog učenja,
trenirajući klasifikatore na bazi
podataka blokova slika koji su nastali u
ispitivanoj kameri. Veličine blokova variraju od veličine 64x64 do 128x128
pixela, previše maleni blokovi uvode varijancu u korelaciju ![]() ,
a korištenjem previše velikih blokova kompromitiralo bi sposobnost algoritma za
detekciju krivotvorina da lokalizira manipulacije. Kako se dijeljenjem slike na
blokove može dobiti veoma velik broj blokova, za konstrukciju i treniranje
prediktora dovoljno je otprilike deset.
,
a korištenjem previše velikih blokova kompromitiralo bi sposobnost algoritma za
detekciju krivotvorina da lokalizira manipulacije. Kako se dijeljenjem slike na
blokove može dobiti veoma velik broj blokova, za konstrukciju i treniranje
prediktora dovoljno je otprilike deset.
Algoritam djeluje sljedećim koracima: podijeli sliku na
određen broj blokova fiksne veličine, te ispituje ispitnu statistiku ![]() za svaki blok. Decizijski prag
za svaki blok. Decizijski prag![]() za ispitnu statistiku postavlja se tako
da se vjerojatnost identifikacije
modificiranog bloka kao nemodificiranog svede na
za ispitnu statistiku postavlja se tako
da se vjerojatnost identifikacije
modificiranog bloka kao nemodificiranog svede na
![]()
Blok ![]() označava se kao potencijalno manipuliran
ukoliko
označava se kao potencijalno manipuliran
ukoliko ![]() ,
ali ovoj su odluci pridonosili samo
središnji pixeli bloka. Kroz ovaj proces
analiziranja slike veličine
,
ali ovoj su odluci pridonosili samo
središnji pixeli bloka. Kroz ovaj proces
analiziranja slike veličine ![]() ,
dobivamo binarni niz koji potencijalno modificirane pixele označava
postavljanjem jedinice na točnu indeksnu
lokaciju niza.
,
dobivamo binarni niz koji potencijalno modificirane pixele označava
postavljanjem jedinice na točnu indeksnu
lokaciju niza.
Veličinom bloka određuje se preciznost kojom algoritam može utvrditi oblik modificirane regije, kao i veličinu minimalne modificirane regije koju se uzima u obzir. Iz niza se miču sve povezane regije označene kao modificirane koje sadrže manje pixela od definirane veličine bloka. Finalna mapa krivotvorenih regija dobiva se dilatacijom niza sa kvadratnom jezgrom veličine 20x20, s ciljem kompenzacije činjenice da se odluka o čitavom bloku donosi na temelju njegovog centralnog pixela, time se može preskočiti dijelove granica modificiranih regija.
Kako je dimenzionalnost identifikacijskog otiska jednaka broju pixela, otisak je jedinstven za svaku kameru, i vjerojatnost da više kamera posjeduje isti ili veoma sličan otisak je mala. Identifikacijski je otisak stabilan tijekom vremena. Sve ove osobine čine ga izvrsnom veličinom pogodnom za provjeru mnogih forenzičkih zadataka kao što je identifikacija kamere, povezivanje uređaja, ili pronalazak modificiranih regija.
5.3
Otkrivanje
krivotvorina digitalnih slika
Živimo u dobu u
kojem smo svakodnevno izloženi velikom broju vizualnih podražaja. Prije utjecaja
i infiltracije digitalnih informacija u svaki kutak naše svakodnevnice, ljudi su vjerovali integritetu tih vizualnih
slika. Počevši od tabloida, modnih časopisa, modne industrije, medija,
znanstvenih časopisa, političkih kampanja, sudnica, do fotografskih prijevara
koje dobivamo elektroničkom poštom, obrađene fotografije pojavljuju se s
rastućom učestalosti i kvalitetom. U proteklih je nekoliko godina digitalna
forenzika svojim algoritmima i metodama
analize uspjela vratiti dio povjerenja u digitalne slike i fotografije.
Uzimajući u obzir
povećanu sofisticiranost grafički generiranih
slika, postaje sve teže razlikovati slike vizualnom metodom.
U današnje se vrijeme
veoma lako može manipulirati slikama.
Dostupnošću jakih računala i visoko kvalitetnih digitalnih fotoaparata i
kamera, te sofisticiranog softvera za
obradu fotografija, s lakoćom se stvaraju uvjerljive krivotvorine. Dok je digitalni vodeni žig jedan od načina dokazivanja
autentičnosti slike, on je limitiran na specijalno opremljene digitalne
fotoaparate, stoga su potrebne općenite metode otkrivanja krivotvorina. Pasivne
metode nazivaju se one koje djeluju i bez prisutstva bilo kakvog potpisa ili
vodenog žiga, te se zasnivaju na činjenici da iako metode digitalnog
krivotvorenja možda ne ostavlja vizualne
dokaze koji bi načinili neke
vidljive promjene na slici one mogu
promijeniti njene statističke koeficijente. Skup algoritama za digitalnu
forenziku slika može se podijeliti na pet kategorija [1]:
1.
Algoritmi
zasnovani na pixelima koje otkrivaju statističke anomalije na razini
pixela.
2.
Algoritmi koje
rade na temelju korelacija uvedenih
specifičnim shemama kompresije s gubitcima.
3.
Algoritmi zasnovani na fotoaparatima ili kamerama koje
iskorištavaju smetnje nastale foto lećama, senzorima, ili on-chip postprocesiranjem .
4.
Fizikalno zasnovani algoritmi koji eksplicitno
modeliraju i otkrivaju anomalije u tridomenzionalnoj interakciji fizičkih objekata , svjetla i kamere.
5.
Algoritmi
zasnovani na geometriji koje bilježe mjerenja objekata u prostoru i
njihovu poziciju s obzirom na kameru.
5.3.1
Algoritmi
zasnovani na pixelima
Pravosudni se sustav često pouzdaje na spektar forenzičkih analiza; od identifikacije otiscima prstiju, ili utvrđivanjem DNA, do forenzičke ortodontije, entimologije, geologije... U tradicionalnim se forenzičkim znanostima analizira širok spektar fizičkih dokaza, dok se u digitalnoj forenzici analiziraju bitovi i pixeli. Pixel je građevni blok digitalne slike. U nastavku su opisane četiri metode detekcije raznih vrsta manipulacija slikama, od kojih svaka, izravno ili neizravno analizira korelacije na razini pixela [1].
Kloniranje
Jedno od najčešćih oblika manipulacije digitalnih slika jest kopiranje ili (eng. cloning) dijela slike kako bi se tim dijelom prikrila neka osoba, ili objekt na fotografiji. Kada se ovo prikrivanje izvede pažljivo, može biti veoma teško, možda i nemoguće otkriti kloniranje vizualnom inspekcijom. Kako klonirani predio slike može biti bilo koje veličine,oblika i lokacije, računalno je nemoguće pretražiti sve lokacije na slici. Razvijena su dva računalno efikasna algoritma koji otkrivaju klonirane slike.
U prvom se pristupu primjenjuje diskretna kosinusna transformacija (eng. Discrete cosine transform, kratica DCT ) na razini blokova. Duplicirane se regije slike otkrivaju leksikografskim sortiranjem DTC koeficijenata blokova, te se blokovi s istim prostornim ofset koeficijentom grupiraju. U sličnom pristupu autori [6] razvili su algoritam naziva copy-moove. U ovom se algoritmu primjenjuje Analiza glavnih komponenti (eng. Principal Component analisys, kratica PCA) na malene blokove fiksne veličine, kako bi se dobila reprezentacija slike smanjenih dimenzija. Duplicirane se regije također pronalaze leksikografskim sortiranjem i grupiranjem svih preostalih blokova slike. Više će o ovom algoritmu biti riječi u poglavlju 6.
Oba algoritma koriste metode reduciranja računalne kompleksnosti smanjenjem dimenzionalnosti slike (DTC i PCA), te kako bi se osigurala robusnost na male varijacije u slikama nastale zbog šuma ili kompresije sa gubitcima.
Preuzrokovanje
Kako bi se stvorila uvjerljiva kompozitna slika često je
potrebno promijeniti veličinu, rotirati ili rastegnuti dijelove slike. Na primjer,
kada se stvara kompozitna slika dviju osoba, dio slike koji sadrži jednu od
osoba ponekad je potrebno prilagoditi veličinom, kako bi odgovarala relativnoj
veličini osobe s druge fotografije. Ovaj proces zahtjeva preuzrokovanje (eng. Resampling) originalne slike na novi
oblik, s uvođenjem specifičnih
periodičkih korelacije među susjednim pixelima. Kako se te korelacije općenito
ne događaju prirodno, njihova se prisutnost može koristiti za otkrivanje manipulacije preuzrokovanjem. Na primjer,
uzmimo jednodimezionalni signal ![]() ,
duljine
,
duljine ![]() ,
i poboljšamo uzrokovanje za faktor dva koristeći linearnu interpolaciju kako bi
dobili
,
i poboljšamo uzrokovanje za faktor dva koristeći linearnu interpolaciju kako bi
dobili ![]() .
Linearna interpolacija jedna je od najjednostavnijih oblika interpolacija, a
zapravo se svodi na izračun aritmetičke sredine iz vrijednosti dviju susjednih
točaka kako bi se odredila točka
smještena točno na sredini njihove udaljenosti. Neparni uzorci novog signala
.
Linearna interpolacija jedna je od najjednostavnijih oblika interpolacija, a
zapravo se svodi na izračun aritmetičke sredine iz vrijednosti dviju susjednih
točaka kako bi se odredila točka
smještena točno na sredini njihove udaljenosti. Neparni uzorci novog signala ![]() poprimaju vrijednosti originalnog signala :
poprimaju vrijednosti originalnog signala :
![]()
dok parni uzorci, dobiveni linearnom interpolacijom, poprimaju prosječnu vrijednost sljedećeg susjeda u originalnom signalu:
![]()
Kako se svaki uzorak originalnog signala može pronaći u preuzrokovanom signalu, interpolirani pixeli mogu se izraziti i samo pomoću preuzrokovanih uzoraka:
![]()
Kroz cijeli preuzrokovani signal svaki je parni uzorak identičan linearnoj kombinaciji prethodnog i sljedećeg susjeda. U ovom jednostavnom slučaju, preuzrokovani signal može se otkriti provjerom jeli svaki drugi uzorak savršeno koreliran sa svojim susjedom. Ovaj tip korelacije nije limitiran samo na poboljšano uzrokovanje s faktorom dva. Širok spektar preuzrokovanja uzrokuje slične periodičke korelacije. Kada bi istražitelj znao koji se tip preuzrokovanja koristio, bilo bi jednostavno odrediti koji su pixeli korelirani sa svojim susjedima, jer bi znali i tip korelacije koja se događa prilikom tog tipa modifikacije. No u praksi se najčešće ne zna ni tip korelacije, ni tip provedenog preuzrokovanja. Algoritam očekivanja i maksimizacije (eng. Expectatiom/maximization, kratica EM), koristi se za simultano rješavanje oba problema. EM algoritam iterativna je dvokoračna metoda:
1. U
koraku očekivanja, procjenjuje se vjerojatnost korelacije svakog pixela sa
svojim susjednim pixelima.
2. U
koraku maksimizacije procjenjuje se specifičan oblik korelacije.
Ako pretpostavimo linearnu metodu interpolacije, korak očekivanja svodi se na Bayesovu funkciju vjerojatnosti, a korak maksimizacije na procjenu najmanjih kvadrata s težinskim faktorima (eng. Weighted least-squares estimation). Procijenjena se vjerojatnost koristi za klasifikaciju dijela slike kao modificiranog ili ne.
Spajanje
Čest oblik fotografske manipulacije je digitalno spajanje
(eng. Splicing) dvaju ili više slika
u jednu kompoziciju. Kada se provodi pažljivo, rubovi među spojenim regijama
mogu biti vizualno neprimjetne. Spajanje remeti Fourierove statistike višeg
reda i ta se činjenica može upotrijebiti
za otkrivanje ovog tipa manipulacije. Na primjer, uzmemo jednodimenzionalan
signal ![]() i njegovu Fourierovu transformaciju
i njegovu Fourierovu transformaciju ![]() . Fourierova transformacija drugog reda naziva se funkcija autokorelacije,
odnosno spektar snage
. Fourierova transformacija drugog reda naziva se funkcija autokorelacije,
odnosno spektar snage
![]()
rutinski se koristi za analizu frekvencijske kompozicije signala. Fourierova transformacija trećeg reda naziva se funkcija generiranja ili bispektar (eng. bispectrum), odnosno bispektralna gustoća. Bispektar možemo izraziti kao :
![]()
A njime se mjere
korelacije višeg reda među trojkama frekvencija ![]() ,
,
![]() i
i ![]() .
Suptilne nekonzistentnosti koje se događaju zbog spajanja manifestiraju se s
povećanom magnitudom bispektra.
.
Suptilne nekonzistentnosti koje se događaju zbog spajanja manifestiraju se s
povećanom magnitudom bispektra.
Statističke
Postoji 256n
mogućih osam bitnih gray-scale
slika veličine ![]() pixela. Čak i s malim brojem kao što je
pixela. Čak i s malim brojem kao što je ![]() ,
postoji
,
postoji ![]() mogućih slika što više od procijenjenog broja
atoma u svemiru.
mogućih slika što više od procijenjenog broja
atoma u svemiru.
Kada bi nasumce odabrali jednu od tih mogućih slika, malo je vjerojatno kako bi iz tog mnoštva mogućnosti izvukli neku smislenu sliku.Ovaj zaključak sugerira da fotografije sadrže specifične statističke osobine. Kao oblik prikupljanja statističkih osobina slika najčešće se koristi wavelet dekompozicija. Ova dekompozicija dijeli frekvencijski prostor na višestruke skale i orijentacijske potprstore (eng. subbands). Statistički se model sastoji od prvih četiri statističkih trenutaka svakog wavelet potpojasa i statistika višeg reda koje bilježe korelacije među potpojasevima. Za klasifikaciju slika koriste se metode nadgledane klasifikacije uzoraka, koje se klasificiranju na temelju svojih statističkih osobina. Sličan pristup provodi se konstrukcijom statističkog modela koji se temelji na lokalnoj co-occurence metodi; statističkom obliku bit ravnina (engl. Bit planes) slika. Računaju se prva četiri statistička momenta iz frekvencije bit slaganja i neslaganja kroz bit ravnine. Iz tih se mjerenja izvlači devet osobina koje predstavljaju sličnosti binarnog niza. Ovaj se sekvencionalni algoritam s pretragom unaprijed koristi za odabir najdeskriptivnijih osobina, koje se koriste u klasifikatoru s linearnom regresijom kako bi se utvrdile koje su slike manipulirane a koje nisu. U oba se slučaja statistički model koristi za otkrivanje raznih vrsta manipulacije; od promijene veličine i filtriranja, pa sve do otkrivanja skrivenih poruka u slici (steganografija), ili razlikovanja fotorealističnih slika od fotografija.
5.3.2
Algoritmi
zasnovani na formatu
Prvo pravilo svih forenzičkih analiza glasi: očuvati dokaze. Uzimajući ovo u obzir, sheme kompresije s gubitcima (eng. Lossy compression) kao što je JPEG, mogle bi se smatrati najgori neprijatelji forenzičkog analitičara. Stoga je ironično kako se jedinstvena svojstva kompresije s gubitcima može iskoristiti prilikom forenzičke analize. U nastavku su opisane tri metode kojima je moguće otkriti malverzacije u JPEG komprimiranim slikama [1].
5.3.2.1
JPEG
Kvantizacija
Većina fotoaparata kodiraju slike u JPEG formatu. Ova shema
komprimiranja s gubitcima omogućava fleksibilnost u određivanju stupnja
kompresije. Proizvođači tipično postavljaju postavke kako bi dobili što bolji
omjer kompresije i kvalitete specifično
za svoj proizvod. Ova se razlika može koristiti za identifikaciju izvora slike, tj.modela i proizvođača fotoaparata. Ako imamo
trokanalnu sliku u boji (eng. Red, Blue,
Green, kratica RBG), standardan postupak JPEG kompresije teče ovako; RGB
slika prebaci se u luminance/chrominance
prostor (kratica YCbCr) boja. Ljudski
je vid znatno osjetljiviji na varijacije u svjetlosti nego
na varijacije u intenzitetu boja, stoga se veća širina pojasa (engl. bandwidth) dodjeljuje
komponenti luminancije ![]() .
Komponentedva kanala boja razlike
crvene
.
Komponentedva kanala boja razlike
crvene ![]() ,
i plave
,
i plave ![]() obično se sužavaju za faktor dva u odnosu na komponentu
obično se sužavaju za faktor dva u odnosu na komponentu ![]() .
Svaki kanal particionira se u blokove veličine 8x8 pixela. Te se
vrijednosti prebace iz cijelih brojeve
bez predznaka (eng. Unsigned integer)
u cijeli broj s predznakom (eng. Signed
integer). Svaki se blok prebacuje u frekvencijski prostor korištenjem
dvodimenzionalne diskretne kosinusne
pretvorbe (DCT). Ovisno o specifičnoj frekvenciji i kanala, svaki se DCT
koeficijent
.
Svaki kanal particionira se u blokove veličine 8x8 pixela. Te se
vrijednosti prebace iz cijelih brojeve
bez predznaka (eng. Unsigned integer)
u cijeli broj s predznakom (eng. Signed
integer). Svaki se blok prebacuje u frekvencijski prostor korištenjem
dvodimenzionalne diskretne kosinusne
pretvorbe (DCT). Ovisno o specifičnoj frekvenciji i kanala, svaki se DCT
koeficijent ![]() kvantificira
za vrijednost
kvantificira
za vrijednost ![]() ;
;
![]()
Ovaj je korak primarni razlog kompresije. Puna se kvantizacija specificira kao tablica koja sadrži 192 vrijednosti, skupinu od 8x8 vrijednosti asociranih s svakom frekvencijom, za svaki od tri kanala. Za manje vrijednosti kompresije te vrijednosti teže ka 1, dok kod viših vrijednosti rastu. Ovaj se niz koraka s manjim varijacijama provodi u digitalnim kamerama od strane njihovih JPEG enkodera. Enkoderi se najčešće razlikuju po kvantizacijskim tablicama, te time ugrađuju potpis u svaku sliku. Kvantizacijske se tablice mogu izvući iz enkodirane JPEG slike ili otprilike procijeniti iz slike. Treba uzeti u obzir da kvantizacijske tablice mogu varirati i unutar jednog fotoaparata, ovisno o postavkama kvalitete, te kako dolazi do određenog stupnja preklapanja kvantizacijskih tablica fotoaparata različitih modela i proizvođača. Bez obzira na nedostatke, ova se metoda može primijeniti za osnovnu identifikaciju izvora slike.
Dupli JPEG
Svaka digitalna manipulacija zahtijeva, u najmanju ruku, otvaranje slike u programu za obradu slika, te ponovno spremanje nakon obrade. Kako se većina slika čuva u JPEG formatu, vjerojatno je kako će originalna slika kao i manipulirana biti sačuvane u tom formatu. Manipulirana se slika u ovoj situaciji dva puta komprimira. Zbog obilježja kompresije s gubitcima JPEG formata, ovo duplo komprimiranje (eng. Double JPEG) uvodi specifične objekte koji ne postoje u jednostruko komprimiranim slikama, ako pretpostavimo kako slika nije djelomice odrezana (eng. cropped)prije druge kompresije. Prisutnost tih objekata (eng. artifacts) može dakle koristiti kao dokaz određene vrste manipulacije. Iako se mora uzeti u obzir kako dvostruka JPEG kompresija ne mora nužno značiti maliciozno mijenjanje slike. Na primjer, moguće je nenamjerno sačuvati sliku nakon njenog pregleda. Kao što je opisano u prethodnom poglavlju, kvantizacija DTC koeficijenata primarni je način postizanja kompresije. Dekvantizacija vraća kvantizacijske vrijednosti u njihovo originalne vrijednosti. No treba uzeti u obzir kako kvantizacija nije invertibilna, isto tako dekvantizacija nije inverzna funkcija kvantizacije. Dvostruka se kvantizacija može opisati formulom
![]()
i nizom od tri koraka:
1. Kvantizacija
s korakom ![]()
2. Dekvantizacija
s korakom ![]()
3. Kvantizacija
korakom ![]()
Kao primjer možemo uzeti skup koeficijenata normalne razdiobe u rasponu od [0,127]. Za ilustraciju objekata dvostruke kvantizacije, u obzir se uzimaju četiri različite kvantizacije tih koeficijenata. U slučaju dvostruke kvantizacije može se otkriti periodičnost objekata, i ta se periodičnost koristi za otkrivanje dvostruke JPEG kompresije.
Blokovni JPEG
Osnovu JPEG kompresije, kao što je već navedeno, postiže se DTC transformacijom blokova. Svaki blok slike veličine 8x8 pixela individualno se transformira i kvantizira, objekti se pojavljuju na granicama sa susjednim blokovima u obliku horizontalnih i vertikalnih rubova. Kada se manipulira slikom, ti se objekti blokova mijenjaju ili gube. Objekti blokova mogu se opisati koristeći razlike vrijednosti pixela unutar i preko granica bloka. Ove se razlike smanjuju unutar blokova, a povećavaju van blokova. Kada se na primjer odreže dio slike, te ponovo komprimira, stvaraju se novi artefakti blokova koji se nužno ne poravnavaju s originalnim granicama. Razlike unutar bloka te van bloka računaju se za susjedstvo od četiri pixela koja su međusobno udaljena za fiksnu određenu vrijednost. Jedno se susjedstvo u cijelosti nalazi unutar JPEG bloka, dok se drugome susjedstvu granice preklapaju s JPEG blokom. Tada se računa histogram tih razlika za sve nepreklapajuće blokove veličine 8x8 pixela. Kao prosječnu vrijednost među tim histogramima, računa se matrica artefakata blokova (eng. blocking artefact matrix, kratica BAM). Kod nekomprimiranih slika ova matrica sastoji se od slučajnih vrijednosti, dok kod komprimiranih poprima specifične uzorke. Kada se slici odreže dio, te ponovo komprimira ovi se uzorci poremete. Korištenjem nadgledanog raspoznavanja uzoraka, moguće je klasificirati autentične i neautentične BAM matrice.
Lokalizirane je manipulacije moguće otkriti traženjem
nekonzistentnosti u artefaktima blokova. Za regiju slike za koju se
pretpostavlja kako je autentična, procjenjuje se razina kvantizacije za svaku
od 64 DCT frekvencije. Nekonzistencije između DCT koeficijenata ![]() i procijenjene količine kvantizacije
i procijenjene količine kvantizacije ![]() računaju se prema formuli
računaju se prema formuli
![]()
Varijacije u ![]() kroz sliku koriste se za otkrivanje
manipuliranih regija.
kroz sliku koriste se za otkrivanje
manipuliranih regija.
5.3.3
Algoritmi
zasnovani na fotoaparatima
Metalne linije u cijevima pištolja unose vrtnju u kretanje ispaljenog projektila, te time pridonose njegovom dometu i preciznosti gađanja. Te linije ostavljaju jedinstvene oznake na metku prilikom njegova izlaza iz cijevi, i stoga se mogu koristiti prilikom utvrđivanja veze pištolja i ispaljenog metka. Koristeći isti princip, razvijeno je nekoliko forenzički metoda koje modeliraju specifične artefakte do kojih se dolazi u raznim koracima procesiranja slika. U nastavku su opisane četiri metode za modeliranje i procjenu raznih artefakata kamera. Nekonzistentnosti u tim artefaktima koristi se kao dokaz da je slika manipulirana [1].
Kromatska aberacija
U idealnom fotografskom sustavu, svijetlo prolazi kroz leću i fokusira se na jedno mjesto na senzoru. Optički sustavi u realnosti odstupaju od idealnih modela, time da ne uspijevaju savršeno fokusirati svijetlo svih valnih duljina. Preciznije, lateralna kromatska aberacija (eng. Chromatic aberration) manifestira se kao prostorni pomak u lokacijama gdje svijetlo različitih valnih duljina dostižu do senzora. Lateralnu se aberaciju može predvidjeti proširenjem ili sakupljanjem kanala boja u odnosu jedni na druge.
U klasičnoj se optici refrakcije svijetla na granici dva medija opisuje Snellovim zakonom loma svijetlosti:
![]()
gdje je ![]() kut
prijeloma,
kut
prijeloma, ![]() je kut upada, a
je kut upada, a ![]() i
i ![]() su bezdimenzijske konstante , indeksi loma
dvaju sredstava. Refraktivni indeks loma stakla nf ovisi o
valnim duljinama svjetla koje prolazi kroz njega. Ova je ovisnost rezultat rastava
polikromatskog svijetla po valnim duljinama prilikom izlaza leće i dolaska do
senzora. Polikoromatsko svijetlo dolazi do leće pod kutem
su bezdimenzijske konstante , indeksi loma
dvaju sredstava. Refraktivni indeks loma stakla nf ovisi o
valnim duljinama svjetla koje prolazi kroz njega. Ova je ovisnost rezultat rastava
polikromatskog svijetla po valnim duljinama prilikom izlaza leće i dolaska do
senzora. Polikoromatsko svijetlo dolazi do leće pod kutem ![]() ,
a izlazi pod kutom koji ovisi o valnoj duljini. Kao rezultat ove činjenice,
dvije zrake različitih valnih duljina iako ulaze pod istim kutom, lomiti će se
pod različitima.Tako nastaje kromatska aberacija. Kako je aberacija rezultat
pomaka među kanalima boje, pokušava se maksimizirati poklapanje kanala boja. Na
primjer zajedničke se informacije između crvenog i zelenog kanala boja maksimiziraju a
sličnom se procjenom pronalazi i
distorzija među kanalima boja). Lokalne se procjene kromatske aberacije
uspoređuju s procjenama globalne aberacije kako bi se otkrila manipulacija.
,
a izlazi pod kutom koji ovisi o valnoj duljini. Kao rezultat ove činjenice,
dvije zrake različitih valnih duljina iako ulaze pod istim kutom, lomiti će se
pod različitima.Tako nastaje kromatska aberacija. Kako je aberacija rezultat
pomaka među kanalima boje, pokušava se maksimizirati poklapanje kanala boja. Na
primjer zajedničke se informacije između crvenog i zelenog kanala boja maksimiziraju a
sličnom se procjenom pronalazi i
distorzija među kanalima boja). Lokalne se procjene kromatske aberacije
uspoređuju s procjenama globalne aberacije kako bi se otkrila manipulacija.
Mreža filtera boja
Digitalna slika u boji sastoji se od tri kanala koji sadrže uzorke različitih područja spektra boje, npr crven, zelen, plavi. Većina digitalnih fotoaparata opremljeni su s jednim CCD ili CMOS senzorom te slikaju slike u boji koristeći mrežu filtera boje(eng. Color filter aray). Većina CFA filtera koriste trobojne filtere (crven, zelen, plavi) poredane iznad svakog senzorskog elementa. Kako se snima samo jednobojni uzorak za svaku pixelsku lokaciju, druga se dva uzorka boja moraju procijeniti iz susjednih pixela kako bi se dobilo trokanalnu sliku u boji. Procjena nedostajućih uzoraka boja naziva se CFA interpolacija (eng. demozaicking). Najjednostavnije metode CFA interpolacije zasnivaju se na jezgrama, i djeluju na svaki kanal neovisno. Sofisticiraniji algoritmi interpoliraju rubove različito od uniformnih dijelova slike kako bi se izbjeglo zamućivanje slike. Bez obzira na implementaciju, CFA interpolacija uvodi specifične statističke korelacije u podskupovima pixela u svakom kanalu boje. Kako se filtri za boju u CFA obično postavljaju u periodičke oblike i korelacije su periodičke. U isto je vrijeme malo vjerojatno kako će uslikani pixeli biti periodički korelirani sami od sebe, zbog toga se korelacije mogu koristiti kao tip digitalnog potpisa. Ukoliko je poznat specifičan oblik periodičke korelacije jednostavno se određuje koji su pixeli korelirani sa svojim susjedima, vrijedi i obrnuta situacija. U praksi se prilikom istrage najčešće ne zna niti jedna od tih informacija. Metoda utvrđivanja oblika periodičke korelacije i koreliranih pixela provodi se EM algoritmom. EM algoritam sastoji se od dva osnovna koraka koja se iteriraju: utvrditi vjerojatnost korelacije sa susjedima za svaki pixel, procijeniti opći oblik korelacije među pixelima. Modeliranjem CFA korelacija jednostavnim linearnim modelom, korak očekivanja svodi se na Bayesovu funkciju vjerojatnosti, a korak maksimizacije na procjenu korištenjem težinske funkcije najmanjih kvadrata. U autentičnim se slikama očekuje kako će periodički uzorak pixela biti veoma koreliran sa susjednim, te svaka devijacija može ukazivati na manipulacije slika.
Odgovor kamere
Većina senzora u digitalnim kamerama gotovo je linearno,
stoga se očekuje linearna veza između količine svjetla izmjerenog svakim elementom senzora i pripadajuće
konačne vrijednosti pixela no kamere koriste metodu nelinearnosti u točkama
(eng. Pointwise nonlinearity) kako
bi se poboljšala svojstva finalne slike
. Uzmimo na primjer rub kod kojeg su pixeli ispod granice konstantne boje ![]() ,
a pixeli iznad granice drugačije boje
,
a pixeli iznad granice drugačije boje ![]() .
Ako je odgovor kamere linearan, tada bi pixeli na granici trebali biti linearna kombinacija susjednih boja. Devijacija u vrijednostima tih međugraničnih
pixela od tih očekivanih linearnih
odgovora koristi se za predviđanje funkcije odgovora kamere. Inverzna funkcija
odgovora kamere koja vraća boje pixela natrag u linearan odnos predviđa se korištenjem maximum a posteriori
algoritma za predviđanje (kratica MAP). Kako bi se stabilizirao algoritam za
predviđanje, odabiru se takve granice da
su područja koja dijele veoma slična, varijance su veoma male na obije strane,
razlike među
.
Ako je odgovor kamere linearan, tada bi pixeli na granici trebali biti linearna kombinacija susjednih boja. Devijacija u vrijednostima tih međugraničnih
pixela od tih očekivanih linearnih
odgovora koristi se za predviđanje funkcije odgovora kamere. Inverzna funkcija
odgovora kamere koja vraća boje pixela natrag u linearan odnos predviđa se korištenjem maximum a posteriori
algoritma za predviđanje (kratica MAP). Kako bi se stabilizirao algoritam za
predviđanje, odabiru se takve granice da
su područja koja dijele veoma slična, varijance su veoma male na obije strane,
razlike među ![]() i
i ![]() su konstantne. Uvode se i ograničenja na
procijenjenu funkciju odgovora kamere (eng. Camera
response).Ona bi se trebala monotono
povećavati s najmanje jednom točkom infleksije, i trebala bi biti slična za sve
kanale boje. Kako se funkcija odgovora kamere može procijeniti lokano, značajne
varijacije ove funkcije kroz cijelu sliku mogu ukazivati na modificiranje
slike.
su konstantne. Uvode se i ograničenja na
procijenjenu funkciju odgovora kamere (eng. Camera
response).Ona bi se trebala monotono
povećavati s najmanje jednom točkom infleksije, i trebala bi biti slična za sve
kanale boje. Kako se funkcija odgovora kamere može procijeniti lokano, značajne
varijacije ove funkcije kroz cijelu sliku mogu ukazivati na modificiranje
slike.
Šum senzora
Kako se digitalna slika premješta od senzora kamere do računalne memorije, polazi seriju koraka procesiranja uključujući kvantizaciju, korekciju boja, gama korekcije, filtriranje,balansiranje bijelog šuma, demosaicing, te najčešće JPEG kompresiju. Ovo procesiranje unosi prepoznatljiv potpis na sliku. Moguće je modelirati procesiranje s aditivnim multiplikativnim modelom šuma. Parametri modela šuma procjenjuju se iz serije slika koje dolaze s poznate kamere ili iz istraživane kamere. Korelacije između predviđenog šuma kamere (eng. Sensor noise) i šuma izvučenog iz slika koriste se za autentifikaciju slike. Efekti procesiranja slike unutar kamere konstruirano je kao:
![]()
Gdje ![]() predstavlja sliku bez šuma,
predstavlja sliku bez šuma,![]() je multiplikativna konstanta,
je multiplikativna konstanta, ![]() predstavlja multiplikativni šum koji se još
naziva i neuniformni šum foto odgovora (eng. Photoresponse nonuniformity noise, kratica PRNU), a
predstavlja multiplikativni šum koji se još
naziva i neuniformni šum foto odgovora (eng. Photoresponse nonuniformity noise, kratica PRNU), a ![]() je izraz za additive šum. Kako PRNU varira kroz sliku, može se koristiti za
otkrivanje lokalnih ili globalnih nedosljednosti u slici. PRNU se procjenjuje iz niza
autentičnih slika koristeći metode
otklanjanja šuma zasnovane na wavelet statistikama.
Općenito, potrebo je barem pedeset slika za dobivanje točne PRNU procjene. Autentifikacija se provodi kroz blokovsku korelaciju između procijenjenih PRNU i slika čija je
autentičnost dovedena u pitanje. Pomoću PRNU-a moguće je odrediti i specifičan
model kamere.
je izraz za additive šum. Kako PRNU varira kroz sliku, može se koristiti za
otkrivanje lokalnih ili globalnih nedosljednosti u slici. PRNU se procjenjuje iz niza
autentičnih slika koristeći metode
otklanjanja šuma zasnovane na wavelet statistikama.
Općenito, potrebo je barem pedeset slika za dobivanje točne PRNU procjene. Autentifikacija se provodi kroz blokovsku korelaciju između procijenjenih PRNU i slika čija je
autentičnost dovedena u pitanje. Pomoću PRNU-a moguće je odrediti i specifičan
model kamere.
5.3.4
Algoritmi
zasnovani na fizici
Uzmimo za primjer krivotvorenu sliku koja prikazuje dvije filmske zvijezde koje su navodno u vezi kako šeću plažom gledajući zalazak sunca. Takva se slika može složiti spajanjem individualnih slika svake od zvijezda. Prilikom takve manipulacije, teško je točno pogoditi efekte svijetlosti pod kakvim je svaka od osoba bila originalno slikana. U nastavku su opisane tri metode koje omogućuju predviđanje različitih svojstava svjetlosnog okruženja pod kojima je osoba ili objekt fotografiran. Razlike u osvjetljenju na slici mogu se koristiti kao dokazi manipulacije slikom [1].
Smjer svjetla 2D
Ako je desna strana nekog objekta ili osobe na slici jače osvijetljena od lijeve strane, možemo zaključiti kako se izvor svjetlosti nalazi na desnoj strani. Ovo se opažanje može formalizirati ako pretpostavimo kako je količina svijetla koja dolazi do površine proporcionalna normali površine i smjera svjetlosti (eng. Light direction). S poznavanjem normala trodimenzionalnog prostora, smjer izvora svjetlosti lako se pretpostavlja, no kako se normale ne mogu odrediti samo iz jedne slike, za određivanje smjera izvora svjetlosti koriste se dvodimenzionalne normale površine na granici objekta, a procjenjuju se dvije od tri komponente smjera izvora svjetlosti. Kako bi se procjena pojednostavila, pretpostavlja se kako je ispitivana površina Lambertinska (tj površina reflektira svjetlo izotropno), posjeduje konstantne refleksijske vrijednosti, i osvjetljava ju beskonačno udaljen točkasti izvor svijetlosti. Pod tim pretpostavkama može se izraziti intenzitet slike kao:
![]()
gdje ![]() predstavlja konstantu refleksijske vrijednosti,
predstavlja konstantu refleksijske vrijednosti,
![]() je vektor koji je usmjeren prema izvoru
svjetlosti,
je vektor koji je usmjeren prema izvoru
svjetlosti, ![]() vektor koji predstavlja normale površine u
točci
vektor koji predstavlja normale površine u
točci ![]() i
i ![]() je konstanta
ambient light. Kako nas zanima
samo smjer izvora svjetlosti, refleksijski izraz
je konstanta
ambient light. Kako nas zanima
samo smjer izvora svjetlosti, refleksijski izraz ![]() može poprimiti jediničnu vrijednost. Na
površinskoj granici,
može poprimiti jediničnu vrijednost. Na
površinskoj granici, ![]() prostorna komponenta površinske normale jest
nula, a
prostorna komponenta površinske normale jest
nula, a ![]() i
i ![]() komponente površinskih normala mogu se odrediti izravno sa slike. Sada
intenzitet slike možemo izraziti sa:
komponente površinskih normala mogu se odrediti izravno sa slike. Sada
intenzitet slike možemo izraziti sa:
![]()
![]() komponentu površinskih normala kao i smjer
svjetlosti ignorira se jer
komponentu površinskih normala kao i smjer
svjetlosti ignorira se jer ![]() .
S najmanje tri točke iste refleksije
.
S najmanje tri točke iste refleksije ![]() i
različitih površinskih normala
i
različitih površinskih normala ![]() ,
smjer izvora svjetlosti može se dobiti
standardnom procjenom najmanjih kvadrata. Kvadratna funkcija pogreške minimizira se korištenjem standardne procjene
najmanjih kvadrata kako bi se dobio vektor
,
smjer izvora svjetlosti može se dobiti
standardnom procjenom najmanjih kvadrata. Kvadratna funkcija pogreške minimizira se korištenjem standardne procjene
najmanjih kvadrata kako bi se dobio vektor
![]()
Ovaj se proces ponavlja za ostale objekte ili osobe na slici kako bi se provjerila konzistentnost osvjetljenja.
Smjer svjetlosti (3D)
Procjena smjera izvora svijetlosti u prethodno je opisanoj metodi bilo ograničeno na dvodimenzionalna prostor zbog činjenice da je veoma teško odrediti normale trodimenzionalne površine iz jedne slike. Postoji način određivanja smjera izvora svjetlosti pomoću refleksije svjetlosti s objekata kao što su ljudsko oko ili neke druge refleksivne površine. Tražene se normale trodimenzionalnog prostora određuju uporabom trodimenzionalnog modela oka.
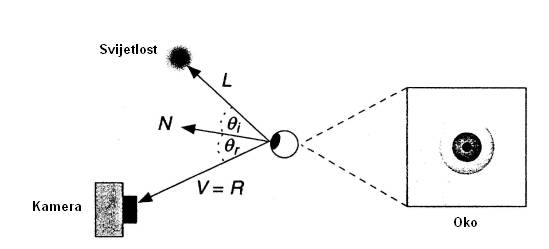
Slika 5.3 Formacija točkastog posvjetljenja tj odbljeska na oku.
Na ovom dijagramu tri
vektora ![]() pripadaju smjeru svjetlosti, površinskom
normalu u točki na kojoj nastaje posvjetljenje,odbljesak, i smjeru u kojem će
se odbljesak vidjeti. Njegova je
pozicija određena normalom površine
pripadaju smjeru svjetlosti, površinskom
normalu u točki na kojoj nastaje posvjetljenje,odbljesak, i smjeru u kojem će
se odbljesak vidjeti. Njegova je
pozicija određena normalom površine ![]() ,
i relativnih položaja izvora svjetlosti
,
i relativnih položaja izvora svjetlosti ![]() i gledaoca
i gledaoca ![]() .
Pravilo refleksije tvrdi kako se zraka
svjetlosti reflektira od površine pod kutom refrakcije
.
Pravilo refleksije tvrdi kako se zraka
svjetlosti reflektira od površine pod kutom refrakcije ![]() ,
jednak kutu odbijanja
,
jednak kutu odbijanja ![]() . Ti se
kutovi mjere s obzirom na površinsku normalu
. Ti se
kutovi mjere s obzirom na površinsku normalu ![]() .
Ako pretpostavimo jediničnu duljinu vektora, smjer reflektirane zrake
.
Ako pretpostavimo jediničnu duljinu vektora, smjer reflektirane zrake ![]() može se opisati pomoću izraza za smjer svjetlosti
može se opisati pomoću izraza za smjer svjetlosti ![]() i površinsku normalu
i površinsku normalu ![]() .
.
![]()
Ako pretpostavimo savršenu refleksiju![]() gornji se izraz može svesti na
gornji se izraz može svesti na
![]()
Smjer svjetlosti ![]() ,
može stoga biti procijenjen iz površinske
normale
,
može stoga biti procijenjen iz površinske
normale ![]() i smjera pogleda
i smjera pogleda ![]() prilikom posvjetljenja. Ovaj procijenjeni smjer
svjetlosti može se usporediti za nekoliko osoba na slici, ili prije opisanom
metodom ograničenom na dvodimenzionalni prostor.
prilikom posvjetljenja. Ovaj procijenjeni smjer
svjetlosti može se usporediti za nekoliko osoba na slici, ili prije opisanom
metodom ograničenom na dvodimenzionalni prostor.
Okruženje svjetlosti
U prethodne se dvije metode promatrao pojednostavljen model osvjetljenja sa samo jednim udaljenim točkastim izvorom. U stvarnosti osvjetljenje scene može biti kompleksno: neznana količina svjetala s raznih lokacija može osvjetljavati fotografirani prostor, stvarajući pritom različita okruženja osvjetljenja (eng. Light environment). Moguće je procijeniti reprezentaciju s manjim brojem parametara koja bi vjerno i dalje predstavljala originalnu scenu. Metoda smanjenja broja parametara započinje aproksimacijom izraza za Lambertijsku površinu:
![]()
gdje ![]() predstavlja količinu osvjetljenja koja pada na
površinu, s normalom površine
predstavlja količinu osvjetljenja koja pada na
površinu, s normalom površine ![]() ,
,
![]() predstavljaju poznate konstante,
predstavljaju poznate konstante, ![]() (.)
su sferične harmoničke funkcije a
(.)
su sferične harmoničke funkcije a ![]() nepoznate linearne težine u tim funkcijama.
Sferični harmonici oblikuju ortonormalnu
bazu za kontinuirane funkcije na sferi i analogne su Fourierovoj bazi na
crti ili ravnini. Izraz je linearan u devet koeficijenata okruženja
osvjetljenja
nepoznate linearne težine u tim funkcijama.
Sferični harmonici oblikuju ortonormalnu
bazu za kontinuirane funkcije na sferi i analogne su Fourierovoj bazi na
crti ili ravnini. Izraz je linearan u devet koeficijenata okruženja
osvjetljenja ![]() do
do ![]() te se stoga mogu dobiti koristeći standardnu
procjenu najmanjih kvadrata. Ovo rješenje zahtjeva trodimenzionalne površinske
normale s najmanje devet točaka površine
objekta. Bez više slika ili poznate geometrije , ovaj se zahtjev teško
ispunjava iz jedne istraživane slike.
Ukoliko uzmemo u obzir samo
granicu objekta prethodna se jednadžba pojednostavljuje na :
te se stoga mogu dobiti koristeći standardnu
procjenu najmanjih kvadrata. Ovo rješenje zahtjeva trodimenzionalne površinske
normale s najmanje devet točaka površine
objekta. Bez više slika ili poznate geometrije , ovaj se zahtjev teško
ispunjava iz jedne istraživane slike.
Ukoliko uzmemo u obzir samo
granicu objekta prethodna se jednadžba pojednostavljuje na :
![]()
Gdje funkcije ![]() ovisi jedino o
ovisi jedino o ![]() i
i ![]() komponentama površinske normale
komponentama površinske normale ![]() .
Tj. pet se koeficijenata osvjetljenja može procijeniti iz dvodimenzionalnih
površinskih normala. Jednadžba i dalje ostaje linearna sa svojih pet koeficijenata okruženja
osvjetljenja, koji se mogu procijeniti korištenjem procijene najmanjih
kvadrata. Procijenjeni se koeficijenti mogu usporediti kako bi se otkrilo
nedosljednosti osvjetljenja na slici.
.
Tj. pet se koeficijenata osvjetljenja može procijeniti iz dvodimenzionalnih
površinskih normala. Jednadžba i dalje ostaje linearna sa svojih pet koeficijenata okruženja
osvjetljenja, koji se mogu procijeniti korištenjem procijene najmanjih
kvadrata. Procijenjeni se koeficijenti mogu usporediti kako bi se otkrilo
nedosljednosti osvjetljenja na slici.
5.3.5
Algoritmi
zasnovani na geometriji
Glavna točka
U autentičnim slikama glavna točka (eng. Principal point) predstavlja projekciju centra kamere na ravninu slike, a nalazi se blizu centra slike. Kada se osoba ili objekt translatira na sliku, glavna se točka proporcionalno miče. Razlike u procijenjenim glavnim točkama po slici mogu se koristiti kao dokazi modificiranja slike. Glavna točka kamere može se procijeniti iz slike para očiju, tj dva kruga ili planarnih geometrijskih oblika. Translacija u ravninu slike ekvivalentna je pomaku glavne točke. Granica između irisa oka i šarenice modelirana je krugom. Uzimajući u obzir projiciranje para očiju, krugova koji se pretpostavljaju da su koplanarnog oblika, koordinate transformacije iz svijeta u sliku može se modelirati s matricom planarne transformacijske projekcije veličine 3x3 (eng. Planar projective transformation matrix)
![]()
gdje su točke u
stvarnom svijetu označene s ![]() ,
a točke na slici s
,
a točke na slici s ![]() ,
i predstavljene su dvodimenzionalnim homogenim vektorima. Transformacija
,
i predstavljene su dvodimenzionalnim homogenim vektorima. Transformacija ![]() može se procijeniti iz poznate geometrije očiju osobe
i unijeti kao faktor u produkt matrica koji predstavlja intrinzične i
ekstrinzične parametre kamere:
može se procijeniti iz poznate geometrije očiju osobe
i unijeti kao faktor u produkt matrica koji predstavlja intrinzične i
ekstrinzične parametre kamere:
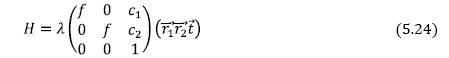
Gdje je lambda skalarni faktor, lijeva matrica
predstavlja intrinzičnu vrijednost gdje
je ![]() točka
fokusa, a
točka
fokusa, a ![]() glavna točka, desna matrica predstavlja
pretvorbu krutog tijela
(rotacija/translacija) između stvarnog svijeta i koordinata kamere. Kada
se jednom uračuna intrinzična matrica daje željene procjene glavne točke.
Ukoliko se iz kompozicije dvoje ili više ljudi
neka osoba bila maknuta s svoje
originalne pozicije, tada će procijenjena glavna točka svake osobe biti
nekonzistentna, što upućuje na manipulaciju slike.
glavna točka, desna matrica predstavlja
pretvorbu krutog tijela
(rotacija/translacija) između stvarnog svijeta i koordinata kamere. Kada
se jednom uračuna intrinzična matrica daje željene procjene glavne točke.
Ukoliko se iz kompozicije dvoje ili više ljudi
neka osoba bila maknuta s svoje
originalne pozicije, tada će procijenjena glavna točka svake osobe biti
nekonzistentna, što upućuje na manipulaciju slike.
Metrička mjerenja
Zamislimo sliku automobila kojim je izvršena pljačka uhvaćenu nadzornom kamerom. Registracijske tablice vidljive su samo djelomice jer je slikana sa strane. Sliku je moguće transformirati tako da tablica izgleda kao da je gledana izravno. Postoji nekoliko alata projektivne geometrije koji omogućuju izravnavanje planarnih površina koji pod određenim uvjetima, omogućuju mjerenja stvarnog svijeta iz slike planarne površine. Alati koriste metode poznavanja poligona i poznatih oblika kao što su prometni znakovi (eng. metric measurements), automobilske tablice, slova na plakatima, točke nestajanja na ravnini i nekoliko poznatih kutova. Koriste dva ili više koplanarna kruga, na primjer automobilske gume. U svim se alatima procjenjuje transformacija iz stvarnog svijeta u sliku, uzimajući u obzir uklanjanje planarnih distorzija i metričkih mjerenja na ravnini [1].
5.4
Razlikovanje prirodnih fotografija i fotorealističnih
računalnih grafika
Kako je fotorealističnom računalnom grafikom (eng. Photorealistic CG) moguće emulirati fotografske slike kakve smo naviknuti gledati u filmovima i ostalim medijima, veoma je jednostavno zamijeniti fotorealističnu računalno generiranu grafiku za fotografiju. Činjenica je kako je već prije dvadeset godina bilo moguće izraditi određene računalne grafike koje ljudsko oko nije bilo u stanju raspoznati kao takve. Takav uvjerljiv fotorealizam kvalificira računalnu grafiku kao oblik slikovnog krivotvorenja koji se u velikoj mjeri koristi. Na internetu je veoma jednostavno pronaći stranice koje nude arhive takvih fotorealističnih slika [15]. Iako se još uvijek u najvećoj mjeri za otkrivanje takvih slika koriste ljudski stručnjaci, zbog njihove količine i samog načina i kvalitete izrade, to u bliskoj budućnosti više neće biti moguće. Stoga su potrebne automatizirane i efektivne računalne metode za klasifikaciju slike kao fotografije ili fotorealistične slike. U kriminalnim istragama verifikacija slike kao fotografije a ne računalno generirane fotorealistične slike može značiti razliku između osude osumnjičenika ili oslobađanja. Osim u digitalnoj forenzici, metode raspoznavanja slika koriste se i prilikom automatske klasifikacije tipa slike i indeksiranja [17].
5.4.1
Nastanak
fotorealistične računalne grafike
Motivacija za sintetiziranje što realističnih slika bila je poticajna sila pri otkrivanju mnogih tehničkih otkrića u fizički zasnovanom grafičkom generiranju kojim se pokušava emulirati proces nastanka fotografija. Sinteza realističnih slika korisna je u simulacijama, dizajnu, edukaciji, oglašavanjima te u mnogim drugim promjenama. Iako je generalni pojam realistične slike dobro poznat, točna definicija ovog pojma još nije usklađena. Općenito se definiraju tri vrste realizma za računalnu grafiku:
·
Fizički realizam: proizvodi istu vizualnu
stimulaciju dubine prostora kao i
stvarna scena
·
Funkcionalni realizam: koji pruža iste
vizualne informacije scene , kao što
su oblici objekata i prostorna dubina
·
Fotorealizam:pruža isti vizualni odgovor kao
scena u stvarnom svijetu
Od ove tri vrste, forenzička se zajednica najviše bavi fotorealističnim CG, koji je današnjim metodama definitivno je ostvariv. Sličnost fotorealizma sa stvarnim scenama i fotografijama često je sveukupan rezultat raznih vizualnih efekata sadržanih u trodimenzionalnoj sceni. Postoje razne razine kompleksnosti u scenama i geometriji objekata, osvjetljenju, te refleksiji površina objekata scene. Kompleksne geometrije scene uzrokuju efekt raspršenja boja (eng. collor bleeding), pri kojem se boje objekta izlijevaju u okolinu zbog interakcije između objekata scene. Kompleksno osvjetljenje sastoji se od nekoliko tipova izvora svjetlosti, dalekih i bliže postavljenih, svjetlost dolazi sa svih strana. Kompleksna reflektivnost objekata uzrokuje transparentan izgled, refleksije, difuzne sjene i odbljeska te zrcaljenja izvora svjetlosti u objektu (eng. specularity). Svi ovi efekti definiraju fotorealizam. Trodimenzionalni grafički sustav uzima scenu sastavljanu od izvora svjetlosti, geometrijskih primitiva s materijalnim svojstvima kao ulazne informacije i generira CG sliku kao izlaznu informaciju. Dakle, dvije važne komponente sinteze fotorealistične grafike su:
1. Modeliranje
scene , što uključuje modeliranje osvjetljenja, refleksije površine objekata,
objektnu geometriju na sceni.
2. Generiranje
scene, izrada.
Fotorealistična se grafika može ostvariti korištenjem realističnog modeliranja scene i ispravne simulacije prijenosa svjetlosti. Modeliranje scene nekada se provodilo parametarskim modeliranjem, dok se danas koriste modeli zasnovani na slikama kojima je moguće vjerno prikazati kompleksnost scene stvarnog svijeta. Za stvaranje osvjetljenja scene koristi se mapa okruženja koja se koristi za modeliranje kompleksnih izvora svjetlosti u CG generiranim slikama. CG generiranje simulira prijenos svjetlosti između izvora osvjetljenja i površine objekta [17]. Efikasan algoritam klasifikacije slike kao fotografije ili fotorealistične računalne grafike opisan je u poglavlju 6.3 .
6. Praktični rad
6.1
Otkrivanje
digitalnih krivotvorina pronalaskom dupliciranih regija slike
Autori Farid i Popescu u [6] opisuju efikasnu metodu koja automatski otkriva duplicirane regije u digitalnim slikama. Ova metoda započinje primjenom analize glavnih komponenti (eng. Principal component analysis, kratica PCA) na male blokove fiksne veličine kako bi dobili reprezentaciju slike smanjene dimenzionalnosti. Ova je reprezentacija otporna na manje varijacije u slici nastale zbog šuma ili kompresije s gubitcima. Duplicirane se regije otkrivaju leksikografskim sortiranjem svih blokova slika.
Korištenjem sve naprednijih alata za obradu digitalnih fotografija, postalo je relativno jednostavno ostvariti krivotvorinu koju je teško razlikovati od autentičnih fotografija. Tip manipulacije slika koji se često provodi je kopiranje dijela slike, te postavljanje tog dijela preko nekog objekta ili osobe ne slici kako bi ga se prikrilo. Ukoliko su granice kopirane regije neprimjetne slika nema razloga bit sumnjiva, te se veoma teško primjećuje manipulacija.
6.1.1
Otkrivanje
dupliciranih regija
Ako je slika sastavljena od ![]() pixela, zadatak je otkriti sadrži li
duplicirane regije neznanog oblika, veličine i lokacije. Jedan od mogućih
pristupa usporedba je svakog mogućeg para pixela, a zadatak bi bio eksponencijalno kompleksan ovisno njihovom broju, što ovaj pristup čini
računalno zahtjevnim i nepoželjnim.
pixela, zadatak je otkriti sadrži li
duplicirane regije neznanog oblika, veličine i lokacije. Jedan od mogućih
pristupa usporedba je svakog mogućeg para pixela, a zadatak bi bio eksponencijalno kompleksan ovisno njihovom broju, što ovaj pristup čini
računalno zahtjevnim i nepoželjnim.
Efektniji algoritam svodi se na pretragu dupliciranih regija
usporedbom blokove fiksne veličine. Pretpostavlja se kako je veličina blokova
znatno manja od dupliciranje regije. Svaki od blokova prikazuju se kao vektori,
potom leksikografski sortiraju, identični blokovi susjedni su retci matrice.
Složenost ovog postupka iznosi ![]() jer broj je broj blokova na koje je
podijeljena slika proporcionalan broju pixela. Iako je ovaj pristup znatno
poboljšanje u odnosu na prethodnu ideju, njegov je nedostatak osjetljivost na
male varijacije među dupliciranim
regijama zbog na primjer šuma ili kompresije
s gubitcima.
jer broj je broj blokova na koje je
podijeljena slika proporcionalan broju pixela. Iako je ovaj pristup znatno
poboljšanje u odnosu na prethodnu ideju, njegov je nedostatak osjetljivost na
male varijacije među dupliciranim
regijama zbog na primjer šuma ili kompresije
s gubitcima.
Jednako efektivan, a manje osjetljiv algoritam provodi se na sljedeći način:
Uzmimo crno bijelu sliku koja se sastoji od ![]() pixela. Slika se dijeli na preklapajuće
blokove od kojih se svaki sastoji od
pixela. Slika se dijeli na preklapajuće
blokove od kojih se svaki sastoji od![]() pixela, dakle dimenzije su mu
pixela, dakle dimenzije su mu ![]() ,
a svaki od njih znatno je manji od tražene duplicirane regije. Neka
,
a svaki od njih znatno je manji od tražene duplicirane regije. Neka ![]() predstavlja blokove u vektorskom obliku, a
broj se blokova određuje izrazom
predstavlja blokove u vektorskom obliku, a
broj se blokova određuje izrazom
![]()
Sljedećih se nekoliko koraka svodi na stvaranje nove reprezentacije matrice blokova provodeći postupak analize glavnih komponenti smanjujući dimezionalnost blokova a da se pritom ne utječe na rezultat pretrage.
Nakon svođenja srednjih vrijednosti elemenata blokova na nulu izrazom
![]()
izračunava se kovariacijska matrica:
![]()
Svojstveni vektori (eng.
Eigenvectors) ![]() , matrice
, matrice ![]() sa pripadajućim svojstvenim vrijednostima
sa pripadajućim svojstvenim vrijednostima ![]() (eng. eigenvalues)
zadovoljavaju :
(eng. eigenvalues)
zadovoljavaju :
![]()
I definiraju glavne komponente kao one koje zadovoljavaju
![]()
Svojstveni vektori ![]() formiraju
novu linearnu bazu svakog bloka
formiraju
novu linearnu bazu svakog bloka ![]() :
:
![]()
gdje
![]()
predstavlja novu
reprezentaciju svakog bloka. Dimezionalnost reprezentacije može se smanjiti
ograničavanjem formule na prvih ![]() članova. Projekcija na prvih
članova. Projekcija na prvih ![]() svojstvenih vektora PCA
analize daje nam najbolju
svojstvenih vektora PCA
analize daje nam najbolju ![]() dimezionalnu
aproksimaciju slike, te pruža prigodan prostor za identifikaciju sličnih
blokova čak i uz prisutnost šuma, jer se smanjenjem baze uklanjaju mane
varijacije u intenzitetu. Nadalje, svaki
se blok
dimezionalnu
aproksimaciju slike, te pruža prigodan prostor za identifikaciju sličnih
blokova čak i uz prisutnost šuma, jer se smanjenjem baze uklanjaju mane
varijacije u intenzitetu. Nadalje, svaki
se blok ![]() kvantizira po komponentama kako bi se i dalje
smanjio utjecaj šuma i manjih varijacija:
kvantizira po komponentama kako bi se i dalje
smanjio utjecaj šuma i manjih varijacija:
![]()
![]() predstavlja broj kvantizacijskih binarnih
znamenki. Konstruira se matrica veličine
predstavlja broj kvantizacijskih binarnih
znamenki. Konstruira se matrica veličine ![]() ,
čiji redovi sadrže kvantizirane
koeficijente. Matrica
,
čiji redovi sadrže kvantizirane
koeficijente. Matrica ![]() predstavlja rezultat leksikografskog
sortiranja po stupcima. Neka
predstavlja rezultat leksikografskog
sortiranja po stupcima. Neka ![]() predstavlja
predstavlja ![]() -ti
redak sortirane matrice, a dvojac
-ti
redak sortirane matrice, a dvojac![]() koordinate gornjeg lijevog kuta bloka na slici
koji pripada retku
koordinate gornjeg lijevog kuta bloka na slici
koji pripada retku ![]() .
U obzir se uzimaju svi parovi redaka
.
U obzir se uzimaju svi parovi redaka ![]() i
i ![]() čija je udaljenost redaka
čija je udaljenost redaka ![]() ,
u sortiranoj matrici
,
u sortiranoj matrici ![]() manja od specificiranog praga. Udaljenosti svih takvih parova u slici računa se izrazima:
manja od specificiranog praga. Udaljenosti svih takvih parova u slici računa se izrazima:
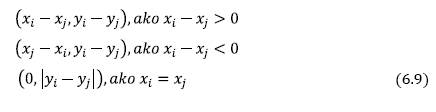
Iz liste svih udaljenosti duplicirane se regije na slici otkrivaju pronalaskom udaljenosti s visokim stupnjem ponavljanja. Na primjer velika će duplicirana regija sadržavati mnogo blokova ,a svaki će od tih blokova biti smješten u blizini ostalih u leksikografsko sortiranoj matrici i posjedovati će isti udaljenost od originalnih blokova. Kako bi se izbjegla lažno pozitivna otkrića do kojih dolazi zbog uniformnosti dijela slika, zanemaruju se sve udaljenosti manje od specificirane granice. Rezultati detekcije dupliciranih regija mogu se vizualizirati konstrukcijom duplikacijske mape, slike veličine originalne slike, a svim se regijama koje se smatra dupliciranim dodjeljuje jedinstvena boja.
Postoji nekoliko načina na koje se ovaj algoritam može
proširiti na slike u boji, a najjednostavniji od njih je neovisno procesirati
svaki kanal boje, kako bi se došlo do duplikacijskih mapa. Drugi je način
primijeniti PCA analizu na blokove u boji veličine ![]() ,
te nastaviti s algoritmom na gore opisan način.
,
te nastaviti s algoritmom na gore opisan način.
6.1.2
Algoritam
detekcije dupliciranih regija
1.
Neka je ![]() broj pixela u nekoj slici
broj pixela u nekoj slici
2.
Inicijalizirati parametre:
-
![]() :broj pixela po bloku,
:broj pixela po bloku, ![]() broj blokova slike
broj blokova slike
-
![]() : frakcija
ignorirane varijance po glavnim osima
: frakcija
ignorirane varijance po glavnim osima
-
![]() : broj
kvantizacijskih znamenki
: broj
kvantizacijskih znamenki
-
![]() : broj
susjednih redaka koje treba pretražiti u leksikografsko sortiranoj matrici
: broj
susjednih redaka koje treba pretražiti u leksikografsko sortiranoj matrici
-
![]() : minimalan
prag frekvencije pojavljivanja
: minimalan
prag frekvencije pojavljivanja
-
![]() : Minimalan
prag udaljenosti
: Minimalan
prag udaljenosti
3.
Korištenjem PCA analize, izračunati novu ![]() dimenzionalnu reprezentaciju
dimenzionalnu reprezentaciju ![]() svakog
pixela u bloku. Vrijednost
svakog
pixela u bloku. Vrijednost ![]() parametra bira
se tako da zadovoljava:
parametra bira
se tako da zadovoljava:
![]()
gdje su ![]() svojstvene vrijednosti izračunate PCA
analizom.
svojstvene vrijednosti izračunate PCA
analizom.
4.
Izgraditi matricu veličine ![]() čiji su
retci kvantizirane vrijednosti
čiji su
retci kvantizirane vrijednosti ![]()
5.
Leksikografski rotirati retke matrice kako bi dobili
matricu ![]() . Neka
. Neka ![]() predstavlja retke matrice
predstavlja retke matrice ![]() , a
, a ![]() poziciju bloka u slici.
poziciju bloka u slici.
6.
Za svaki par redaka ![]() i
i ![]() matrice
matrice![]() koji
zadovoljavaju
koji
zadovoljavaju ![]() ,
smjestiti koordinate u listu
,
smjestiti koordinate u listu
7.
Za sve elemente u listi izračunati fizičke
udaljenosti blokova na slici
8.
Odbaciti sve parove kojima je frekvencija pojavljivanja manja od ![]()
9.
Odbaciti sve parove kojima je udaljenost ![]()
10. Od
preostalih se parova blokova gradi duplikacijska mapa
6.1.3
Rezultati
Gore naveden algoritam ostvaren je programskim okruženjem
Matlab. Slike su modificirane kopiranjem dijela slike preko nekog objekta ili
drugog dijela slike. Ispitivanja su se provodila za modificirane slike veličine
![]() pixela sačuvane s JPEG faktorima kvalitete 80
ili 100 posto.U svim su primjerima parametri postavljeni na:
pixela sačuvane s JPEG faktorima kvalitete 80
ili 100 posto.U svim su primjerima parametri postavljeni na: ![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() te
te ![]() .
Uporabom PCA analize dimenzionalnost se najčešće smanjila sa 64 na 54 . Autori
algoritma [6],
predlažu dilataciju i eroziju duplikacijske mape zbog vizualnih razloga, kako
bi se uklonile rupe u dupliciranim regijama, te nepovezani otkriveni
duplicirani blokovi. Preciznost algoritma ispitivana je na nizu primjera, i
općenito je dobra, osim kod kopiranja veoma malih regija, te kod slika niske
JPEG kvalitete. Tada se pojavljuje više lažno pozitivno identificiranih blokova.
Na slikama u nastavku su prikazane originalne slike, modificirane
slike i duplikacijske mape.
.
Uporabom PCA analize dimenzionalnost se najčešće smanjila sa 64 na 54 . Autori
algoritma [6],
predlažu dilataciju i eroziju duplikacijske mape zbog vizualnih razloga, kako
bi se uklonile rupe u dupliciranim regijama, te nepovezani otkriveni
duplicirani blokovi. Preciznost algoritma ispitivana je na nizu primjera, i
općenito je dobra, osim kod kopiranja veoma malih regija, te kod slika niske
JPEG kvalitete. Tada se pojavljuje više lažno pozitivno identificiranih blokova.
Na slikama u nastavku su prikazane originalne slike, modificirane
slike i duplikacijske mape.

Slika 6.1 Originalna slika

Slika 6.2 Izmjenjena slika

Slika 6.3 Otkriveni duplicirani dijelovi slike 6.2

Slika 6.4 Originalna slika

Slika 6.5 Izmjenjena slika

Slika 6.6 Otkriveni duplicirani dijelovi slike 6.5

Slika 6.7 Originalna slika

Slika 6.8 Izmjenjena slika

Slika 6.9 Otkriveni duplicirani dijelovi slike 6.8

Slika 6.10 Originalna slika

Slika 6.11 Izmjenjena slika

Slika 6.12 Otkriveni duplicirani dijelovi slike 6.11
Slike 6.2 i i 6.5 sačuvane su nakon modificiranja JPEG faktorom kvalitete 100%, a slike 6.8 i 6.11 JPEG faktorom kvalitete 80%. Iz rezultata je vidljivo kako kvaliteta kompresije znatno utječe na preciznost algoritma. Kod slika sačuvanih s faktorom kvalitete 100% veličina kopirane regije nije znatno utjecala na otkrivanje modifikacije. Kod slika sačuvanih s faktorom kvalitete 80% općenito je veća vjerojatnost preciznijeg otkrivanja kopiranih regija kada su one veće. Što je veći faktor kvalitete, algoritam će imati manje lažno pozitivnih blokova klasificiranih kao duplicirane regije. Rezultate je moguće poboljšati dilatacijom i erozijom duplikacijske mape. Tim se postupkom popunjavaju rupe u pronađenim dupliciranim regijama nastalim zbog uniformnosti i odbacivanja nekih blokova, te uklanjaju nepovezani lažno pozitivno klasificirani blokovi. Obrada slika prosječno traje dvije do tri minute.
6.2
Otkrivanje
steganografskih poruka u digitalnim slikama
Metode i aplikacije za skrivanje informacija postale su sofisticiranije i raširenije. A otkrivanje prisutnosti skrivenih poruka postalo je teže u slikama visoke rezolucije kao nositeljima. Nekad je ipak moguće otkriti prisutnost ukomponirane poruke, ali ne nužno i dešifrirati njen sadržaj. Osnovni se pristup zasniva na pronalaženju predvidivih statistika višeg reda prirodnih fotografija s dekompozicijom na nekoliko razina. Sakrivene poruke mijenjaju te statistike.
Metode skrivanja poruka i digitalni vodeni žig, koriste se zbog zaštite autorskih prava digitalnih audio zapisa,slika i video zapisa od kopiranja, za neprimjetnu vojnu i obavještajnu komunikaciju, kao i kriminalnu. Koriste se i za zaštitu slobode govora civila u represivnim sustavima vlasti.
Iako su poruke ugrađene u slike gotovo uvijek nevidljive ljudskom oku, one poremećuju statističku prirodu slike. Većina statističkih pristupa rješavanju ovog problema koriste statistike prvog reda, kao što su distribucije intenziteta ili koeficijenata diskretne kosinusne transformacije DCT. H. Farid predlaže u [5] pristup koji se oslanja na gradnju statističkih modela više razine za fotografije, a prisutnost steganografske poruke otkriva se devijacijama od tog modela. U prirodnim fotografijama postoji širok spektar statističkih regularnosti, pravilnosti višega reda u dekompoziciji valićima (eng. Wavelet decomposition), a kada se poruka ugradi u sliku te se statistike znatno mijenjaju. Prednost građenja modela zasnovanog na statistikama višeg reda je da steganografski softver većinom može zavarati algoritme zasnovane na statistikama prvog reda.
6.2.1
Statistika
slika
Dekompozicija slika korištenjem baznih funkcije lokaliziranih u prostoru, orijentaciji i skali ,kao što je wavelet, pokazale su se veoma korisnima prilikom kompresije slika, kodiranja slika, uklanjanja šuma, sinteze teksture. Jedan od razloga zbog kojeg ove dekompozicije imaju tako široku primjenu je postojanje statističkih regularnosti koje se mogu iskoristiti.
Dekompozicija se zasniva na Separable quadrature mirror filters, ili skraćeno QMF. QMF filtri najčešće se koriste pri digitalnoj obradi signala. Oni dijele signal na dvije razine ovisno o frekvencijama; visoko prolazni i niskoprolazni signal, koji se često umanjuju za faktor dva. Filtriranjem dobivamo dvokanalnu reprezentaciju originalnog kanala.
U ovom slučaju dekompozicija dijeli prostor frekvencije u mnogostruke skale i orijentacije.
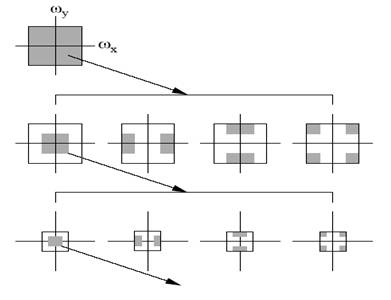
Slika 6.13 Idealizirana dekompozicija frekvencijskog prostora
Slika 6.13 prikazuje
idealiziranu dekompoziciju frekvencijskog prostora na više razina i
orijentacija. Gledajući od vrha slike prema dnu, prikazane su razine nula jedan
i dva, gledajući s lijeva na desno prikazani su niskopropusni vertikalni,
horizontalni i dijagonalni potpojas. To se postiže korištenjem odvojivih
niskopropusnih i visokopropusnih filtera
uz osi slike generirajući
pritom vertikalni, horizontalni i
dijagonalni niskopropusni potpojas. Na
primjer horizontalni potpojas generira
se konvolucijom signala visokopropusnog filtra
u horizontalnom smjeru i niskopropusnog
u vertikalnom smjeru. Dijagonalni pojas nastaje konvolucijom
signala visokopropusnog filtera
dobivenog prolaskom u oba smjera. Naknadna skaliranja stvaraju se rekurzivnim filtriranjem niskopropusnih
potpojaseva. Vertikalni, horizontalni i dijagonalni potpojasevi u skali ![]() prikazuju se kao
prikazuju se kao ![]() .
.

Slika 6.14 Apsolutne vrijednosti koeficjenata potpojaseva na 3 razine i orijentacije
Slika prikazuje trorazinsku dekompoziciju slike diska.
Gledajući dekompoziciju slike, statistički model sastavljen je od; srednje
vrijednosti (eng. mean), varijance,
asimetrije (eng. Skewness), i zakrivljenosti (eng. Kurtosis) koeficijenata
potpojasa u svakoj orijentaciji i na razinama![]() .
Te statistike karakteriziraju osnovnu distribuciju koeficijenata.
.
Te statistike karakteriziraju osnovnu distribuciju koeficijenata.
Drugi skup sakupljenih statističkih podataka temelji se na
pogrešci u optimalnom linearnom prediktoru veličine koeficijenata. Koeficijenti
potpojaseva korelirani su sa svojim prostornim, orijentacijskim i skaliranim
susjedima. Prvi vertikalni pojas na
skali i označimo sa ![]() .
Linearni prediktor iznosa koeficijenata u
podskupu svih mogućih susjeda
dobiva se :
.
Linearni prediktor iznosa koeficijenata u
podskupu svih mogućih susjeda
dobiva se :
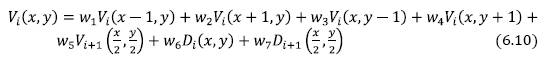
Gdje ![]() označava skalarnu težinsku vrijednost. Ova
linearna veza može se izraziti i
matričnom obliku:
označava skalarnu težinsku vrijednost. Ova
linearna veza može se izraziti i
matričnom obliku:
![]()
Vektor ![]() ,
sadrži veličine koeficijente vektora
,
sadrži veličine koeficijente vektora ![]() u obliku
vektora stupca, a stupci matrice
u obliku
vektora stupca, a stupci matrice ![]() sadrže susjedne veličine koeficijenata.
Koeficijent koji minimizira kvadratnu pogrešku estimatora :
sadrže susjedne veličine koeficijenata.
Koeficijent koji minimizira kvadratnu pogrešku estimatora :
![]()
Logaritamska pogreška linearnog prediktora tada glasi :
![]()
Iz te se pogreške sakupljaju dodatne statistike srednje vrijednosti, varijance,
zakrivljenosti i asimetrije. Ovaj se
proces ponavlja za svaki vertikalni
potpojas i razine ![]() ,
a na svakoj se razini procjenjuje novi linearni prediktor. Sličan
se proces ponavlja i za horizontalne i dijagonalne potpojaseve.
,
a na svakoj se razini procjenjuje novi linearni prediktor. Sličan
se proces ponavlja i za horizontalne i dijagonalne potpojaseve.
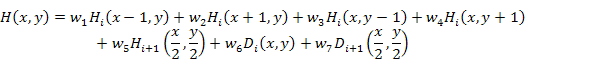
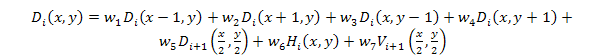 (6.14)
(6.14)
Isto vrijedi i za metriku pogrešaka. Statistike
pogrešaka računaju se za vertikalni
potpojas, horizontalni i dijagonalni, i sveukupno imamo ![]() statističkih koeficijenata pogreške.
Kombiniranjem tih statistika s
statistikama prikupljenih koeficijenata
statističkih koeficijenata pogreške.
Kombiniranjem tih statistika s
statistikama prikupljenih koeficijenata ![]() imamo sveukupno
imamo sveukupno ![]() statističkih koeficijenata koji formiraju vektor obilježja koji se koristi za diskriminaciju među
porukama koje sadrže skrivene poruke, od onih koje ne sadrže.
statističkih koeficijenata koji formiraju vektor obilježja koji se koristi za diskriminaciju među
porukama koje sadrže skrivene poruke, od onih koje ne sadrže.
6.2.2
Klasifikacija
Od prikupljenih vektora statističkih koeficijenata formiraju se skupovi za treniranje slika sa i bez skrivenih poruka. Potom se gradi granica klasifikacije. U tu se svrhu koristi analiza Fisherovom linearnom diskriminantom (eng Fisher linear discriminant analysis, skrać FLD).
FLD metoda je raspoznavanja uzoraka, u ovom se slučaju zbog jednostavnosti koristi FLD s dvije klase.
Neka su vektori stupci ![]() i
i ![]() uzorci iz dvaju klasa uzoraka za treniranje.
Srednje vrijednosti unutar klase definiraju se kao:
uzorci iz dvaju klasa uzoraka za treniranje.
Srednje vrijednosti unutar klase definiraju se kao:
![]()
A srednje vrijednosti među klasama
![]()
Matrica raspršenja unutar klase:
![]()
Gdje ![]() -ti stupac matrice
-ti stupac matrice ![]() sadrži
uzorak sa srednjom vrijednosti jednakom nuli dobiven izrazom
sadrži
uzorak sa srednjom vrijednosti jednakom nuli dobiven izrazom ![]() .
Slično,
.
Slično, ![]() -ti stupac matrice
-ti stupac matrice ![]() sadrži uzorak sa srednjom vrijednosti jednakom
nuli dobiven izrazom
sadrži uzorak sa srednjom vrijednosti jednakom
nuli dobiven izrazom ![]() . Matrica raspršenja među klasama definirana
je kao:
. Matrica raspršenja među klasama definirana
je kao:
![]()
Neka je ![]() maksimalna generalizirana svojstvena vrijednost matrice svojstvenih vektora
maksimalna generalizirana svojstvena vrijednost matrice svojstvenih vektora ![]() i
i ![]() , tj.
, tj. ![]() . Kada se primjerci skupa za treniranje projiciraju
na jednodimenzionalan linearni potprostor
definiran sa
. Kada se primjerci skupa za treniranje projiciraju
na jednodimenzionalan linearni potprostor
definiran sa ![]() ,
raspršenje među klasama se maksimizira, dok se raspršenje unutar klasa
minimizira, olakšavajući time klasifikaciju. Takav je tip projekcije koristan
jer smanjuje dimenzionalnost podataka i čuva razlike.
,
raspršenje među klasama se maksimizira, dok se raspršenje unutar klasa
minimizira, olakšavajući time klasifikaciju. Takav je tip projekcije koristan
jer smanjuje dimenzionalnost podataka i čuva razlike.
Nakon što je utvrđena os FLD projekcije, ispituje se novi primjer iz skupa za ispitivanje. Prvo se projicira na isti linearni prostor, te se pomoću praga utvrđuje kojoj klasi pripada. U slučaju dvoklasnog FLD klasifikatora, uvijek je moguće uzorke projicirati na jednodimenzionalan podprostor, tj uvijek će postojati barem jedna svojstvena vrijednost koja neće biti jednaka nuli.
6.2.3
Realizacija
i rezultati
Algoritam je ostvaren korištenjem programskog okruženja Matlab. Svaka je korištena slika veličine 1024X1024 bita. Prikupljene su statistike za 200 slika.
Svaka se slika komprimira korištenjem steganografskog programa Jsteg [14], bez umetanja poruke na prosječnu veličinu 300kb, kvalitete 75. Potom se RGB slike pretvaraju u crno bijele. U pedeset je od tih slika ugrađena slikovna poruka veličine 256 x 256 pixela, u 50 slika veličine 128 x 128 pixela, a u sljedećih pedeset poruka veličine 32x32 pixela, a pedeset slika ostalo je prazno. Za svaku se od njih konstruira QMF piramida na četiri razine i tri orijentacije koristeći skup alata matlabPyrTools [9]. Iz te se piramide izvlači vektor značajki sa 72 koeficijenta na temelju kojeg se obavlja klasifikacija. Kako bi se smanjila osjetljivost na šum, u obzir se uzimaju samo koeficijenti čija je vrijednost veća od 1.
Za klasifikaciju fotografija koristi se dvoklasni FLD klasifikator [13] opisan u prethodnom poglavlju. Treniranje je provedeno na podskupu od osamdeset slika za svaku od tri veličina umetnutih poruka, a ispitivanje naučenog praga klasifikacije na podskupu od dvadeset. Autori ovog algoritma su u isti skup slika koji su koristili kao skup bez poruka, umetnuli steganografsku poruku, te time smanjili broj lažno pozitivnih klasifikacija slika u kojima nije bilo skrivenih poruka [5]. Ja sam koristila različite skupove, jer smatram kako takvi uvjeti više odgovaraju nekakvoj realnoj situaciji ispitivanja slika.
Tablica 6.1 Rezultati ispitivanja algoritma
|
Veličina umetnute poruke |
Otkrivanje |
Lažno pozitivno otkrivanje |
|
256 x 256 pixela |
100 % |
40% |
|
128 x 128 pixela |
81.82% |
45.45% |
|
32 x 32 pixela |
62% |
57% |
Nakon što je naučena klasifikatorska granica za željenu veličinu umetnutih poruka, moguće je ispitivati pojedinačne slike. Za njih se konstruira statistički wavelet vektor značajki, te se nakon projiciranja na pronađeni maksimalni svojstveni vektor uspoređuje jeli veći ili manji od naučenog praga klasifikacije, time se sliku svrstava u jednu od dviju klasa. Prilikom ispitivanja slika s umetnutim porukama većim od onih korištenih za treniranje klasifikatora postotak detekcije bio je stopostotan, dok je u obrnutim situacijama bio gotovo nula.
6.2.4
Diskusija
Poruke se mogu ugraditi u digitalne slike na načine neprimjetne ljudskom oku, ali ipak te promijene iz temelja mijenjaju statistiku slike. Kako bi se otkrila prisutnost skrivene poruke, koristi se model zasnovan na statistici dobivenoj dekompozicijom na više razina. Ovaj model uključuje osnovne statističke koeficijente kao i statistike pogreške dobivene optimalnim linearnim prediktorom veličine koeficijenata. Statistike višeg reda sadržavaju određena svojstva prirodnih slika, i što je važnije te se statistike znatno mijenjaju kada se poruka ugradi u sliku. Time je s razumnom razinom točnosti moguće utvrditi prisutnost steganografske poruke.
Kako bi se izbjeglo otkriće skrivene poruke ovim algoritmom, potrebno je samo ugraditi dovoljno malenu poruku. Razina detekcije opada i ova je metoda manje pouzdana korištenjem manjih poruka.
6.3
Algoritam
za razlikovanje fotorealističnih slika od fotografija
Autori Lyu i Farid [4] predlažu korištenje statističkog modela.
Koristi se isti statistički model kao i za otkrivanje
steganografskih poruka, jedina razlika je u tome što se dekompozicija provodi
neovisno za svaki kanal RBG. Vertikalni, horizontalni i dijagonalni potpojasevi
za razinu ![]() definirani su kao:
definirani su kao:
![]()
Wawelet koeficijenti potpojaseva obično prate distribuciju modeliranu generaliziranom Laplace funkcijom
![]()
gdje![]() i
i ![]() predstavljaju parametre gustoće, a
predstavljaju parametre gustoće, a ![]() normaliziranu konstantu. U ovoj grupi gustoće
se karakteriziraju oštrim skokom u nuli i velikim simetričnim repovima.
Intuitivno objašnjenje glasi kako prirodne slike obično sadrže velike glatke
regije i nagle prijelaze , na primjer
rubove. Glatka područja, iako dominantna, dobivaju koeficijente malog iznosa, blizu nule, dok prijelazi generiraju
velike koeficijente. U statističkom se modelu umjesto izravno procijenjenih
generaliziranih Laplaceovih distribucija koristi jednostavniji pristup
karakteriziranja tih marginalnih distribucija. Sakupljaju se četiri tipa statističkih podataka (mean, variance, skewness, kurtosis) koeficijenata potpojaseva pri svakoj orijentaciji, razini i kanalu boje. Te statistike čine prvu
polovicu statističkog modela.
normaliziranu konstantu. U ovoj grupi gustoće
se karakteriziraju oštrim skokom u nuli i velikim simetričnim repovima.
Intuitivno objašnjenje glasi kako prirodne slike obično sadrže velike glatke
regije i nagle prijelaze , na primjer
rubove. Glatka područja, iako dominantna, dobivaju koeficijente malog iznosa, blizu nule, dok prijelazi generiraju
velike koeficijente. U statističkom se modelu umjesto izravno procijenjenih
generaliziranih Laplaceovih distribucija koristi jednostavniji pristup
karakteriziranja tih marginalnih distribucija. Sakupljaju se četiri tipa statističkih podataka (mean, variance, skewness, kurtosis) koeficijenata potpojaseva pri svakoj orijentaciji, razini i kanalu boje. Te statistike čine prvu
polovicu statističkog modela.
Ove statistike opisuju distribuciju osnovnih koeficijenata,
no malo je vjerojatno kako će njima biti moguće uhvatiti jake korelacija koje
postoje kroz prostor,orijentaciju i
razine. Na primjer obilježja slike kao
što su rubovi imaju tendenciju prostorne
orijentacije u određenim smjerovima i protežu se kroz više razina. Te osobine
slike rezultiraju u lokalnoj energiji na više razina orijentacija i prostornih
lokacija. Lokalna se energija može grubo izmjeriti iznosom koeficijenata
dekompozicije. Tako bi velik koeficijent u horizontalnom potpojasu moga biti pokazatelj kako njegovi lijevi i desni prostorni susjedi
u istom potpojasu također imaju veliku vrijednost. Slično, ako postoji
koeficijent s velikim iznosom na razini ![]() veoma je vjerojatno kako i njegov „roditelj“
na razini
veoma je vjerojatno kako i njegov „roditelj“
na razini ![]() također velikog iznosa.
također velikog iznosa.
Kako bi uhvatili neke od tih korelacija statistika višeg
reda, sakuplja se drugi skup statistika zasnovanih na pogreškama linearnog prediktora iznosa koeficijenata. Na
primjer uzmimo vertikalnu komponentu zelenog kanala na razini![]() ,
,
![]() .
Linearni prediktor iznosa koeficijenata u podskupu svih mogućih prostornih, orijentacijskih, susjeda na
drugim razinama i drugih boja može se opisati izrazom:
.
Linearni prediktor iznosa koeficijenata u podskupu svih mogućih prostornih, orijentacijskih, susjeda na
drugim razinama i drugih boja može se opisati izrazom:
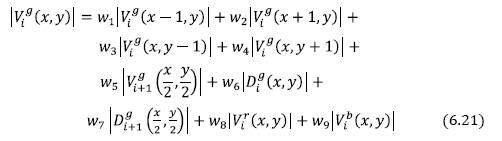
Ovaj se linearni izraz može kompaktnije napisati u matričnom obliku:
![]()
Vektor ![]() sadrži iznose koeficijenata
sadrži iznose koeficijenata ![]() u obliku vektora stupca, a kako bi se smanjila
osjetljivost na šum u obzir se uzimaju samo koeficijenti čija je vrijednost
veća od 1. Stupci matrice
u obliku vektora stupca, a kako bi se smanjila
osjetljivost na šum u obzir se uzimaju samo koeficijenti čija je vrijednost
veća od 1. Stupci matrice ![]() sadrže iznose koeficijenata susjednih pixela
definiranih u izrazu (6.21). Težinski koeficijenti
sadrže iznose koeficijenata susjednih pixela
definiranih u izrazu (6.21). Težinski koeficijenti ![]() određuju se minimiziranjem kvadratne funkcije
pogreške
određuju se minimiziranjem kvadratne funkcije
pogreške
![]()
diferencijacijom s obzirom na ![]() :
:
![]()
Kako je korišten linearni prediktor, logaritamska pogreška između izračunatih i predviđenih koeficijenata dobiva se izrazom:
![]()
Računa se pojedinačno za svaku komponentu vektora. Potom se sakupljaju srednja vrijednost, varijanca, zakrivljenost
i asimetrija, kao i za statistiku koeficijenata slike. Ovaj se proces ponavlja
za razine ![]() ,
te za potpojaseve
,
te za potpojaseve ![]() i
i ![]() ,
čiji se linearni prediktori definiraju kao:
,
čiji se linearni prediktori definiraju kao:
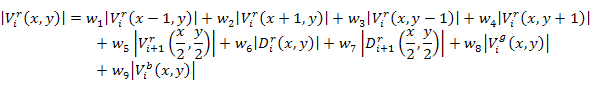
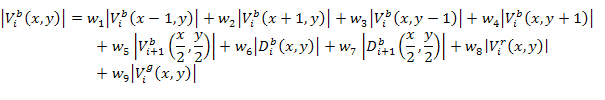
(6.26)
Sličan se proces ponavlja i za horizontalni i dijagonalni potpojas.
Za višerazinsku dekompoziciju na ![]() razina, broj osnovnih statističkih
koeficijenata iznosi
razina, broj osnovnih statističkih
koeficijenata iznosi ![]() tj
tj ![]() po kanalu boje, konačan broj statistika
pogrešaka je također
po kanalu boje, konačan broj statistika
pogrešaka je također ![]() što svodi sveukupan broj statitičkih
koeficijenata sadržanih u vektoru značajki na
što svodi sveukupan broj statitičkih
koeficijenata sadržanih u vektoru značajki na ![]() koji se koristi za diskriminaciju fotorealističnih slika od
fotografija. Klasifikacija se obavlja FLD analizom, dijeljenjem fotorealistične
i fotografske skupove na skup za učenje i skup za ispitivanje.
koji se koristi za diskriminaciju fotorealističnih slika od
fotografija. Klasifikacija se obavlja FLD analizom, dijeljenjem fotorealistične
i fotografske skupove na skup za učenje i skup za ispitivanje.
6.3.1
Rezultati
Algoritam je ostvaren korištenjem programskog okruženja Matlab. Slike prikazuju nekoliko fotorealističnih slika korištenih za ispitivanje algoritma preuzetih sa stranice [15].



Slika 6.15 Primjeri fotorealističnih fotografija
Za ispitivanje algoritma korišteno je 100 fotorealističnih slika generiranih raznim alatima, koje prikazuju raznolike tipove scena, te 100 fotografija. Sve su slike u boji, JPEG kvalitete kompresije oko 90%. Toj se bazi od 200 slika sakupilo statističke koeficijente korištenjem [16], na način opisan u prethodnom poglavlju. Zbog različitih veličina korištenih slika i fotografija, odreže se samo centralni dio veličine 256 x 256 pixela, jer se u ovom algoritmu, za razliku od algoritma otkrivanja steganografskih poruka ne mora ispitivati cijela slika. Za svaku se sliku konstruira QMF piramida za svaki kanal boje na četiri razine i u tri orijentacije korištenjem [9]. Dobiva se statistički vektor značajki veličine 216 koeficijenata (72 po kanalu boje). Za treniranje klasifikatora korišteno je 170 slika, a ostatak vektora karakteristika korišteno je za ispitivanje naučene granice.
Za ispitivani skup slika dobiveni su sljedeći rezultati:
Tablica 6.2 Rezultati ispitivanja
|
|
Ispravno klasificirano |
Lažno pozitivno |
|
Fotografije |
70% |
30% |
|
Fotorealistične slike |
75% |
25% |
Nakon naučene granice klasifikacije, moguće je pojedinačno ispitivati nove primjere slika, uspoređujući njihovu projekciju vektora značajki na svojstveni vektor pripadajuće maksimalne svojstvene vrijednosti, te uspoređujuću iznos s naučenom granicom klasa.
7. Zaključak
Današnja tehnologija omogućava promjenu i manipulaciju digitalnim medijem na načine koji su prije nekoliko godina bili nemogući. Buduća tehnologija gotovo će sigurno omogućiti manipulacije digitalnih medija na način koji se danas čini nemogućim. Kako tehnologija nastavlja evoluirati biti će sve važnije da znanost digitalne forenzike drži korak s tim razvojem. Kako se razvijaju tehnike i metode za otkrivanje fotografskih prijevara, razviti će se i nove sofisticiranije metode izrade krivotvorina koje će biti teže otkriti.
Ostvareni algoritam detekcije dupliciranih regija veoma je praktičan alat prilikom otkrivanja jedne od najjednostavnijih i najraširenijih metoda manipulacije slikama. Iako mu se preciznost smanjuje lošijom kvalitetom slike ili manjom kopiranom regijom, u velikoj je većini slučajeva bilo moguće razaznati kopirane dijelove. Time ispitivač može dobiti uvid u veličinu i lokaciju kopirane regije te promjenom iznosa koeficijenata veličine blokova i kvantizacijskih bitova dobiti bolji i precizniji izlazni rezultat.
Iako ostvarenim algoritmom za otkrivanje steganografskih poruka nije moguće izvući skrivenu poruku, moguće je potvrditi postoji li uopće u istraživanoj slici. Ova činjenica veoma je važna, jer je broj steganografskih alata velik, a provjera svih sumnjivih slika neke istrage mogla bi trajati veoma dugo. Svi dostupni steganografski alati mijenja statistike višeg reda slika u koje ugrađuju poruke, što ostvareni alati čini savršenim za otkrivanje manipulacija. No ukoliko se u sliku steganografskim alatom ugradi dovoljno mala poruka, gotovo ju je nemoguće otkriti statističkim algoritmom, jer mu učinkovitost naglo opada ukoliko je skrivena poruka manja od pet posto veličine slike u koju je ugrađena.
Današnje je fotorealistične računalne grafike ljudskom oku teško razlikovati od stvarnih fotografija, no njihove statistike višeg reda znatno se razlikuju, što omogućava provjeru metode nastanka slike konstrukcijom statističkih modela. Klasifikacija se odvija na temelju usporedbe ispitivane slike s postojanim karakteristikama prikupljenih od baze podataka poznatih slika. Iako je ova metoda veoma uspješna moguće je prevariti algoritam ukoliko se fotorealistična slika fotografira. Algoritam neće biti u stanju sa sigurnošću utvrditi radi li se o računalno generiranoj slici ili pravoj fotografiji.
Polje digitalne forenzike slika novim metodama, algoritmima i alatima nastaviti će otežavati izrade uvjerljivih krivotvorina koje su u mogućnosti zavarati te alate. Samim time izrada krivotvorina zahtijevati će više vremena, te postajati sve kompleksniji proces, no nikada se u potpunosti neće moći zaustaviti.
8.
Literatura
[4]
Siwei
Lyu, Hani Farid, „How
realistic is Photorealistic“,
Dartmuth College, Department of Computer Sciences, 2006
[5]
Siwei
Lyu, Hani Farid, „Detecting
Steganographic Messages in Digital images“, Dartmuth College, Department of Computer
Sciences, 2006
[6]
A. C.
Popescu, H. Farid, „Exposing
Digital Forgeries by Detecting Duplicated Image Regions“, Dartmuth College, Department of Computer
Sciences, 2004
[7] B. D. Carrier, „Digital forensics works“,
IEEE Security & Privacy, volume 7,
number 2, 2009
[9]
matlabPyrTools, skup funkcija za programsko
okruženje Matlab kojima se među ostalim
mogu sakupljati statistike slika, http://www.cns.nyu.edu/~lcv/software.php, Travanj 2010
[10] Računalna forenzika, legislativa u RH
[11] R.Nolan, J. Branson, C. Wait, C. O'Sullivan, „First responders guide to Computer Forensics“, CERT 2005
[12] L. Volonino, R. Anzaldua, „Computer Forensics“,Wiley publishing inc., 2008
[13] H. Farid, Steganography matlab routines, http://www.cs.dartmouth.edu/farid/research/steganography.html, Travanj 2010
[14] Izvorni tekst steganografskog programa Jsteg, http://jsteg.org/
[15] Korištene fotorealistične slike dobavljene su s internet adrese http://www.raph.com/3dartists/, travanj 2010
[16] Matlab rutine za algoritam otkrivanja fotorealističnih slika, http://www.cs.dartmouth.edu/farid/research/cgorphoto.html , Travanj 2010
[18] Informacije o dokumentima i njihovim zaglavljima; www.fileinfo.net
9. Sažetak
Digitalnu forenziku
čine metode prikupljanja, analize i prezentacije dokaza koji se mogu pronaći na
računalima, poslužiteljima, računalnim mrežama, bazama podataka, mobilnim
uređajima, te svim ostalim elektroničkim uređajima na kojima je moguće
pohraniti podatke. Digitalna forenzika
slika bavi se analizom digitalnih fotografija te utvrđivanjem mjesta i načina
njihova nastanka, utvrđivanjem identifikacijskog otiska kamere, kao i otkrivanjem vrste manipulacija nad
slikama. U ovom su radu opisane metode prikupljanja digitalnih dokaza, njihove analize, kao i
taksonimija digitalne forenzike. Nadalje, u radu su opisani najčešći tipovi
manipulacije nad slikama kao i algoritmi ostvareni za njihovo otkrivanje. U praktičnom dijelu
rada, prema predlošcima njihovih autora, ostvarena su i ispitana tri algoritma za otkrivanje
manipulacija slika; algoritam za
otkrivanje dupliciranih regija slike, algoritam za otkrivanje postojanja
steganografskih poruka te algoritam za razlikovanje fotorealističnih računalno
generiranih slika od fotografija. Drugi i treći algoritam ostvareni su
korištenjem slobodno dostupnih dijelova izvornih tekstova programa.
Ključne riječi
Digitalna
forenzika, računalna forenzika, digitalna forenzika slika, steganografija,
fotorealistična računalna grafika, duplicirane regije slika, identifikacijski
otisak kamere.
10. Summary
Digital forensics can be described as a set of methods
for collecting, analyzing and presenting digital evidence which can be found on
computers, servers, computer networks, databases, mobile devices, and every
other digital device on witch data can be stored. The primary task of digital image forensics
is to analyze digital photographs and images, to determine the method and place
in which they were created, to determine identifying camera fingerprints, to discover if a picture has been
manipulated and how. Methods for collecting and analysis of digital evidence
and existing sub branches within the field of digital forensics are described
in this paper along with the most frequent types of digital image manipulation,
and the corresponding algorithms developed for detecting those manipulations.
Three algorithms have been recreated and tested in the practical part of this
paper; the algorithm for discovering duplicate regions in a photograph, the algorithm
for determining the presence of a Steganographic message in an image and the
algorithm for distinguishing between computers generated photorealistic
graphics and photographs. The last two algorithms were recreated using parts of
freely available code published by the authors.
Key words:
Digital forensics, computer forensics, digital image
forensics, Steganography, photorealistic CG, duplicate image regions, camera
identifying fingerprint.