|
FER, ZEMRIS
Autor: Markić Željko e-mail: markic.zeljko@fer.hr Sadržaj: 2. Pseudoslučajni i slučajni brojevi 2.1.
Pseudoslučajni brojevi (uvod) 3.1.
Osnove. 1. Uvod"O, mnoge su zrake (sunca) slučajno
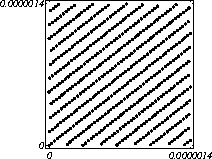
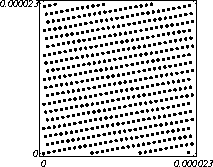
poslane U današnjem svijetu gdje je red sve i gdje su ljudi opsjednuti time da uvedu nekakav red u svoje živote čini se pomalo čudnim da je za temu ovoga rada izabrano nešto potpuno suprotno – slučajne brojeve i njihova primjena ili drukčije gledano – kaos. Taj kaos, nevjerovatno ali istinito, ima velik utjecaj i primjenu u našim životima. Najveći utjecaj naravno ima u najnaprednijim i najzahtjevnijim područijima rada gdje se treba imitirati taj kaos da bi se predvidjeli svi utjecaji – imitirao stvarni svijet – u raznim simulacijama, pokusima, igrama… Slučajnost i slučajni brojevi se tradicionalno koriste za razne svrhe. Naprimjer, igre na sreću tipa lota ili igre sa kockom (Čovječe ne ljuti se). Sa napretkom razvoja računala ljudi su uvidjeli značaj uvođenja slučajnosti u računalne programe. Makar to zvuči iznenađujuće računalu je prilično teško narediti da nešto napravi nasumično. Računalni prograni slijede instrukcije slijepo i kao takvi su nevjerovatno predvidljivi. Programeri i inžinjeri su uveli slučajnost u računala u formi generatora pseudoslučajnih brojeva. Kao što samo ime kaže pseudoslučajni brojevi nisu u potpunosti slučajni. Oni se računaju iz matematičkih formula ili se jednostavno uzimaju sa neke liste već unaprijed sastavljenih brojeva. Razvoj teorije pseudoslučajnih brojeva i algoritama za njihovo ostvarivanje je dosegao visoku razinu te su tako dobri da ti brojevi izgledaju isto kao da su stvarno slučajni. Pseudoslučajni brojevi imaju karakteristiku da su predvidljivi, što znači da se mogu predvidjeti ako znamo neke parametre tih brojeva, kao što je prvi broj. Za neke svrhe ovo je dobra karakteristika, ali negdje se ovo mora izbjegavati. Pseudoslučajni brojevi su dosta nezahvalno područije rada. S jedne strane zahtjevaju jako dobro poznavanje raznih matematičkih operacija i programiranja a sa druge strane imaju jako velik utjecaj na razna područija primjene, naročito na sigurnost kriptiranja raznih podataka. U ovom seminaru će se pokušati dotaknuti najvažnija područija gdje pseudoslučajni brojevi imaju utjecaj na sigurnost, no zbog ogromnosti primjene pseudoslučajnih brojeva neki aspekti nisu uvršteni u ovaj rad. Slučajni brojevi se koriste i u računalnim igrama ali se također koriste i za mnogo ozbiljniju svrhu – za generiranje kriptografskih ključeva, razne simulacije, te za neke vrste znanstvenih eksperimenata. Za znanstvene eksperimente pogodno je da se slučajni brojevi mogu ponoviti u više pokusa – pseudoslučajni brojevi su dobri za ove svrhe. Za kriptografske svrhe je važno da brojevi koji se kreiraju kao slučajni budu doista slučajni a ne da se samo takvima čine. Vrlo bitan vid korištenja pseudoslučajnih brojeva kojim će se ovaj rad najviše baviti jest u kriptografiji. Ako se želi ostvariti bilo kakva sigurna komunikacija, potreban je slučajno generiran ključ. U ovom slučaju kvaliteta generatora se očituje u nemogućnosti reprodukcije niza slučajnih brojeva, što onemogućuje eventualno olakšano dolaženje do ključa kojim se kriptiraju poruke. Slab generator u ovom slučaju može postati vrlo lako iskoristiva sigurnosna rupa. Iz svih ovih razloga, na generatore pseudoslučajnih brojeva se ne bi smjelo gledati kao na nešto malo značajno. Različite primjene zahtjevaju ogromne količine slučajnih brojeva, stoga njihova implementacija mora biti efikasna, brza i ne pretjerano složena, a opet generator mora biti dovoljno sakriven i složen da ga se nebi moglo iskorisiti kao sigurnostnu slabost o čemu će se više govoriti kasnije. Postoji relativno mnogo metoda za stvaranje pseudoslučajnih brojeva, ali odabir neke od metoda mora biti dobro promišljen, i dobro prilagođen onome što se od generatora traži. Naravno, ovisno o ozbiljnosti funkcije generatora, on mora biti manje ili više testiran na razne načine, da se njegove slabosti nebi pokazale tek preko loših rezultata u stvarnoj upotrebi. U ovom radu najviše važnosti će se posvetiti tome kako i u kojoj mjeri pseudoslučajni brojevi utječu na sigurnost. 2. Pseudoslučajni i slučajni brojeviNišta nije slučajno, samo je neizvjesno. Gail Gasram 2.1. Pseudoslučajni brojevi (uvod)Potreba za dobivanjem manje ili veće količine slučajnih brojeva inicirala je matematičare da pokušaju pomoću računala dobiti brojeve koji samo naizgled izgledaju slučajni, ali se zapravo dobivaju pomoću raznih formula ili algoritama. Taj postupak se u nekim slučajevima (ovisno o kvaliteti algoritma) može rekonstruirati, no bez poznavanja nekih parametara to je prilično zahtjevan zadatak. Svi generatori pseudoslučajnih brojeva se baziraju na rekurzivnim aritmetičkim i/ili logičkim formulama. Prilikom izračunavanja sljedećeg elementa niza slučajnih brojeva možemo se koristiti sa samo jednim ili sa više već izračunatih članova niza, a operacije nad njima mogu biti matematičke, ili ako se gledaju bitovni zapisi brojeva, logičke. Svaki takav generator zahtjeva neku početnu vrijednost, te još nekoliko parametara, koji onda služe kao koeficijenti ili kao konstante. Svaki generator pseudoslučajnih brojeva, nakon što ga se napravi, valja i dobro ispitati. Ispituju se svojstva perioda ponavljanja niza generiranih brojeva, uniformnost raspodjele brojeva unutar intervala, dok za potrebe simulacija valja znati kako su raspodjeljene n-torke dobivene od n uzastopnih brojeva iz nekog generatora, u n dimenzionalnom prostoru. Također, ako se može pronaći postojeći generator za kojeg se pouzdano zna da ispunjava zahtjeve, te je već korišten i testiran, bolje je primjeniti njega nego ići samostalno programirati novi generator, jer je za takav novi generator potrebno puno testiranja da bi se pokazala njegova primjenjivost. 2.2. Razni algoritmi generatora pseudoslučajnih brojeva2.2.1 Linearni generatori pseudoslučajnih brojeva (Linear congruential generator: LCG)Linearne generatore slučajnih brojeva (LCG) je smislio Lehmer 1948. Ovaj generator pseudoslučajnih brojeva se služi sljedećom rekurzijom: yn+1=ayn+b (mod m). Početni yo i ostali parametri se zadaju sa: LCG (m, a, b, yo). Klasični LCGoviANSIC LCG(231,1103515245,12345,12345) ANSIC je generator kojeg koristi ANSI c rand() funkcija, BSD verzija. Neke verzije UNIX-a u online priručniku netočno tvrde da je period generaotra 232. MINSTD LCG(231-1, a= 75 = 16807, 0, 1) RANDU LCG(231, 216 + 3 = 65539, 0, 1) SIMSCRIPT LCG(231-1,630360016, 0, 1) Implementirano u programskom jeziku za simulacije SIMSCRIPT II. BCSLIB LCG(235, 515,7261067085, 0) Implementirano u programskom jeziku SIMULA, te verzija sa modulom m=247 na CDC računalima. BCPL LCG(232, 2147001325, 715136305, 0) Ovaj generator se koristio u jeziku BCPL. URN12 LCG(231, 452807053, 0, 1) Ovaj generator se koristio u CUPL jeziku. Zanimljivost je da je 515 (mod 2)31 = 452807053, gdje je 515 m kod BCSLIBa. APPLE LCG(235, 513 = 1220703125, 0, 1) Implementirano na računalima APPLE. Super-Duper LCG (232, 69069, 0, 1) Ovaj generator je dio kombiniranog generator SUPER-DUPER (kombiniran sa generatorom pomicanja registara udesno). Ovaj LCG sam se ponekad naziva Super-Duper. Bio je implementiran na IBM računalima. HoaglinLCGs (Hoaglinovi LCGovi) LCG(231 – 1, a, 0, 1) a Î {1078318381, 1203248318, 397204094, 2027812808, 1323257245, 764261123} Ovi brojevi su rezultat studija koje je proveo Hoaglin, a imaju najbolje spektralne rezultate. FishmanLCGs (Fismanovi LCGovi) Parametri a navedeni u tablici određuju najboljih 5 LCGova u odnosu na m u analizama što su ih proveli Fishman i Moore.
Knuth–ovi i Borosh i Niederreiter-ovi LCGovi Ova lista 30 LCGova uključuje RANDU, BCSLIB, APPLE, Super-Duper i DERIVE. Ovi LCGovi su selektirani po različitim kriterijima.
Neki noviji LCGoviNAG LCG(259, 1313 , 0, 123456789(232 +1)) Ovo je osnovni generator pseudoslučajnih brojeva u mnogim distribucijama NAG Fortran biblioteka. DRAND48 LCG(248, 25214903917, 11, 0) DRAND48 je generator koji se koristi u ANSI C-u, funkcija drand48(). CRAY LCG(248, 44485709377909, 0, 1) Ovaj generator je implemetiran u CRAY sistemima, te se nalazi u PASCLIB-u, kolekciji potprograma koji se mogu pozvati iz Pascala na CD CYBER računalima. MAPLE LCG(1012 –11, 427419669081, 0, 1) Implementirano u matemačkom softwareu Maple. DERIVE LCG(232, 3141592653, 1, 0) CRAND LCG(m, a, 0, 1)
Ovi generatori su implementirani u raznim verzijama C-RANDa, paketa za generiranje neuniformnih random brojeva. L'EcuyerLCGovi Pierre L'Ecuyer koristi spektralne testove i Bayerove dijeljitelje da dobije dobre a za LCG(m,a,0,1) sa izabranim primarnim modulom m. L'Ecuyer je predložio sljedeće LCGove:
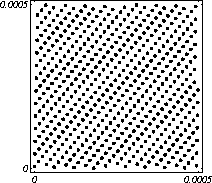
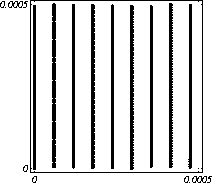
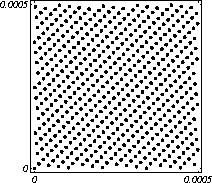
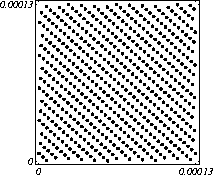
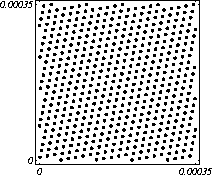
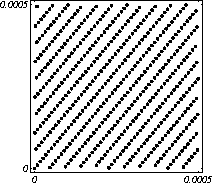
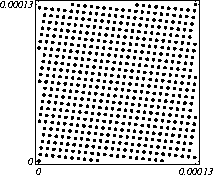
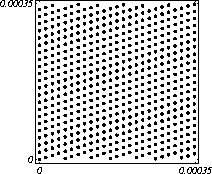
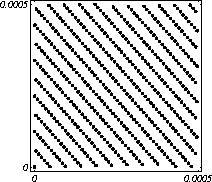
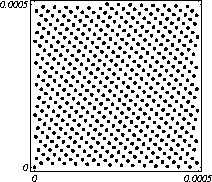
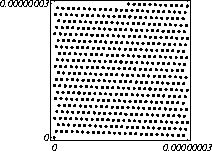
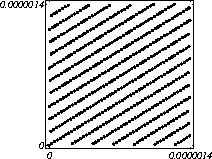
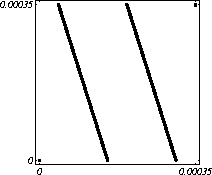
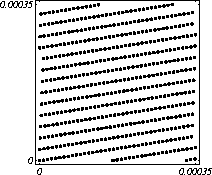
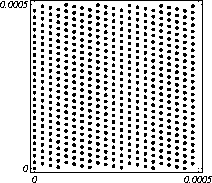
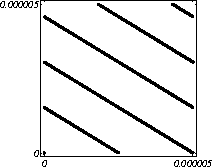
MATH LCG(m = a48 – a8 +1, a= 231, 0, 1) Implementiran u Mathematica-i. CARRY LCG(m = a24 – a10 +1, a= 224, 0, 1) 2.2.2 Kombinirani LCGovi (cLCG)Kombiniranjem različitih nizova (xn(j))n ³ 0, 1£ j £ r, koje dobivamo od raznih LCGova, možemo dobiti novi niz (xn)n ³ 0, xn = xn(j) + ... + xn(j) (mod 1), te time postižemo duže periode, a smanjujemo vrijeme izračuna. Wichman i Hill-ov cLCG Kombinacija 3 LCG-a: LCG(30269, 171, 0, 1) LCG(30307, 172, 0, 1) LCG(30323, 170, 0, 1) L'Ecuyer-ov cLCG Ovaj cLCG je ekvivalentan sljedećem LCG-u, a sastoji se od 13 LCGova lakših za računanje. LCG(32504802982957,30890646900944,0,1) NAG PVM Library (G05AAFP) – Clcg-oviNAG PVM (parallel virtual machine) Library Chapter G05 sadrži parametre za 273 kombinirana LCG-a, od 4 kombinirana LCG-a, primnjerice, prva kombinacija se sastoji od: LCG(16770647,125,0,1), LCG(16770643,117,0,1), LCG(16770623,127,0,1) and LCG(16770617,126,0,1). 2.2.3 Inverzivni generatoriInverzivni generatori pseudoslučajnih brojeva (Inversive Congruential Generators) (ICG) su djelo Eichenauera i Lehna (1986). Trebamo izabrati modul p, množitelj a, dodatni uvjet b i početnu vrijednost y0. Za zadani prirodni broj p, i za c Î Zp, c':= 0 ako je c=0, te c':=c-1 ako je c¹0. To znači da je c' jednako broju cp-2 (mod p). Sada možemo zadati jednakost: yn+1 = ay'n + b (mod p), n³0 da dobijemo pripadni niz pseudoslučajnih brojeva u {0, 1, … , p-1}. Zapis ovog generatora je: ICG(p, a, b, y0) Razlika u odnosu na LCG generatore je da u ICG generatorima nemamo strukture, brojevi se mogu nalaziti na bilo kojim mogućim mjestima, kao što je prikazano na donjoj slici, u regiji oko točke (0.5, 0.5). ICG (231 – 1, 1288490188, 1, 0) Eksplicitni inverzivni generatoriEksplicitni inverzivni generatori pseudoslučajnih brojeva (Explicit Inversive Congruential Generators) (EICG) je poboljšana verzija ICG-a, zapravo lakša za implementiranje u praksi. Cijena toga je manja maksimalna veličina uzorka. Zasluge su pobrali Eichenauer-Herrmann (1993). Izaberemo prirodni broj p, množitelj od a Î Zp, a ¹0, bÎ Zp, I početna vrijednost n0 u Zp. Tada imamo: yn=[a(n+n0)+b]' (mod p), n³0 I pripadni niz pseudoslučajnih brojeva u {0, 1, … , p-1}. Zapis: EICG(p, a, b, n0) Zanimljivo je da se isti pseudoslučajni niz može dobiti u dva zapisa: EICG(p, a, b, n0) EICG(p, a, 0,m0) ako je m0 = n0 + a'b (mod p). U večini slučajeva se stavlja b=0. Kombinirani generatoriEichenhauer-Herrmann (1993, 1994) su uveli jednostavnu tehniku kombiniranja inverzivnih generatora, kombinirajući ICG i EICG. 2.2.4 Kriptografski sigurni generatori pseudoslučajnih brojeva (bitova)Do sada prikazani generatori najčešću primjenu imaju pri generaciji slučajnih brojeva u svrhu računalne simulacije. U kriptografskim primjenama, međutim, potrebna je dodatna sigurnost. Naime pri generaciji slučajnih bitova koji služe kao ključevi, nužno je osigurati nepredvidivost brojeva u generiranom nizu. Ulaz u generator mora biti odabran tako da ga je praktički nemoguće otkriti bilo metodom pogađanja, bilo pretraživanjem svih mogućih kombinacija. Npr. ako se kao ulaz uzima vrijeme, ono mora biti što preciznije odabrano tj. potrebno je uzeti u obzir što je više moguće informacija o trenutnom vremenu (godina, mjesec, … , milisekunde). Dodatno, period generatora mora biti izuzetno velik. Time se postiže vrlo veliki broj različitih nizova koje je nemoguće pretraživati u konačnom vremenu. Ako je generator pažljivo konstruiran tako da generirani niz u sebi ne sadrži očite elemente pravilnosti, metoda predviđanja (pogađanja) niza je svedena na minimum. Dobiveni niz se tada može upotrijebiti npr. kao tajni ključ za slanje poruka. Sami algoritmi generatora su javno dostupni, ono što mora biti privatno za pojedinu kriptografsku aplikaciju je način izbora početnih uvjeta. Generator mora biti tako napravljen da je bez znanja početnih uvjeta nemoguće predvidjeti niz brojeva unatoč poznavanju algoritma. Važno je primjetiti da bi kriptografski sigurni generatori (CSPRBG – cryptographically secure pseudorandom bit generator) bili izuzetno korisni i u računalnim simulacijama jer općenito daju puno kvalitetnije nizove od standardnih generatora. Problem međutim leži u činjenici da su, zbog relativno složenih algoritama, bitno sporiji u odnosu na standardne generatore što ih čini nepogodnima za generaciju vrlo velikog broja podataka. Međutim, u kriptografskim primjenama je potrebno generirati mali broj podataka (tipično par desetaka ili stotina bitova) pa brzina izvođenja ne predstavlja veliki faktor pri izboru generatora. U nastavku će biti prikazana dva kriptografski sigurna generatora koji se temelje na DES i RSA algoritmima kriptiranja. Ideja je da se upotrebljava jednosmjerna funkcija f(s) koja se upotrebljava na nizu s,s1,s2,s3, … i daje niz f(s),f(s1),f(s2),f(s3), … U ovisnosti o tome koja se funkcija upotrebljava, iz izlaznog niza se zadržavaju samo određeni bitovi kako bi se eliminirala korelacija između uzastopnih elemenata u nizu. ANSI X9.17 generatorANSI X9.17 generator kao funkciju upotrebljava trostruko E-D-E kriptiranje sa dva ključa DES algoritmom. Trostruko E-D-E kriptiranje se definira na slijedeći način: E(x) = EK3(DK2(EK1(x))), gdje EK(x) označava kriptiranje uz pomoć ključa K, a DK(x) označava dekriptiranje uz pomoć ključa K. Ako se uzme da vrijedi: K1 = K3, tada je riječ o trostrukom E-D-E kriptiranju sa dva ključa. Ulazni podaci generatora su: slučajni 64-bitni podatak s (seed), cijeli broj m i ključevi kriptiranja K1 i K2. Algoritam se odvija prema slijedećim koracima: računa se pomoćna vrijednost I = E(D), gdje je D 64-bitni zapis trenutnog vremena za i = 1 do m računa se: xi = E(I XOR s) i s = E(xi XOR I) rezultat je niz 64-bitnih slučajnih brojeva x1, … ,xm Važno je napomenuti da za ovaj algoritam nije formalno dokazano da je kriptografski siguran. Međutim generator se pokazao upotrebljivim (dovoljno sigurnim) u većini primjena. Prednost ovog generatora u odnosu na dokazane kriptografski sigurne generatore je jednostavnija izvedba i bitno veća brzina. RSA generator pseudoslučajnih brojevaAlgoritam generatora se odvija prema slijedećim koracima: Potrebno je generirati dva velika prosta broja p i q te izračunati umnoške n = pq i L(n) = (p – 1)(q – 1). Nadalje je potrebno odabrati slučajni broj e, 1 < e < L(n), takav da vrijedi gcd(e,L(n)) = 1 (gcd je najveća zajednička mjera). Potrebno je odabrati slučajni cijeli broj x0 (seed) u intervalu [1, n - 1]. za i = 1 do l računa se: xi = xei-1 mod n i zi = najmanje značajni bit iz xi Dobiveni rezultat je niz slučajnih bitova z1, …, zn. Važno je primjetiti da se brojevi generiraju sporo (u odnosu na dosad prikazane generatore), zbog razloga što je potrebno računati potenciju velikog broja (tipično par stotina bitova) te ostatak dijeljenja sa velikim brojem (iste veličine) što naravno nije sklopovski podržano. Postoje određene metode koje donekle mogu ubrzati rad generatora uz minimalnu cijenu kvalitete niza (poboljšani generator ostaje i dalje kriptografski siguran u određenim uvjetima). Važno je međutim napomenuti da se svaki postupak optimizacije mora izvesti uz maksimalni oprez jer pojava korelacije među susjednim bitovima bitno povećava mogućnost provale. 2.3. Slučajni brojevi2.3.1 Sklopovski generatoriSlučajni brojevi su brojevi koji se dobivaju putem raznih sklopovskih kartica, koje onda, zavisno o utjecaju okoline generiraju potpuno slučajan niz bitova. Ovi brojevi nisu potpuno slučajni, oni u mnogome ovise o tome koji se okolni utjecaj uzima: varijacije u napajanju, atmosferski utjecaji, radio šum... Ti utjecaji koji mogu proizvesti ne tako slučajan niz brojeva se mogu anulirati ili izbaciti, ali ta tema će se dotaći kasnije. Sklopovski generatori sami po sebi su kartica koja proizvodi nasumičan niz bitova koji se ne mogu predvidjeti ni na koji način (za razliku od pseudoslučajnih brojeva). Uobičajna metoda je pojačavanje šuma koji dolazi sa otpornika (Johnsonov šum) ili sa poluvodičke diode, te odvođenje toga šuma na komparator ili Schmittov okidač. Diskretizacijom (ne prebrzom) izlaza dobivamo seriju bitova koji su međusobno nezavisni. Oni se onda mogu spojiti u bajtove, integere ili decimalne brojke, ovisno o namjeni. 2.3.2 Sklopovski generatori – praksa i problemiZanimljiv generator slučajnih brojeva se nalazi na internetu – random.org. Tamo se za generiranje slučajnih brojeva kao ulaz uzima atmosferski šum. Radio je namješten na frekvenciju gdje nitko ništa ne odašilje. Atmosferski šum se šalje kao ulaz u sunovu SPARC radnu stanicu kroz mikrofon gdje se samplira kao 8 bitni mono signal na frekvenciji od 8 KHz. Prvih 7 bita se odmah zanemaruje a preostali bit se šalje dalje da se ukloni statistička greška, tj. da u tom nizu bude približno jednak omjer nula i jedinica. Statističko uklanjanje grešaka se bazira na algoritmu mapiranja prijelaza (transition mapping). Čitaju se dva bita zajedno i ako postoji prijelaz između ta dva bita (dakle 01 ili 10) jedan od njih (svejedno koji, recimo prvi) prolazi kao slučajni. Ako nema prijelaza (bitovi su 00 ili 11) ovi bitovi se odbacuju. Ovaj algoritam je originalno osmislio Von Neumann i on u potpunosti uklanja bio kakvo preferiranje nula ili jedinica u podatcima. To je samo jedan od nekoliko načina na koji se uklanja statistička greška. Drugi načini su: parititet niza (stream parity), FFT (Fourierove transformacije) i kompresija. Ovaj site može biti koristan u slučaju da vam treba određeni broj slučajnih brojeva, u određenom rasponu, ali da se ti slučajno generirani brojevi mogu ponoviti (labaratorijski pokusi). Ispis se dobiva u txt dokumentu. Još jedna zanimljiva (ali beskorisna) stvar na tome site-u je i bacanje novčića, pa se onda s obzirom na valutu koju ste izabrali dobijete glavu ili rep novčića - naravno potpuno slučajno. Loto, tj. izvlačenje loptica iz bubnja je jedan od primjera slučajnih brojeva. No sam pokušaj simuliranja toga bubnja sa sobom nosi neke probleme, s kojima su se suočili organizatori Lutrije na Novom Zelandu, kada su pokušali uvesti računalnu simulaciju izvlačenja kuglica. Sam princip je bio jednostavan (propisan zakonom): 1. Vjerovatnost da se neki niz brojeva izvuče treba biti jednak vjerovatnosti kao da je izvlačenje vršeno pomoću bubnja; 2. Nitko (uključujući programere i osobe koje mogu vidjeti kod) ne bi smio biti u stanju predvidjeti brojeve koji će biti izvučeni; 3. Nitko ne bi smio biti u mogućnosti utjecati na ishod izvlačenja u svoju korist; 4. Kvalificirana osoba treba potvrditi da su prva tri uvjeta ispunjena. Ovi uvjeti su odmah izbacili pseudoslučajni generator, čak i kada se koristi algoritam sa slučajnim početnim brojem – imali bi na izbor samo 231 mogućih vrijednosti, te svaka kombinacija ne bi imala jednaku mogućnost da bude izabrana. No i sa pravim generatorom slučajnih brojeva bilo je teško dokazati da je uvjet pod 1 ispunjen, jer bi se trebalo dokazati da svaka kombinacija ima jednake teoretske mogućnosti izvlačenja. No, unatoč nemogućnosti dokazivanja da će to biti prava simulacija, organizatori su se zadovoljili sa statističkom odstupanjem od savršenstva od 10%. Ulaz se je uzimao sa sklopovskog generatora koji se pokazao najpouzdanijim, te je još prolazio kroz statističko uklanjanje greške i dvostruki Xor. Na kraju je jedina provjera bila provjera ispravnosti napisanog koda, dok su uvjeti 2 i 3 automatski bili zadovoljeni. George Marsaglia, guru u područiju slučajnih brojeva je izdao CD koji se sastoji od 600 megabajta slučajnih brojeva. Ti brojevi su nastali kombinacijom Georgeovog najboljeg generatora slučajnih brojeva koji je onda kombiniran sa pseudoslučajnim generatorima i drugim neovisnim izvorima (rap muzika). Pretpostavimo da su X i Y skupine neovisnih i slučajnih brojeva (između 0 i 255), te da je barem jedna grupa uniformno raspoređena na područiju od 0 do 255. Tada jednadžbe ekskluzivni-or X i Y, te X + Y mod 256 daju uniformnu raspodjelu na područiju 0 do 255. Ako su i X i Y uniformno raspoređeni tada će njihova kombinacija (na bilo koji od ova dva načina) biti bliže uniformnoj raspodjeli. Marsaglia je koristio XOR, a osnovna ideja mu je bila da razbije posljednje komadiće nekakvih uzoraka koji se mogu naći u bilo kojem nizu proizvedenom slučajno ili pseudoslučajno. Na tom CD-ROM-u imamo spojene
izlaze tri sklopovska generatora, od kojih niti jedan nije prošao diehard
test (v. testove), radi dva naizgled čudna razloga: jedan generator
je imao deklariranu brzinu diskretizacije koju sklopovlje nije mogao
podnjeti tako da je imao preveliku korelaciju susjednih brojeva; druga
dva generatora su imala programsku pogrešku u compileru koji je izlaz
zapisivao u binary file preko standardnog izlaza – a on je svaki put
nakon vrijednosti bytea 10 zapisivao 13 umjesto 10 a tek kao idući znak
10. Ovo je bila naizgled čudna greška, ali poznata je svakome tko je
ikada radio sa ASCII vrijednostima znakova: Gore naveden primjer je samo upozorenje da svaki, pa čak i najhvaljeniji generator mora biti testiran, želimo li imati brojeve u potpunosti slučajne. Potpuno slučajni brojevi se mogu dobivati na mnogo načina, od interesantnijih bih spomenio generator slučajnih brojeva koji uzima ulaz sa kamere koja snima vulkansku tekuću lavu (kasnije je ustanovljeno da se još bolji rezultati postižu sa "čistim" elektronskim šumom). No najupotrebljavaniji su svakako sklopovski generatori u obliku kartice, opisani prije. No, makar se čini jednostavnim napraviti slučajne brojeve uz pomoć ovakvih naprava potreban je velik trud i znanje da se napravi "čisti" kaos. A u svijetu gdje je manje više sve kaotično to se čini uzaludnim, kao da u pustinji prodajete pijesak. Ali kao što se pijesak da prosijati i skupo prodati, isto tako se i kaos koji dobivamo iz kakafonije današnjeg svijeta može pročistiti. Ali pitanje je: kako znati koji kaos je pravi, kako znati koji brojevi su doista slučajni, a koji samo tako izgledaju? Odgovor na to pitanje daju nam testovi koji prepoznaju razne elemente nasumičnosti, no više o tome će biti rečeno u slijedećem poglavlju gdje će se govoriti o utjecaju slučajnih brojeva na sigurnost. 2.3.3 Korištenje postojećeg sklopovljaKorištenje zvučne/video karticeGotovo sva današnja računala imaju neku vrstu ulaza koji digitaliziraju analogni signal, kao što je recimo zvuk sa mikrofona ili video ulaz sa kamere. Pod odgovarajućim okolnostima ovakav unos može proizvesti zadovoljavajuću kvalitetu slučajnih brojeva. Ulaz kada u zvučnu ili video karticu nije utaknut niti jedan uređaj, naravno pod uvjetom da sustav uspije prepoznati nešto, je uobičajeno poznat pod nazivom termički šum. Taj ulaz je naravno slučajni šum, ali se on mora pročistiti od statističke greške. To se može napraviti na dva načina, jedan od njih je već opisan u prethodnom poglavlju, a drugi bi bio kompresija podataka. U UNIX-u bi se to moglo jednostavno napraviti, ako imamo zvučnu karticu i nemamo mikrofon uključen, sljedećom naredbom: cat /dev/audio | compress -> random_bits_file Korištenje tvrdih diskovaTvrdi diskovi imaju male slučajne fluktuacije u svojim rotacijama zbog kaotičnih zračnih turbulencija. Dodavanjem instrumenta koji bi mjerio vrijeme traženja na disku, mogla bi se obaviti serija mjerenja koja bi uključivala ove slučajnosti. Ovakvi podaci su uobičajeno jako povezani, tako da bi trebalo značajno procesiranje pdoataka, uključujući FFT ili slični algoritam uklanjanja korelacija. Pokusi koji su vršeni na diskovima su pokazali da se na ovaj način (ipak) može dobiti 100 ili više bitova u minuti odličnih slučajnih brojeva. Još jedna dobra stvar je da ako dođe do greške u radu diska kvar će biti jako brzo uočen. To znači da bi generator brojeva koji bi radio na ovaj način bio jako pouzdan, ne bi nastajali problemi zbog grešaka u sklopovlju. 2.3.4 Koliko dobar mora biti sklopovski generator?Na pitanje koje je zadano
u naslovu nema preciznog odgovora. Sklopovski generator može biti savršeno
dobar u smislu da generira potpuno slučajne brojeve, dok s druge strane
može biti spor. Ili može biti jako brz, ali ne izbacuje baš savršeno
slučajne brojeve. Za same igre na sreću potrebno je imati prilično siguran algoritam slučajnosti – da nitko ne može iskoristiti potencijalne nesavršenosti u svoju korist. Brzina nije nužna. Ono što nam je još potrebno je da i u slučaju otkazivanja sklopovskog generatora sistem nastavi raditi, te se u većini kasina koristi kombinacija pseudoslučajnog generatora sa sklopovskim generatorom. Korištenje sklopovskog generatora u simulacijama je vjerovatno pretjerivanje jer se ne zahtjeva tolika slučajnost, a s druge strane najbrže sklopovske kartice ne preporučuju diskretizaciju više od 20000 puta u sekundi, što je daleko presporo za bilo koju praktičnu računalnu simulaciju. Rješenje bi se moglo napraviti tako da se ovakva kartica umetne u neko starije računalo i recimo jedan dan zapisuje izlaz iz generatora na disk. Na ovaj način bi se moglo generirati 1 –2 GB dnevno koji bi se mogli čitati pri potrebi. Za enkripciju nam je recimo potreban ključ od 256 bitova. Korištenje pseudoslučajnog generatora nije preporučljivo, naročito ako uljez ima pristup kodu programa. Razumno bi bilo koristiti sklopovski generator slučajnih brojeva. No, s druge strane, ne bi bilo razumno kupovati dodatni komad sklopovlja samo radi generiranja par ključeva. Isplativost takve investicije je sasvim razumna ako trebamo neke podatke sačuvati pod svaku cijenu, naročito ako ne želimo pomoći provalniku u naš sistem tako da mu suzimo izbor razbijanja ključa na najvjerovatnije vrijednosti. 3. Utjecaj na sigurnost"Pogrešni koraci su isto toliko važni koliko i ispravni. Ponekad čak i važniji." Richard Bach3.1. OsnoveVjerovatno najčešći zahtjev za nekom slučajnošću, a da ima utjecaj na sigurnost, s kojom se korisnici susreću je šifra (password). Uobičajeno je to neki string, sa možda dodanim brojkama ili specijalnim znakovima. Naravno, ako se šifra može pogoditi ne pruža neku sigurnost. Za šifre koje se višekratno koriste korisno bi bilo i da su pamtljive. U tom slučaju se koriste izgovorljivi znakovi u kombinaciji sa riječima ili dijelovima riječi. Ali ovo je samo zahtjev koji utječe na format šifre, ne i zahtjev da šifra bude teška za pogoditi. Mnogi drugi zahtjevi dolaze iz kriptografskih krugova. Kriptografija se koristi da osigura razne usluge koje uključuju povjerljivost i autentifikaciju. Takve usluge se temelje na velikom broju brojeva – ključevima (keys) koji su nepoznati i teški za pogoditi nepozvanim osobama. U nekim slučajevima, kao u slučajevima simetrične enkripcije kao što su OTP (one time pads) ili DES (US Data Encription Standard), strane koje žele komunicirati sigurno, sa ili bez autentifikacije, trebaju znati isti ključ. U drugim slučajevima koristeći asimetričnu kriptografiju ili kriptografiju javnog ključa trebamo imati parove ključeva. Jedan ključ je privatan i nitko ga ne smije imati osim one strane čiji je to kluč. Drugi ključ je javni i cijeli svijet ga smije vidjeti. Nemoguće je izračunati tajni ključ iz javnog ključa. Učestalost zahtjeva za slučajnim brojevima i njihova količina s u ovisnosti o kriptografskom sustavu. Koristeći RSA brojevi se zahtjevaju svaki put kada se generira par ključeva, ali poslije toga ne treba generirati nove ključeve za nove poruke. DSA pak zahtjeva potpuno slučajne brojeve za zvaki potpis. Enkripcija koja se vrši sa OTP, u principu najjača moguća enkripcija koja postoji, zahtjeva veliki broj slučajnih brojeva za svaku poruku koja se prosljeđuje. U večini slučajeva pokušaj probijanja šifre će se pokušati izvršiti metodom pokušaja i pogrešaka (poznat i kao brute force attack). Na ovaj način je moguće probiti šifru samo ako je ključ dovoljno manji od poruke tako da se ključ može identificirati. Vjerovatnost da će uljez na ovaj način uspjeti mora biti prihvatljivo mala, ovisno o aplikaciji i važnosti poruke. Ta vjerovatnost ovisi o broju raznih tajnih vrijednosti i vjerovatnosti svake od tih vrijednosti. No puno veća opasnost od brute force attacka je loše napravljen generator slučajnih brojeva koji onda može postati sigurnosna rupa. 3.2. Pogrešni pristupi3.2.1 Sistemski sat i serijski brojeviSistemski sat ili slični sklopovi pružaju puno manje slučajnosti nego što bi se moglo predvidjeti iz njihovih specifikacija. Testovi koji su rađeni na satovima unutar raznih sistema pokazali su da im ponašanje varira u raznim pravcima. Jedna verzija OS-a koja radi na nekom sistemu može pokazati točno vrijeme unutar milisekunde, dok drugi OS može gubiti zadnje bitove sistemskog sata. To bi značilo da par uzastopnih čitanja sata daje identične vrijednosti, čak i ako je prošlo dovoljno vrmena tako da bi se vrijednost trebala promjeniti – po sklopovskim specifikacijama. Zabilježeni su i slučajevi da je često čitanje sistemskog sata proizvelo umjetne sekvencijalne vrijednosti zbog programskog koda koji provjerava da li je sat promjenio vrijednost između čitanja i onda je tu vrijednost povečavao za jedan! Pravljenje programskog koda koji bi bio portabilan na raznim sistemima i koji bi uspješno čitao sistemski sat je veliki izazov, naročito što programeri uobičajeno ne znaju postavke sistemskog sata na kojem će program raditi. Korištenje sklopovskih serijskih brojeva, kao što je recimo Ethernetska adresa je visoko rizično jer su količine takvih brojeva uobičajeno ograničene na vrlo malom opsegu. Problemi koje sam opisao u korištenju sistemskih satova kao generatora slučajnih brojeva se povečavaju sa nepoznavanjem platforme, OS-a; s druge strane hakeri dobivaju prednost ako dobiju podatak kada je takav broj napravljen (vrijeme i datum), te ako imaju uvid u kod. 3.2.2 Timeri i sadržaji vanjskih događajaMoguće je mjeriti razmak između nekih vanjskih događaja (timeri) i sadržaj tih događaja, kao što bi recimo bilo kretanje miša, rad na tipkovnici i slični događaji. Ovo je razumno koristiti jer su ovakvi događaji naizgled nepredvidivi. Na nekim strojevima se ovakvi događaju stavljaju u buffer te samim time nisu pogodni za ovaj način stvaranja slučajnih brojeva. Također varijacije kod ovakvih događaja nisu u opsegu u kojem bi bilo moguće jednostavno napraviti generator slučajnosti. Još jedan problem je u tome što ne postoji standardizirani način mjerenja vremena između događaja (prethodni odlomak). Sve ovo otežava proizvodnju nekog standardnog software-a koji bi se mogao distribuirati raznim korisnicima. Također, količina pokreta miša i udaraca na tipkovnicu je jedna vrsta nepredvidivosti koju je lakše isprogramirati nego timere događaja, ali zbog prirode svoga unosa mogu biti puno repetitivniji nego stvarna nepredvidivost. Neki drugi događaji bi se također mogli koristiti, kao recimo vremena između dolaska mrežnih paketa, ali mogućnost manipulacije ovim ulazima je prevelika. 3.2.3 Kompleksne manipulacijeJedna strategija koja bi mogla zavarati i navesti nas da mislimo da se radi o slučajnosti bi bio neki vrlo složeni algoritam koji proizvodi naizgled slučajne brojeve (ili recimo pseudoslučajni genearator koji ima odlične karakteristike) za izračun ključa, tako da uzima recimo sistemsko vrijeme za početni slučajni broj (eng. seed). Na taj način bi se moglo generirati jako puno pseudoslučajnih brojeva koji bi stvarno bili teški za pogoditi, ali početni uvjeti su u biti vrlo klimavi i haker ne bi imao težak posao da pretraži relativno mali broj početnih uvjeta. Složenost algoritma i razni i/ili uvjeti koji kodiraju podatke neće biti puno od pomoći ako uljez može naučiti koji je to algoritam jednostavnim nalaženjem ključa. Čak i ako ne pogodi algoritam uljez može iskoristiti mali broj početnih vrijednosti, koji razultiraju malim brojem novonastalih slučajnih brojeva, u svrhu micanja kriptiranja ili provala u sistem. Još jedna ozbiljna greška je pretpostavka da složeni generator pseudoslučajnih brojeva može proizvesti slučajne brojeve ako iza toga algoritma ne stoji teorija, analize i testovi toga algoritma. Odličan primjer za tu dogmu se nalazi knjizi "TheArt of Computer Programming" Donalda E. Knutha, gdje autor opisuje jedan kompleksni algoritam za koji osoba koja bi pokušala čitati kod bez komentara ne bi uspjela odgonetnuti algoritam. Na žalost, algoritam je pokazao slabost da u jednom slučaju konvergira prema jednoj brojci, a u drugom slučaju se vrti u krug. Zaključak: ne samo da kompleksni algoritmi ne mogu pomoći ako nemamo dobre početne uvjete (seeds), nego se i dobri početni uvjeti mogu uništiti sa slijepo odabranim kompleksnim algoritmom. 3.2.4 Uzimanje podataka iz velike bazeJoš jedna strategija koja daje izgled nepredvidljivosti je selekcija neke količine slučajno odabranih podataka iz velike baze podataka i pretpostaviti da je slučajnost odabira podataka jednaka totalnom broju bitova u toj bazi. Recimo, tipični USENET serveri dobivaju 35 Mb podataka dnevno, recimo da iz tih podataka slučajnim odabirom izvučemo 32 bytea slučajnih podataka. No to ne znači da smo dobili 32*8=256 bitova slučajnih brojeva, jer čak i dopuštajući da se nisu uzimali podaci iz ograničenih znakova alfabeta, to je nakon micanja raznih statističkih grešaka i ponavljajućih znakova 2 do 3 bita korisnih i slučajnih podataka po byteu. Dakle, imamo 2.5*32= 80 bitova koji su slučajni. Ali ako pretpostavimo da uljez ima pristup istim podacima (dakle, onih 35 Mb USENET servera), onda u najboljem slučaju možemo dobiti 25 bita nepredvidivih podataka (za usporedbu jedan prosječni ključ sadrži 56 – 256 bitova). Isti argumenti se mogu upotrijebiti za bilo koji takav izvor slučajnih podataka, kao recimo CD ROM, audio CD ili bilo koja velika javna baza podataka. Ako uljez ima pristup istom tom izvoru, "velika baza podataka" nam vrlo malo donosi. Ako se pak radi o nekoj bazi do koje uljez nema pristup (server, multikorisničko računalo), onda ovaj pristup može donesti koristi. 3.3. Standardi generiranja ključevaPostoji više standarda za generiranje ključeva koji se danas koriste. Ispod sam opisao dva standarda. 3.3.1 US DoD preporuke za generiranje šifriUS DoD (The United States Department of Defense) ima specifične preporuke za generiranje šifri. Oni preporučuju korištenje DES-a (US Data Encryption Standard) u izlaznom povratnom modu (Output Feedback Mode) kako slijedi: Upotrijebiti inicijalizacijski vektor iz Šifra se onda može izračunati iz 64 bita "kodiranog teksta" koji se dobije kao izlaz u 64-bitnom ilaznom povratnom modu (64-bit Output Feedback Mode). Šifra se može onda proširiti tako da se dobiju izgovorljive riječi, fraze ili drugi formati u slučaju da ljudski korisnik treba zapamtiti šifru. 3.3.2 X9.17 generator ključaANSI (The American National Standards Institute) je specificirao metodu generiranja ključeva: s je početnih 64 bita slučajnih brojeva g je sekvenca od generiranih 64 bita u koraku n k je slučajni ključ rezerviran za generiranje ovog niza ključeva t je vrijeme u kojem se generira dobar ključ, koliko je potrebno (do 64 bita). DES ( K, Q ) je DES enkripcija velikog broja Q sa ključem K gn = DES ( k, DES ( k, t ) .xor. sn ) sn+1 = DES ( k, DES ( k, t ) .xor. gn ) Ako koristimo gn kao DES ključ, tada se svaki osmi bit treba podesiti da bude paritet, ali samo za tu svrhu, dok bi originalnih 64 bita g ostalo nepromjenjeno za izračunavanje slijedećeg broja s. 3.4. TestoviPod pojmom ispitivanja generatora, misli se na ispitivanje kvalitete generiranog niza. Pri ispitivanju se želi ustanoviti pokazuje li generirani niz ili ne neke poželjne karakteristike (npr. nedostatak pravilnosti u nizu, ispravna distribucija brojeva i sl.). Cilj ispitivanja je iz beskonačnog skupa testova (tj. beskonačnog skupa karakteristika niza) izvući bitne testove. Postoji mnoštvo različitih skupova testova, ali niti jedan ne može proglasiti niz generiranih brojeva “slučajnim”, moguće je samo zaključiti pokazuje li niz neka od ponašanja koja bi pokazao niz generiran od strane idealnog generatora (idealni generator je npr. čovjek koji baca potpuno simetrični novčić). Nasuprot tome, na temelju rezultata se može sigurno zaključiti da neki niz nije slučajan tj. da generator radi neispravno. Npr. ako generator generira niz u kojem su svi brojevi isti, očito je da se ne radi o slučajnim brojevima. Osnova za ispitivanje je statistički test tvrdnje. Prije ispitivanja, postavlja se nulta tvrdnja (H0) te alternativna tvrdnja (Ha). Pri ispitivanju generatora slučajnih brojeva, tvrdnje imaju slijedeći oblik: H0: niz koji se ispituje je niz slučajnih brojeva Ha: niz koji se ispituje nije niz slučajnih brojeva Za svaki ispit potrebno je odrediti statističku vrijednost koja se ispituje tj. vrijednost pomoću koje se odlučuje koja od tvrdnji se prihvaća kao istinita (uvijek se prihvaća točno jedna od navedenih tvrdnji). Nakon toga, potrebno je teoretski, matematičkim postupcima, odrediti očekivani rezultat nulte tvrdnje u uvjetima normalne, referentne raspodjele. Nakon toga se određuje kritična vrijednost za koju se ne očekuje da će se premašiti u uvjetima normalne raspodjele (tj. mala je vjerojatnost da će se dogoditi taj slučaj). Konačno, na temelju generiranog niza se računa tražena statistička vrijednost. Ako mjerena vrijednost prelazi teoretski određen prag, može se sa određenom sigurnošću reći da generirani niz nije niz slučajnih brojeva (prihvaćanje Ha). Vrijedi i obratno tj. ako mjerena vrijednost ne prelazi određeni prag, moguće je sa određenom sigurnošću prihvatiti H0. Mjera sigurnosti s kojom se generator prihvaća ili ne prihvaća kao ispravan se naziva nivo značaja a . Ako je a prevelik, ispitivanje može odbaciti niz koji u stvarnosti je niz slučajnih brojeva. Obratno, ako je a premali, ispitivanje može prihvatiti niz koji u stvarnosti nije niz slučajnih brojeva. Tipično se vrijednost a uzima između 0.001 i 0.05. U ovdje spomenutim ispitivanjima, a će iznositi 0.01 (tipično za kriptografske primjene). To znači da se niz može prihvatiti ili odbaciti sa 99% sigurnosti ili drugim riječima, rezultat ispita će dovesti do krivog zaključka u 1% slučajeva (pod ovime se ne misli da će od sto ispitivanja istog niza jedno ispitivanje dati pogrešan rezultat, nego da će se pogrešan zaključak izvesti nad jednim od sto mogućih kombinacija niza slučajnih brojeva). Tipično se u ispitima upotrebljavaju dvije standardne raspodjele: normalna raspodjela (očekivana raspodjela promatranih vrijednosti u nekom prostoru) te c 2 raspodjela (očekivana raspodjela učestalosti pojave nekih događaja). Ako ispitani niz nije niz slučajnih brojeva, mjerena statistička vrijednost ispita će se nalaziti u ekstremnim dijelovima krivulje (veličina tih dijelova ovisi o odabranoj vrijednosti a ). Odabir raspodjele ovisi o karakteristici koja se ispituje, a dodatno je u posebnim ispitivanja moguće uzeti i neku drugu raspodjelu. Sam tijek ispitivanja zahtjeva generiranje velikog niza brojeva (barem 103 brojeva u nizu, a tipično oko 106 brojeva). Važno je istaknuti da svaki ispit mjeri neku od poželjnih karakteristika slučajnih brojeva (npr. ravnomjerna raspodjela brojeva u prostoru). Nakon serije ispitivanja u najboljem slučaju moguće je zaključiti da ispitivani generator posjeduje željena svojstva te da bi mogao biti dobar generator slučajnih brojeva (čak i tako neodređen zaključak se može izvući sa 99% sigurnosti). S druge strane moguće je zaključiti da ispitivani generator nije odgovarajući (također sa 99% sigurnosti). Poželjno je nakon provedene serije statističkih ispita izvršiti dodatna eksperimentalna ispitivanja. Tipični primjer je upotreba generatora u simulaciji čiji rezultati se mogu a priori teoretski odrediti: simulacijom se računa neka vrijednost te se uspoređuje sa izračunatom teoretskom vrijednosti. 3.4.1 NIST testoviOvo je skup ispita koju preporučuje NIST (National Institute of Standards and Technology). Algoritmi za pojedine ispite su navedeni u odgovarajućoj NIST dokumentaciji zajedno sa pripadnim formalnim matematičkim izvodim te ovdje neće biti prikazani. Nivo značaja u svim ispitima iznosi 0.01, a poželjno je da se niz sastoji od barem 100 brojeva. Svi ispiti se vrše nad nizom bitova, ali izvedeni zaključci se normalno mogu primjeniti za generator slučajnih brojeva. Već je ranije spomenuto da se generator slučajnih brojeva dobije jednostavnim grupiranjem više bitova iz niza slučajnih bitova. Ispitivanje učestalosti u nizuPromatrana karakteristika u ovom ispitu je odnos jedinica i nula u nizu bitova. Svrha je uočiti da li je u promatranom ispitu približno jednak broj jedinica i nula. Naravno, za očekivati je da kvalitetni generator slučajnih bitova daje približno jednak broj jedinica i nula. Sva druga ispitivanja ovise o prolazu ovog ispita. Može se reći da je prolaz ovog ispita nužan, ali ne i dovoljan uvjet za donošenje zaključka radi li se o nizu slučajnih bitova ili ne. Ispitivanje učestalosti u blokuPromatrana karakteristika u ovom ispitu je odnos jedinica i nula u M-bitnim blokovima u nizu. Svrha je uočiti je li broj jedinica i nula podjednak u svakom M-bitnom bloku. Za blok veličine M=1 ovaj ispit se pretvara u ispit učestalosti u nizu. Ispitivanje uzastopnih ponavljanja istih bitova u nizuPromatrana karakteristika u ovom ispitu je ukupni broj uzastopnih ponavljanja jednog broja u niz. Uzastopno ponavljanje je pojava dva ili više istih brojeva za redom. Svrha je uočiti da li se broj uzastopnih ponavljanja sa očekivanim brojem koji bi bio u savršeno slučajnom nizu Ispitivanje najdužeg uzastopnog ponavljanja jedinica u blokuPromatrana karakteristika u ovom ispitu je najduže uzastopno ponavljanje jedinica u M-bitnim blokovima. Svrha je odrediti da li se dužina najdužeg uzastopnog ponavljanja poklapa sa dužinom koja bi se očekivala u nizu slučajnih bitova. Nepravilnost u dužini najdužeg uzastopnog ponavljanja jedinica u bloku povlači za sobom i nepravilnost u dužini najdužeg uzastopnog ponavljanja nula u bloku, pa nije potrebno obaviti posebno ispitivanje za ponavljanje nula u M bitnim blokovima. Veličina bloka M se bira u ovisnosti o veličini niza n, prema tablici koju preporučuje NIST. Ispitivanje ranga matricePromatrana karakteristika u ovom ispitu je rang matrica koje se dobiju iz podniza ispitivanog niza. Namjera je ustanoviti postoji li linearna ovisnost između podnizova fiksne duljine u ispitivanom nizu. Spektralno ispitivanjePromatrana karakteristika u ovom ispitu su amplitude u diskretnoj Fourierovoj transformaciji promatranog niza. Svrha ispita je otkrivanje periodičkih pojava u promatranom nizu (ponavljajući uzorci koji su međusobno “previše blizu”) koje bi ukazale na odstupanja od niza slučajnih bitova. Ispitivanje ponavljanja predloška u generiranom nizuPromatrana karakteristika u ovom ispitu je broj ponavljanja unaprijed određenog niza bitova (predloška) u generiranom nizu. Preveliki broj ponavljanja predloška ukazuje na pravilnost u generiranom nizu bitova, te potencijalno lošu distribuciju brojeva koji se dobiju grupiranjem bitova (kada se želi ostvariti niz slučajnih brojeva). Ispit se javlja u dvije varijante: sa preklapanjem (overlapping) i bez preklapanja (non-overlapping). U varijanti sa preklapanjem, dopušteno je da se uzorci međusobno preklapaju (npr. broj ponavljanja predloška 101 u nizu 1010101 iznosi tri). Obratno, u varijanti bez preklapanja to nije dopušteno (za isti primjer, broj ponavljanja iznosi dva: 1010101). Maurerov univerzalni statistički testPromatrana karakteristika u ovom ispitu je broj bitova između istih uzoraka (mjera koja određuje koliko se niz može komprimirati). Svrha ispita je ispitati da li se promatrani niz može značajno komprimirati bez gubitaka informacije. Za niz koji se može značajno komprimirati smatra se da nije niz slučajnih bitova zbog činjenice da je kompresija niza (bez gubitaka) efikasnija ukoliko niz pokazuje periodička svojstva, Ispitivanje na temelju Lempel-Ziv kompresijePromatrana karakteristika u ovom ispitu je broj različitih uzoraka (riječi) u ispitivanom nizu na temelju koje se određuje može li se niz značajnije komprimirati ili ne. Ispitivanje linearne složenostiPromatrana karakteristika u ovom ispitu je veličina posmačnog registra s povratnom vezom. Ispitivani niz se dijeli na blokove te se za svaki M-bitni blok računa minimalna veličina posmačnog registra s povratnom vezom koji generira sve bitove u tom bloku. Za niz slučajnih bitova se očekuju veće veličine posmačnog registra s povratnom vezom. Ispitivanje preklapajućih uzorakaPromatrana karakteristika u ovom ispitu je učestalost pojave svih mogućih m-bitnih uzoraka (uz preklapanje) u cijelom ispitivanom nizu. Namjera je otkriti da li je broj pojava 2m m-bitnih preklapajućih uzoraka približno jednak broju koji se očekuje za niz slučajnih brojeva. Niz slučajnih brojeva bi trebao imati ravnomjernu raspodjelu, tj. očekuje se da je vjerojatnost pojave svih m-bitnih uzoraka jednaka. Za m=1 ovaj ispit prelazi u ispit učestalosti u nizu. Ispitivanje približne entropijePromatrana karakteristika u ovom ispitu je također učestalost pojave svih mogućih preklapajućih m-bitnih uzoraka u nizu. Namjera je usporediti učestalost preklapajućih blokova susjednih veličina (m-bitni i m+1-bitni blok) sa očekivanim rezultatima. Ispitivanje kumulativne sumePromatrana karakteristika u ovom ispitu je najveće odstupanje od nule kumulativne koja se dobije postepenim zbrajanjem članova modificiranog niza. Modificirani niz dobije se tako da sve nule u ispitivanom nizu poprime vrijednost -1. Namjera je ustanoviti je li najveće odstupanje preveliko ili premalo u odnosu na očekivano. Ispitivanje slučajnog hodaSlučajni hod na temelju kumulativne sume dobije se nakon što se sve nule u nizu zamijene sa vrijednosti –1. Prolaskom kroz bitove promatranog niza računa se suma. Trenutna vrijednost u nekom koraku označava stanje. Ciklus u slučajnom hodu sastoji se od niza koraka koji počinju i završavaju na istom mjestu. Korak je u stvari promjena sume za +/- 1 pri računanju sume za sljedeći bit u nizu. Svrha ispita je odrediti da li broj “posjeta” svakom stanju u jednom ciklusu značajno odstupa od očekivanog broja za niz slučajnih bitova. Dodatna varijanta ovog ispita za karakteristiku uzima broj koliko je neko stanje posjećeno u slučajnom hodu kroz cijeli niz (a ne kroz ciklus). 3.4.2 DiehardOvo je skup testova koji analiziraju da li je datoteka sastavljena od slučajnih brojeva. DieHard je dizajnirao George Marsaglia (već spomenut u ovome dokumentu). Ovi testovi imaju rezultate, takozvane p-vrijednosti koje imaju rang od 0 do gotovo 1. Testovi koji se nalaze u ovom programu su sljedeći: Razmak između rođendana (Birthday Spacings); ponavljajuće permutacije (Overlapping Permutations); pozicije matrica 31x31 i 32x32 (Ranks of 31x31 and 32x32 matrices); pozicije matrica 6x8 (Ranks of 6x8 Matrices); test ponavljanja na 20-bitnoj riječi (Monkey Tests on 20-bit Words); test ponavljanja OPSO (riječi od 2 slova u abecedi od 1024),OQSO (riječi od 4 slova u abecedi od 32),DNA (riječi od 10 slova u abecedi od 4 riječi - C,G,A,T) (Monkey Tests OPSO,OQSO,DNA); broj jedinica u nizu bitova (Count the 1`s in a Stream of Bytes); broj jedinica u segmentiranom nizu (Count the 1`s in Specific Bytes); test parkirališta (Parking Lot Test); test minimalne udaljenosti (Minimum Distance Test); test slučajnih sfera (Random Spheres Test); test stiskanja (The Sqeeze Test); test preklapajućih suma (Overlapping Sums Test); test smjera (Runs Test); test igre s dvije kocke (The Craps Test). Samo opisivanje rada svakog od ovih testova bi oduzelo otprilike pola stranice po testu, a to nije baš zgodno. Večina testova dieharda vraća p vrijednosti koji bi trebali biti uniformno raspoređeni, no čak i ako kao izlaz dobijemo neku vrijednost blizu 0 ili 1 to ne znači da naš generator ili slučajni niz ne valja. Kada se "p" dogodi 6 ili više puta, to znači da naš generator ne valja. Kada se "dogodi p" to znači da je p < .025 ili p> .975, ali treba zadržati na umu da se "p" može dogoditi svakom nizu. 3.4.3 Spektralni testoviU poglavlju u kojem se opisuju razni algoritmi generiranja pseudoslučajnih brojeva kod svakog algoritma stoji slika spektralnog testa za taj određeni algoritam. Spektralni test se može primjeniti na algoritme koji imaju n-dimenzionalne vektore (na algoritme u kojima n prethodnih rezultata daje slijedeći). Spektralni test uobičajeno daje nekakav uzorak (lattice structure). Kako izračunati spektralni test? Večina algoritama se zasniva na dvodimenzionalnom uzorku koji se izvlači iz Ls, Ls ={xn = (xn, …, xn+s-1) : n >= 0}. Maksimalna udaljenost d je najkraći vektor između dva uzorka. Postoje razni algoritmi kako izračunati najkraći vektor. Također se onda izračunava normalni spektralni vektor Ss := ds*/ds, gdje je 0 <= Ss <= 1. Konstanta ds* je apsolutna donja granica za ds i bazira se na Hermitovim konstantama za s<=8. Jednostavni primjer: Uzmimo "mali" LCG(256,a,1,0) sa a = 85, 101, 61, 237. Ovi LCGovi daju spektralne testove d2 =0.3162, 0.1162, 0.0790, 0.0632 i normalizirane spektralne testove S2 =0.1839, 0.5003, 0.7357, 0.9196 u dimenziji s=2. 4. Zaključak"Nemoguće je predvidjeti nepredvidivo." U ovom radu sigurno nije rečeno sve što se odnosi na sigurnost ili nesigurnost koji osiguravaju slučajni brojevi. Najvažnije teme su dotaknute, te je time olakšan posao svakome kome treba pouzdan, brz ili neki drugi generator slučajnih brojeva. Sam rad na nekom novom generatoru slučajnih brojeva bio bi "otkrivanje tople vode". Generirati slučajne brojeve je užasno lako, ali dokazati da su to istinski slučajni brojevi koji imaju svoju primjenu je puno teže. Testovi opisani u ovom radu olakšavaju taj posao. Testovi su uglavnom besplatni i dostupni javnosti. Primjene slučajnih brojeva su velike, zahtjevi za njima rastu svaki dan. Od generatora slučajnih brojeva se zahtjeva sve veća slučajnost, sve više slučajnih brojeva. Kao i u životu, i kod slučajnih generatora teško je dobiti "i ovce i novce", ili u ovom slučaju i slučajnost i količinu. Brojevi koji trebaju biti što slučajniji ne mogu se proizvesti u velikim količinama (barem ne u kratkom vremenu). Potreba za ogromnom količinom slučajnih brojeva može rezultirati ne tako slučajnim brojevima. Ovo se može izbjeći korištenjem taktika koje su opisane u ovom radu. Potpuna slučajnost u računalnom svijetu nažalost ne postoji, ali današnji su generatori slučajnih brojeva jako blizu. 5. LiteraturaD. Eastlake 3rd, S. Crocker, J. Schiller : RFC1750 -
"Randomness Recommendations for Security", 1994. © Zavod za Elektroniku,
Mikroelektroniku, Računalne i Inteligente Sustave
|
|||||||||||||||||||||||||||||||||||||||